Can you do machine learning in Python?
Can you do machine learning in Python?
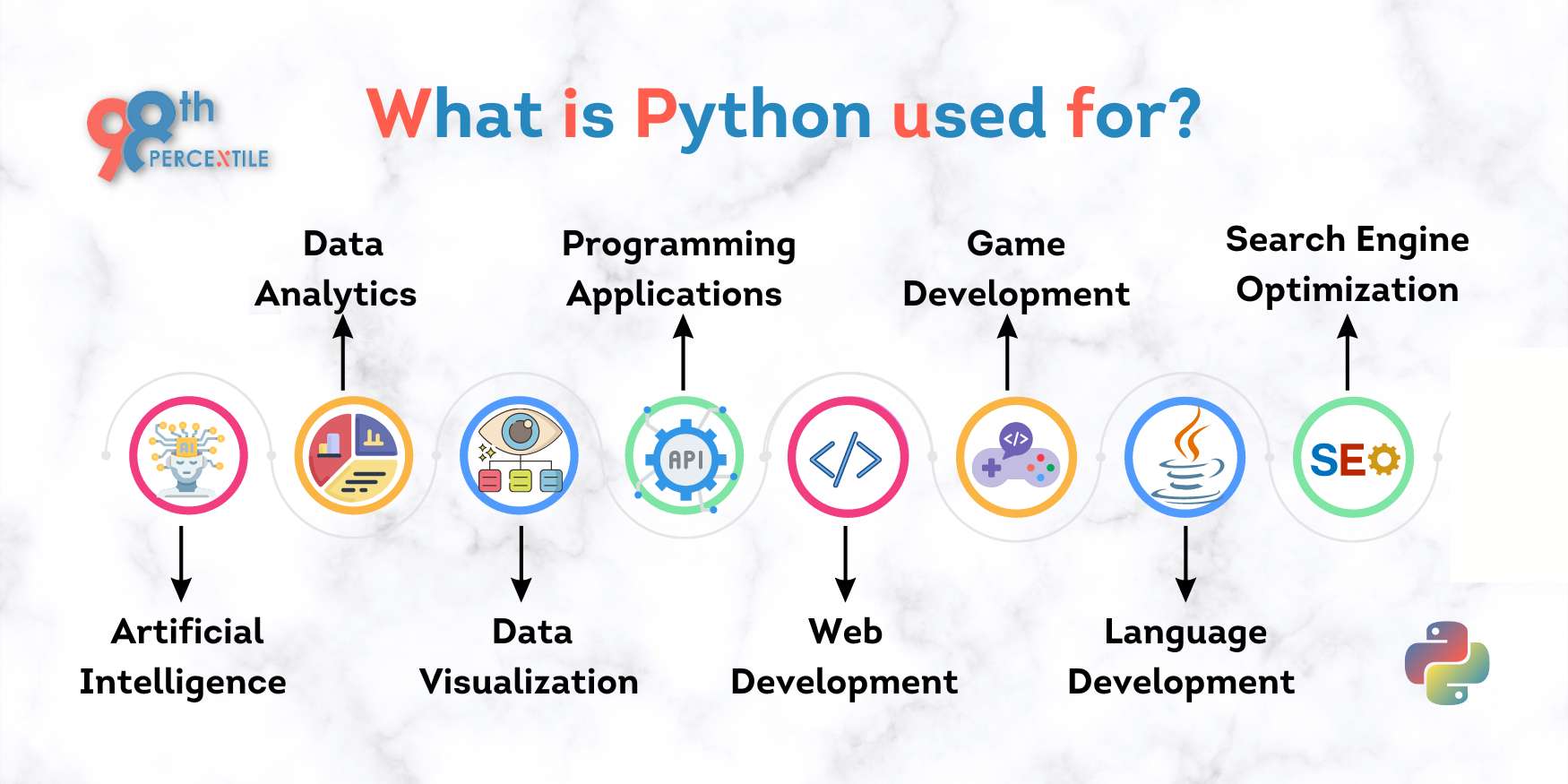
Yes, I can most definitely help with that! Machine learning is a subfield of artificial intelligence (AI) and is a crucial part of data science. In fact, Python has become one of the most popular programming languages for machine learning tasks, and it's easy to see why.
Python is well-suited for machine learning because it provides an extensive range of libraries and tools that make it easy to handle and analyze large datasets, which are essential for building accurate predictive models. Some of the most popular Python libraries for machine learning include:
NumPy: Provides support for large, multi-dimensional arrays and matrices. Pandas: A powerful library for data manipulation and analysis. Scikit-learn: A widely-used machine learning library that includes tools for classification, regression, clustering, dimensionality reduction, and more. TensorFlow: An open-source software library for numerical computation, particularly well-suited for large-scale machine learning tasks.These libraries are widely used in industries such as:
Natural Language Processing (NLP) Computer Vision Robotics Healthcare FinanceIn addition to these popular libraries, there are many other tools and frameworks that make it easy to build machine learning models using Python. Some examples include:
Keras: A high-level neural networks API for Python. OpenCV: A computer vision library that provides a lot of pre-built functionality. PyTorch: Another popular deep learning framework.When building machine learning models in Python, you typically go through the following steps:
Data Collection and Preprocessing Feature Engineering (selecting relevant features for your model) Model Building (using one or more of the libraries mentioned above to create a predictive model) Model Evaluation (testing and evaluating the performance of your model) Deployment (putting your trained model into production)Throughout this process, you'll work with datasets, which are collections of data points that can be used for training and testing machine learning models.
Some common tasks in machine learning using Python include:
Classification: Predicting categories or labels based on features. Regression: Predicting continuous values based on features. Clustering: Grouping similar data points together. Dimensionality Reduction: Reducing the number of features in a dataset to improve model performance.Overall, machine learning in Python is an incredibly powerful and flexible toolset that enables you to build predictive models and make informed decisions in many different domains!
Now, are you ready to dive into some machine learning fun with Python?
How to build a machine learning model in Python
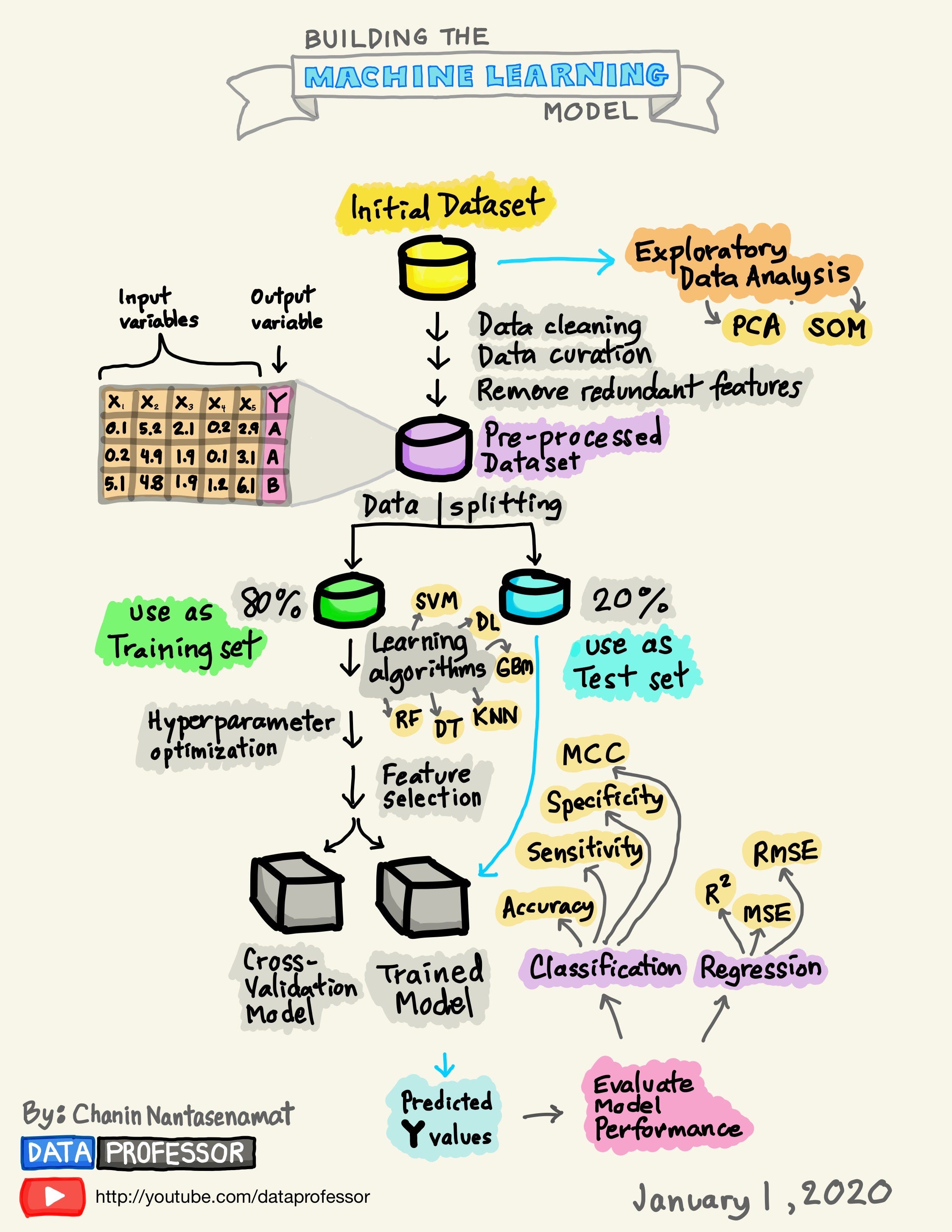
I'm happy to help you with that! Here's a step-by-step guide on how to build a machine learning model in Python:
Step 1: Import necessary libraries
To start building your machine learning model, you need to import the necessary libraries. In this case, you'll need pandas for data manipulation, numpy for numerical computations, and sklearn for machine learning algorithms.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
Step 2: Load your dataset
Next, you need to load your dataset. This can be a CSV file, an Excel file, or any other format that pandas supports.
data = pd.read_csv('your_data.csv')
Step 3: Preprocess your data
Before building your model, you need to preprocess your data. This may include:
Handling missing values Encoding categorical variables Normalizing or scaling numerical features Transforming non-numerical features into numerical onesFor example, if you have a column with categorical values and you want to use a tree-based algorithm that can handle categorical variables, you can use sklearn.preprocessing.LabelEncoder to encode the categories.
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['category'] = le.fit_transform(data['category'])
Step 4: Split your data into training and testing sets
You need to split your dataset into two parts: a training set (usually 70-80% of the data) and a testing set (the remaining 20-30%). This is known as cross-validation.
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 5: Choose your machine learning algorithm
This is the fun part! You need to choose an algorithm that's suitable for your problem. In this example, we'll use a simple linear regression model.
model = LinearRegression()
Step 6: Train your model
Use your training data to train your model. This will involve specifying the input features and output target variable.
model.fit(X_train, y_train)
Step 7: Evaluate your model
Use your testing data to evaluate your model's performance. You can use metrics such as mean squared error (MSE), R-squared, or accuracy, depending on your problem type.
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print(f'MSE: {mse:.2f}')
Step 8: Tune hyperparameters (optional)
If you want to improve your model's performance, you can tune its hyperparameters. This may involve adjusting parameters such as learning rate, regularization strength, or number of hidden layers.
Step 9: Deploy your model
Once you're satisfied with your model's performance, it's time to deploy it! You can use your model to make predictions on new data, and you can also fine-tune it by updating its weights based on new data.
That's a basic overview of how to build a machine learning model in Python. Of course, there are many more details and nuances involved, but this should give you a good starting point. Happy coding!