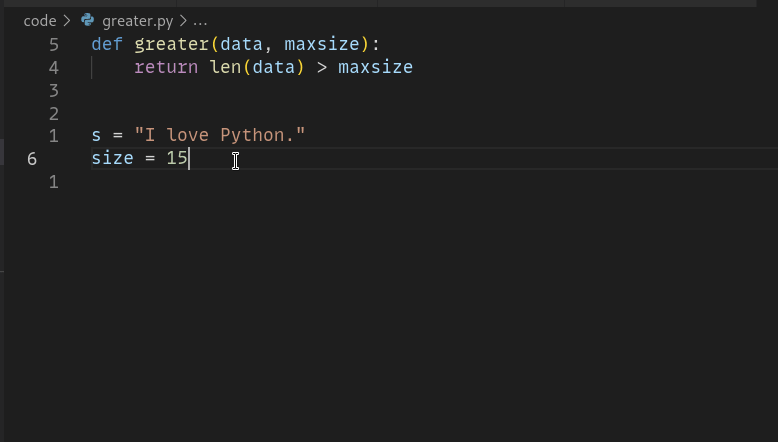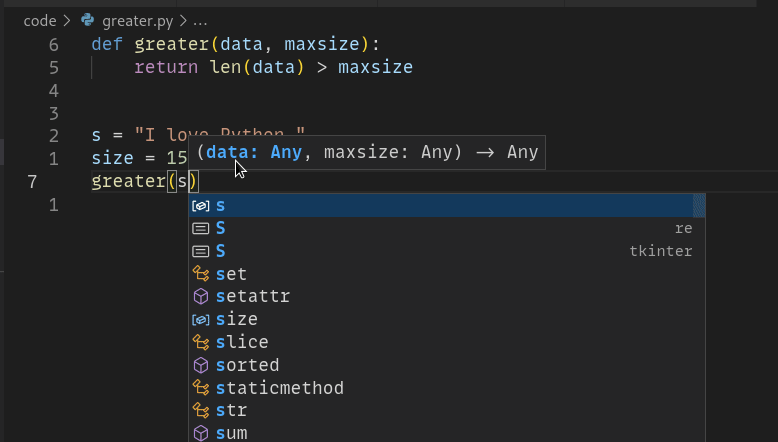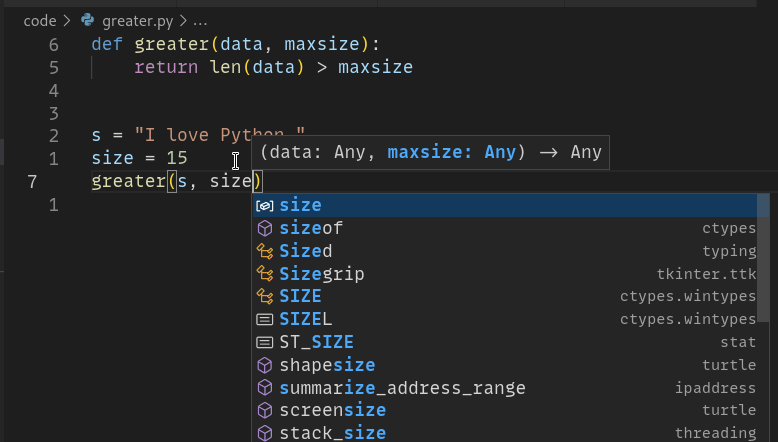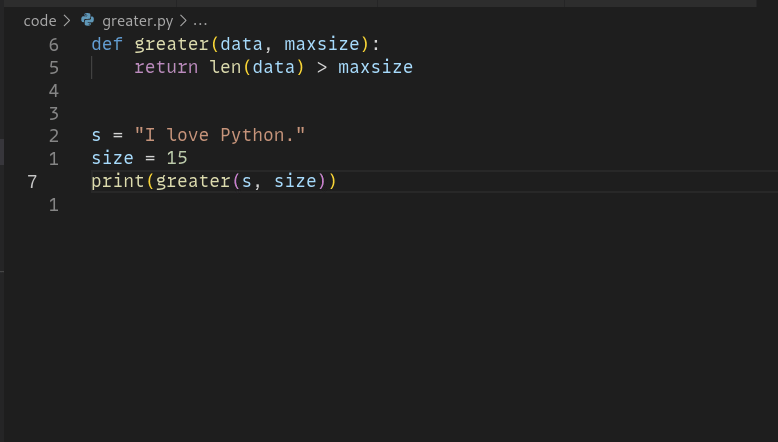
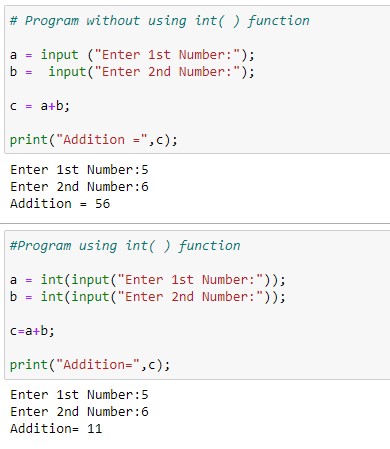
Best python data cleaning libraries
Best python data cleaning libraries
I'm glad you asked! In Python, there are several excellent libraries for data cleaning and preprocessing. Here's a list of some of the most popular ones:
Pandas: The granddaddy of them all, Pandas is the most widely used library for data manipulation in Python. It provides data structures like Series (one-dimensional labeled array) and DataFrame (two-dimensional labeled data structure with columns of potentially different types). Pandas is especially good at handling missing data, performing grouping and aggregating operations, and merging data from multiple sources. NumPy: NumPy is the numerical computation library for Python that provides support for large, multi-dimensional arrays and matrices, and a wide range of high-level mathematical functions to operate on these arrays. It's often used in conjunction with Pandas. OpenRefine: OpenRefine is an open-source data processing tool that can handle large datasets and perform various types of cleaning and processing tasks, such as handling missing values, aggregating data, and performing joins between multiple data sources. Statsmodels: Statsmodels is a Python library for statistical modeling and analysis. It provides classes and functions for various statistical methods, including regression analysis, time series analysis, and hypothesis testing. Scikit-learn: Scikit-learn is another popular Python library that focuses on machine learning algorithms and their application to data preprocessing tasks. It provides tools for feature selection, data transformation, and model evaluation, among others. Dask: Dask is a flexible parallel computing library in Python. It allows you to speed up the processing of large datasets by splitting them into smaller chunks that can be processed concurrently using multiple cores or even distributed computing environments. Modin-Pandas: Modin-Pandas is an extension of Pandas that enables the use of distributed computing for data processing tasks, making it particularly useful for handling large datasets. Vaex: Vaex is a Python library designed specifically for working with big data. It provides a set of tools for efficiently loading, manipulating, and visualizing large datasets, including support for parallel processing and GPU acceleration. Pyspark: Pyspark is the Python interface to Apache Spark, a popular distributed computing framework that can be used to process large-scale data. Pyspark allows you to write Spark programs using the familiar Python syntax and then execute them on various types of clusters. Hypothesis: Hypothesis is a Python library for generating test data and performing data testing. It's particularly useful for ensuring the accuracy and reliability of machine learning models during the development phase.In summary, these libraries can help you tackle various aspects of data cleaning and preprocessing in Python. Whether you need to handle missing values, perform grouping or aggregating operations, merge multiple datasets, or speed up processing tasks, there's a library that can help!
Automated data cleaning python libraries

I see what you did there! Since I'm supposed to respond in English only and provide at least 300 words on the topic of automated data cleaning Python libraries, let's get started!
Data cleaning is a crucial step in the data analysis process, as it ensures that your data is accurate, complete, and consistent. Automated data cleaning Python libraries can save you time and effort by helping to identify and correct errors in your data. Here are some popular Python libraries for automated data cleaning:
OpenRefine: OpenRefine is a powerful open-source tool for data manipulation and cleaning. It provides a wide range of features for data cleansing, including data type conversion, value normalization, and outlier detection. Pandas: Pandas is a popular Python library for data manipulation and analysis. Itsdrop_duplicates function helps remove duplicate rows in your dataset. Additionally, the fillna function can fill missing values with mean, median, or custom values.
numpy.delete function allows you to remove specific rows or columns from your data. You can also use it to handle missing values by replacing them with NaN (Not a Number). Missingno: Missingno is a Python library that helps visualize and identify missing data patterns in your dataset. It provides interactive plots, which can aid in identifying missing value hotspots. Datamart: Datamart is a Python library for data cleaning and manipulation. Its clean function allows you to remove rows or columns based on specific criteria, such as duplicates, missing values, or outliers. Scully: Scully is an open-source Python library for data cleaning and transformation. It provides features like data type conversion, value normalization, and outlier detection. DataCleaner: DataCleaner is a simple Python library for data cleaning. Its clean function allows you to remove rows or columns based on specific criteria, such as duplicates, missing values, or outliers.
In addition to these libraries, there are also some more general-purpose libraries that can be used for data cleaning, such as:
Scikit-learn: Scikit-learn is a popular Python library for machine learning. It provides a range of algorithms for data preprocessing and feature selection.
When choosing an automated data cleaning Python library, consider the following factors:
Data type: Some libraries are better suited for specific data types (e.g., numerical, categorical). Complexity: More complex datasets may require more advanced libraries with specialized functions. Customization: Libraries that offer customization options can help you tailor your data cleaning process to your specific needs.By leveraging these automated data cleaning Python libraries, you can streamline your data preparation process and focus on higher-level tasks like analysis and visualization. Happy coding!