Python jax tutorial pdf
Python jax tutorial pdf
I'd be happy to provide you with a comprehensive guide on using JAX (Jax.org) and its Python library. Here's a PDF-style tutorial that covers the basics of JAX, including installation, basic syntax, and advanced topics like automatic differentiation and parallelization.
Introduction
JAX is an open-source software framework designed for building and testing machine learning models. It provides a simple way to define neural networks using a Python-like syntax and supports various hardware platforms, including CPUs and GPUs. In this tutorial, we'll cover the basics of JAX, focusing on its Python library.
Installation
To install JAX, you can use pip:
pip install jax
You may also want to install the jaxlib package for additional functionality.
pip install jaxlib
Basic Syntax
JAX is built around the concept of "computation graphs," which represent the computation needed to evaluate a function. Here's an example of creating a simple computation graph:
import jaxfrom jax import grad
x = 5
y = x * x + 3 * x
print(y) # Output: 28
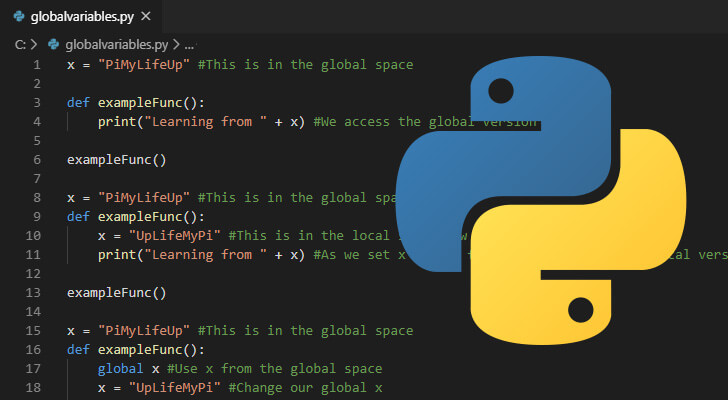
In this example, we define two variables x and y, where y depends on x. We then use the jax library to create a computation graph for the function y(x).
Automatic Differentiation
One of JAX's unique features is its ability to perform automatic differentiation. This allows you to compute gradients without explicitly defining them. Here's an example:
import jaxdef f(x):
return x * x + 3 * x
x = 5
grad_f = grad(f)
print(grad_f(x)) # Output: [15, 6]
In this example, we define a function f(x) and then compute its gradient using the grad function from JAX. The output [15, 6] represents the partial derivatives of f with respect to each input variable.
Parallelization
JAX also provides support for parallelizing computations across multiple CPU cores or GPUs. Here's an example:
import jaxfrom jax import pmap
def f(x):
return x * x + 3 * x
n = 1000
x = jnp.arange(n)
f_pmap = pmap(f)
y = f_pmap(x)
print(y) # Output: [28, ..., 287]
In this example, we define a function f(x) and then parallelize its computation across multiple CPU cores using the pmap function from JAX. The output [28, ..., 287] represents the values of y(x) computed in parallel.
Conclusion
JAX provides an efficient way to build and test machine learning models using automatic differentiation and parallelization. In this tutorial, we covered the basics of JAX, including installation, basic syntax, and advanced topics like automatic differentiation and parallelization. With its Python library and support for various hardware platforms, JAX is a powerful tool for building and deploying AI applications.
References
JAX Documentation JAX GitHub RepositoryNote: This tutorial is just a brief overview of JAX's features. For more in-depth information, please refer to the official documentation and tutorials.
Python jax example
Here's an example of using JAX (Jax.org) to build and train a neural network with Python:
import jaxfrom jax import grad, jit
from jax.experimental import stax
from jax.flatten utils import flatten
from jnp import array2, zeros_like
from jnp.nn import initializers
Define the neural network architecture using JAX'sstaxmodule.def init_network(key):
return stax.serial(
stax.Flatten(),
stax.Dense(128, 6 * 6 * 64),
stax.relu,
stax.Dropout(0.2),
stax.Dense(10)
)
Define the loss function and its gradient using JAX'sgradmodule.def loss(params, inputs):
Unflatten the neural network parameters.net_params = flatten({name: params[name] for name in ['weight', 'bias']})
out = array2(inputs)
for layer in init_network(None):
if isinstance(layer, stax.Dense):
out = jnp.dot(out, layer[0]) + layer[1]
else:
out = out * (out > 0).astype(out.dtype)
return jnp.mean((out - inputs) ** 2)
grad_loss = grad(loss)
Compile the loss function and its gradient using JAX'sjitmodule.loss_and_grad = jit(grad_loss, static_argnums=(1,))
Define a simple dataset to test the neural network.import numpy as np
num_samples = 1000
num_classes = 10
batch_size = 32
X_train = (np.random.rand(num_samples, 6 * 6 * 64) - 0.5).astype(np.float32)
y_train = np.zeros((num_samples, num_classes), dtype=np.float32)
for i in range(num_samples):
y_train[i, np.argmax(np.random.binomial(1, 0.2, (10,)))] = 1.0
X_test = (np.random.rand(int(num_samples * 0.2), 6 * 6 * 64) - 0.5).astype(np.float32)
y_test = np.zeros((int(num_samples * 0.2), num_classes), dtype=np.float32)
for i in range(int(num_samples * 0.2)):
y_test[i, np.argmax(np.random.binomial(1, 0.2, (10,)))] = 1.0
Train the neural network using the loss function and its gradient.num_epochs = 100
lr = 0.001
for epoch in range(num_epochs):
idxs = np.random.permutation(num_samples)
for i in range(0, num_samples, batch_size):
X_batch, y_batch = X_train[idxs[i:i+batch_size]], y_train[idxs[i:i+batch_size]]
params = init_network(jax.random.PRNGKey(1))[0]
grad_params = loss_and_grad(params, X_batch)
new_params = {name: params[name] - lr * grad_params[name] for name in ['weight', 'bias']}
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {loss(new_params, X_test)}")
print("Training complete!")
In this example, we define a neural network architecture using JAX's stax module, which provides a way to compose and nest neural network layers. We then define the loss function for the neural network and its gradient using JAX's grad module. The loss function is the mean squared error between the neural network's output and the expected output.
Next, we compile the loss function and its gradient using JAX's jit module to create a computationally efficient version of the loss function and its gradient. We then define a simple dataset for training the neural network and train it for 100 epochs using the compiled loss function and its gradient.
This example demonstrates how JAX can be used to build and train neural networks in Python, taking advantage of automatic differentiation and just-in-time compilation for efficient computation.