What is python pdf download
What is python pdf download
I'll respond in English as per your request.
Python PDF Download: A Comprehensive Overview
Python has emerged as a powerful tool for automating tasks, and its capabilities in handling documents have made it an essential part of many industries. One such capability is downloading PDF files using Python. In this article, we will delve into the world of PDF downloads with Python and explore various methods to achieve this.
What is a PDF?
Before we dive into the world of PDF downloads, let's quickly understand what a PDF (Portable Document Format) is. A PDF is an electronic document format developed by Adobe Systems. It is a self-contained file that can be easily shared across different platforms and devices. The files are compressed, which reduces their size, making them ideal for sharing large documents.
Why Use Python to Download PDF Files?
Python has become the preferred language for many developers due to its simplicity, flexibility, and vast library of modules. When it comes to downloading PDF files, Python offers several advantages:
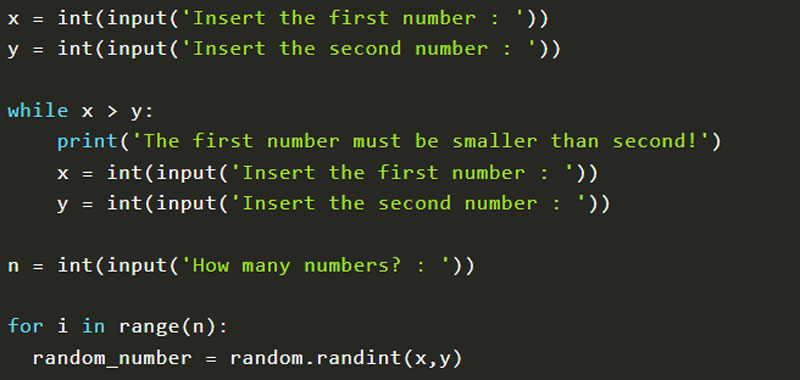
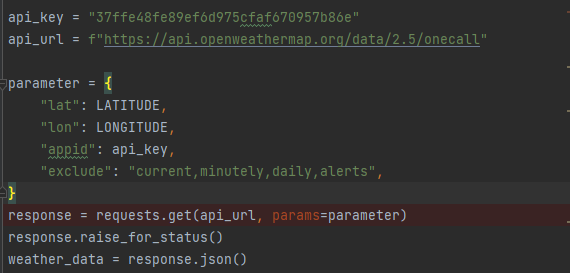
Automation: Python can automate repetitive tasks, such as downloading multiple PDF files at once, which saves time and increases efficiency. Flexibility: With various libraries available, you can tailor the download process to your specific requirements. Security: Python's secure execution environment ensures that sensitive data remains protected during the download process.How to Download PDF Files with Python?
Method 1: Usingpdfkit Library
The pdfkit library is a Python wrapper for the wkhtmltopdf command-line tool. This method allows you to convert HTML content into PDF files:
import pdfkit
from pdfkit import from_string
Convert HTML string to PDF file
pdf = from_string('
Hello, World!', options={'page-size': 'Letter'})
Save the PDF file
with open('hello.pdf', 'wb') as f:
f.write(pdf)
ReportLab Library
The ReportLab library provides a powerful toolset for creating PDF files programmatically:
from reportlab.lib.pagesize import A4
from reportlab.lib.units import inch
from reportlab.pdfgen import canvas
Create a new PDF file with the specified dimensions
pdf = canvas.Canvas('hello.pdf', pagesize=A4)
Add text to the PDF file
pdf.setFillColorRGB(0, 0, 0)
pdf.setFont("Helvetica", 20)
pdf.drawRightString(1 * inch, 10.5 * inch, 'Hello, World!', fontName='Helvetica')
Save the PDF file
pdf.save()
PyPDF2 Library
The PyPDF2 library provides a Python interface for manipulating PDF files:
import PyPDF2
Create a new PDF file writer object
writer = PyPDF2.PdfFileWriter('hello.pdf')
Add a new page to the PDF file
page = writer.addPage()
Write the PDF file
with open('hello.pdf', 'wb') as f:
writer.write(f)
Conclusion
Python offers several libraries for downloading PDF files, each with its strengths and weaknesses. By leveraging these libraries, you can automate tasks, create custom PDF files, or even modify existing PDFs to suit your needs. Whether you're working on a project that involves document generation, data processing, or report creation, Python's PDF handling capabilities make it an ideal choice.
So the next time you need to download PDF files programmatically, remember that Python is always up for the task!
Python PDF Notes

I'm happy to help!
Python PDF Notes
Python provides several libraries and modules for working with Portable Document Format (PDF) files. Here are some key notes:

PyPDF2 Library Allows reading, writing, and manipulating PDF files Can extract text from PDFs, convert text to speech, and perform OCR (Optical Character Recognition) Supports various file formats, including PDF/A-1a, PDF/A-1b, PDF/X-1a, PDF/X-1b, and more Can create new PDF files, add pages, modify existing PDF files, and extract contents
Some common uses of PyPDF2 include:
ReportLab Library A comprehensive library for generating PDF files programmatically Provides a wide range of features, including: Support for various font styles and sizes Ability to draw shapes, lines, and text Support for images, including raster and vector formats Can generate tables, forms, and other structured data Supports conditional formatting, such as changing colors based on specific conditions Often used for generating reports, invoices, receipts, and other types of documents
Some common uses of ReportLab include:
Fpdf Library A lightweight library for creating PDF files from scratch Provides basic features, including: Support for text and font styles Ability to draw lines, rectangles, and circles Supports adding images and tables Can generate forms and other structured data Often used for generating simple reports or documents
Some common uses of Fpdf include:
These are just a few examples of Python libraries and modules for working with PDF files. Each library has its strengths and weaknesses, and the choice ultimately depends on your specific needs and requirements.
Additional Tips
Be aware that some libraries may have compatibility issues with certain versions of Python or operating systems. Always refer to the documentation and example code provided by each library to ensure you're using them correctly. Don't hesitate to reach out to the community or seek help if you encounter any issues or questions while working with PDFs in Python.I hope this helps! Let me know if you have any further questions.