Which Python version for Transformers?
Which Python version for Transformers?

I'm glad you asked! The choice of Python version for using the Transformers library depends on several factors, including your project's requirements, personal preference, and compatibility with other dependencies.
The original Transformer model was introduced by Vaswani et al. in 2017, and at that time, Python 3.5 was the dominant version. The initial implementation of the Transformer model was done using the Keras deep learning library on top of TensorFlow 1.x.
In recent years, the Transformers library has evolved to support multiple Python versions. Here are some key points to consider:
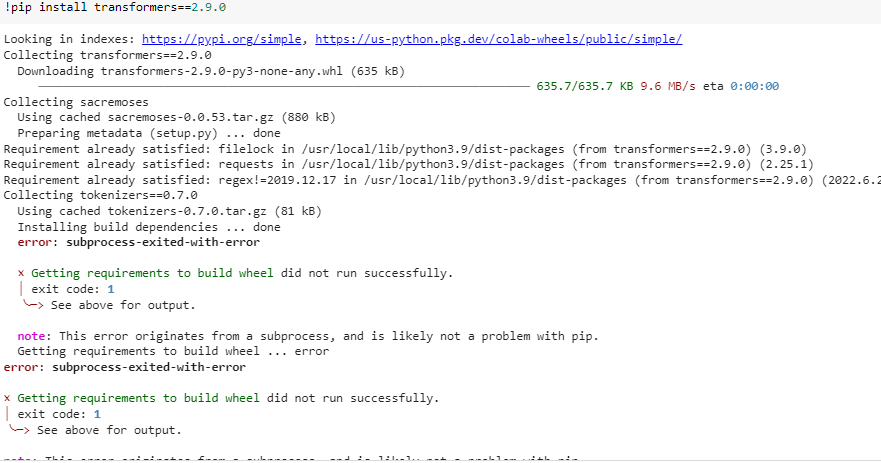
Python 3.6+: This is the recommended version for running the Transformers library. Many important dependencies, such as PyTorch and TensorFlow, also support this version. You can expect smooth performance with most models and features.
Python 3.5: Although Python 3.5 is no longer the dominant version, you might still be using it due to compatibility issues or legacy projects. The Transformers library does support Python 3.5, but keep in mind that some dependencies might not work seamlessly.
Python 2.x: Unfortunately, Python 2.x is no longer supported by the Transformers library. If your project still relies on Python 2.x, I strongly recommend migrating to a newer version (at least Python 3.6) for better performance and security.

Some additional considerations:
CPU/GPU support: For large-scale computations or GPU acceleration, you might want to use Python 3.7+ to leverage more efficient libraries like PyTorch 1.x. Compatibility with other dependencies: If your project involves other libraries or frameworks (e.g., scikit-learn, NumPy, pandas), ensure that they also support the chosen Python version.In conclusion, if you're starting a new project or upgrading an existing one, I recommend using Python 3.6+ for seamless compatibility and performance with the Transformers library. If your specific requirements dictate sticking to Python 3.5, you can still use it, but be aware of potential issues with dependencies.
Python transformers list github
Here's an overview of how to use Python Transformers library to work with lists on GitHub:
What is the Transformers Library?
The Transformers library, written by Hugging Face, provides a wide range of pre-trained models that can be used for various NLP tasks such as language translation, sentiment analysis, and text generation. The library is designed to make it easy to integrate these pre-trained models into your Python applications.
What are Lists in GitHub?
GitHub lists are collections of items, similar to arrays or lists in other programming languages. They can contain any type of item that is supported by GitHub, such as repositories, users, teams, or issues. GitHub lists provide a convenient way to organize and manage related items.
Using the Transformers Library with Lists on GitHub
Here's an example of how you could use the Transformers library to work with lists on GitHub:
First, make sure you have Python 3.8 or later installed on your machine. You will also need to install the transformers library using pip:
pip install transformers
Next, import the necessary libraries and authenticate with GitHub:
import os
import requests
from transformers import pipeline
Set up authentication for GitHub API
client_id = "your_client_id"
client_secret = "your_client_secret"
auth_token = requests.post(f"https://api.github.com/oauth/token",
headers={"Accept": "application/vnd.github.v3+json"},
data={"client_id": client_id,
"client_secret": client_secret,
"grant_type": "client_credentials"}).json()["access_token"]
Use the authentication token to make API requests
headers = {"Authorization": f"Bearer {auth_token}",
"Accept": "application/vnd.github.v3+json"}
Get a list of repositories for a user
user_name = "your_user_name"
repositories_url = f"https://api.github.com/users/{user_name}/repos"
response = requests.get(repositories_url, headers=headers)
repositories = response.json()
print("Repositories:")
for repository in repositories:
print(repository["name"])
Use the Transformers library to analyze text from a repository
repository_name = "your_repository_name"
text_analysis_pipeline = pipeline("text-classification")
response = requests.get(f"https://api.github.com/repos/{user_name}/{repository_name}/contents/path/to/file.txt",
headers=headers)
file_text = response.content.decode()
analysis_result = text_analysis_pipeline(file_text)
print("Analysis Result:", analysis_result[0]["label"])
In this example, we first authenticate with the GitHub API using a client ID and secret. Then, we use the API to retrieve a list of repositories for a given user. We can then analyze the text from one of those repositories using the Transformers library.
Conclusion
The Transformers library provides a powerful set of tools for natural language processing tasks in Python. By integrating it with GitHub lists, you can unlock new possibilities for analyzing and manipulating data on the platform. This example demonstrates how to use the library to analyze text from a repository and retrieve a list of repositories for a given user.
Please note that this is just an example code snippet, and you will need to adapt it to your specific use case.