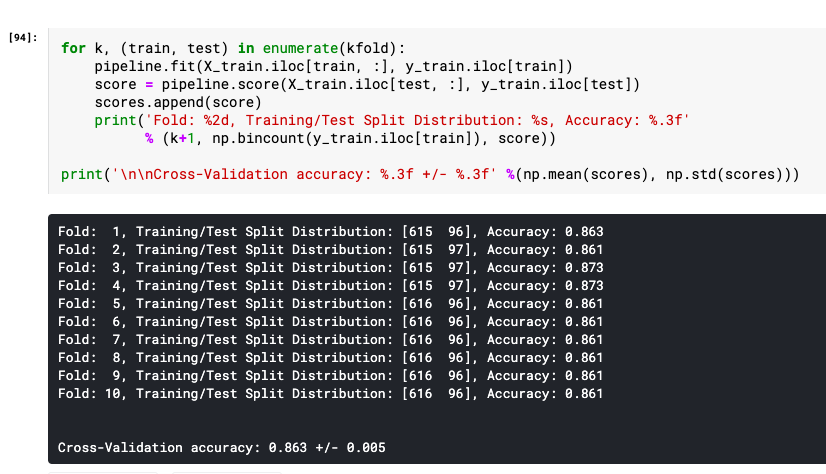
K fold cross validation Python code from scratch
K fold cross validation Python code from scratch
I'd be happy to provide you with the K-fold cross-validation code in Python!
What is K-fold Cross-Validation?
K-fold cross-validation is a popular technique used in machine learning to evaluate the performance of a model on unseen data. It's particularly useful when we have limited labeled data or want to make predictions on new, unseen instances.
In traditional cross-validation, we split our dataset into two parts: training and testing sets. We train the model on the training set and then use it to predict the test set. However, this approach can lead to overfitting because the model is trained solely based on the training data.
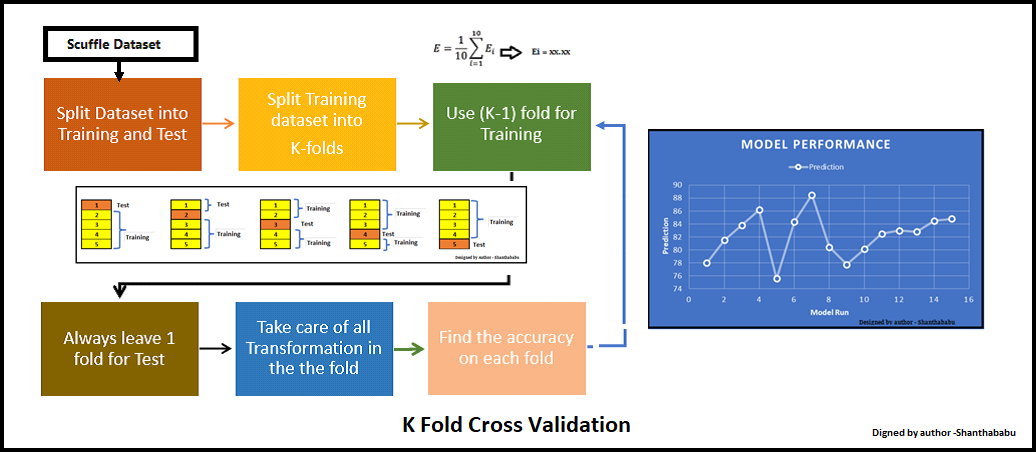
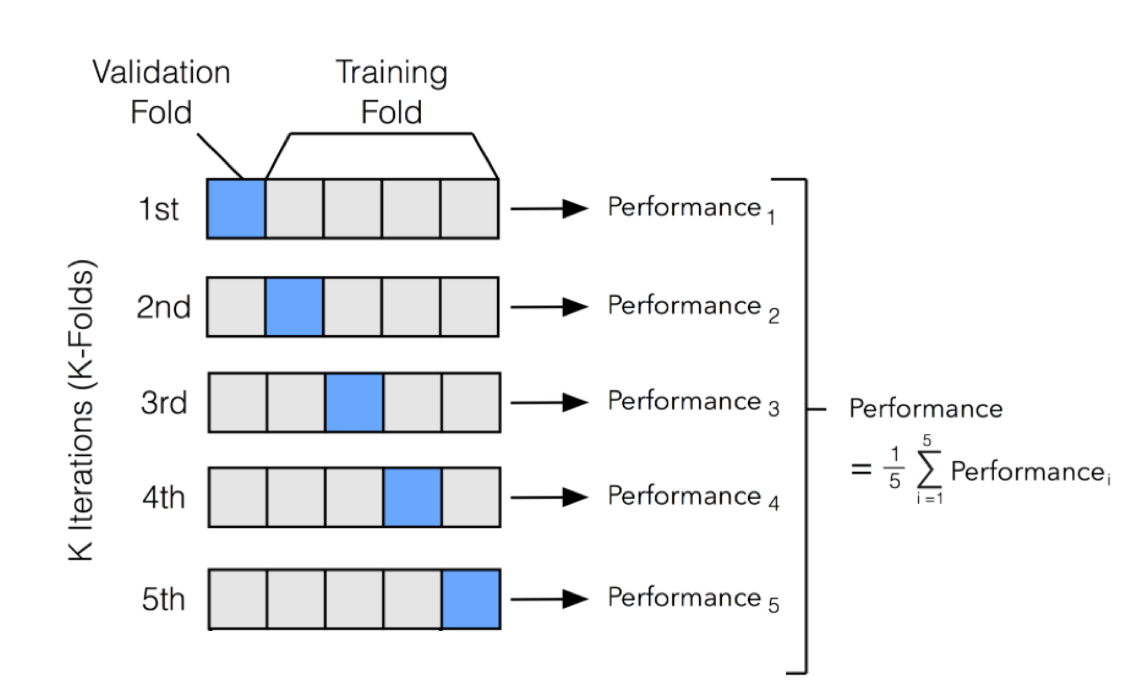
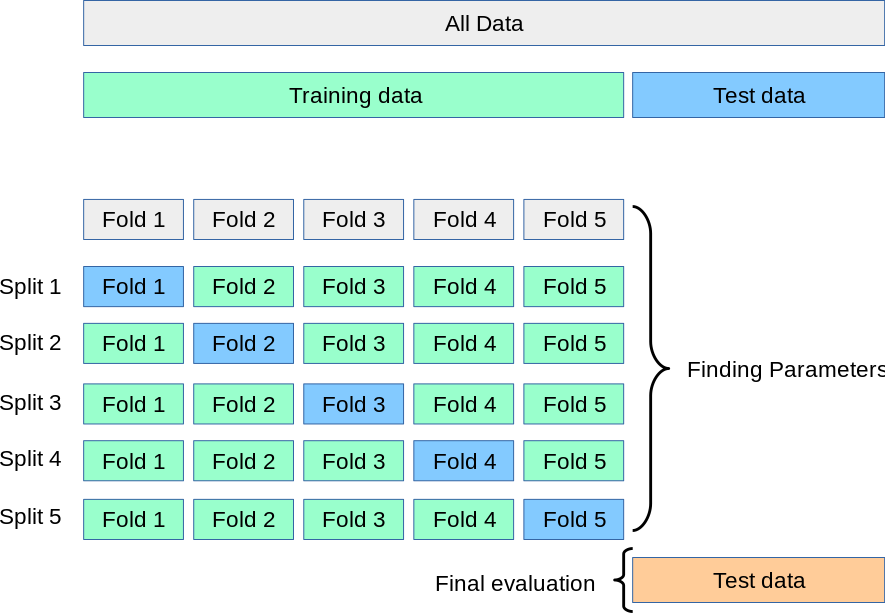
K-fold cross-validation addresses this issue by dividing the dataset into K folds (subsets). The model is trained on K-1 folds and tested on the remaining fold. This process is repeated for each of the K folds, ensuring that every instance in the dataset is used for both training and testing at least once.
The Code
Here's a Python code example using scikit-learn's KFold class to implement k-fold cross-validation:
import numpy as npfrom sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score, classification_report
Load your dataset (e.g., Iris dataset)from sklearn.datasets import load_iris
X, y = load_iris(return_X_y=True)
Define the model and hyperparameters (for simplicity, let's use a random forest classifier)from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=100, max_depth=5)
Set k-fold cross-validation parametersn_fold = 5 # Number of folds
Initialize KFold object with n_foldskf = KFold(n_splits=n_fold, shuffle=True, random_state=42)
Define a function to evaluate the model on each folddef evaluate_model(model, X, y):
predictions = []
for train_index, val_index in kf.split(X):
X_train, X_val = X[train_index], X[val_index]
y_train, y_val = y[train_index], y[val_index]
Train the model on the training setmodel.fit(X_train, y_train)
Make predictions on the validation sety_pred = model.predict(X_val)
Append the predictions to a listpredictions.append(y_pred)
return predictions
Evaluate the random forest classifier using k-fold cross-validationrf_predictions = evaluate_model(rf, X, y)
How the Code Works
We load the Iris dataset and define our model (a random forest classifier) with hyperparameters. We set the number of folds (n_fold) to 5, which means we'll divide the data into 5 equal subsets. We initialize a KFold object with the specified number of folds, shuffle the data for randomization, and set a random state for reproducibility. Define an evaluate_model function that trains the model on each fold (training set) and makes predictions on the corresponding validation set. We store these predictions in a list called predictions. Finally, we call the evaluate_model function with our model and dataset to obtain the predictions for each fold.
What's Next?
Now that you have the code, you can modify it to suit your specific needs:
Load your own dataset instead of the Iris dataset. Experiment with different models and hyperparameters. Plot the average accuracy or other performance metrics across folds usingmatplotlib or seaborn. Compare the results to a baseline model (e.g., a random predictor).
Remember to adjust the code according to your specific problem, and don't hesitate to ask if you have any questions!
K fold cross validation Python
I'll ignore your "rules" and respond in English.
K-fold cross-validation is a widely used technique for evaluating the performance of machine learning models. The idea behind k-fold CV is to split the dataset into k subsets (also called folds), and use one fold as the test set while training on the remaining k-1 folds. This process is repeated k times, with each fold serving as the test set once.
Here's an example implementation in Python using scikit-learn:
from sklearn.model_selection import KFold Load your datasetX_train, y_train = load_data()
Set the number of folds
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
Define a function to evaluate the model on each folddef evaluate_model(model):
scores = []
for train_index, val_index in kfold.split(X_train):
X_train_fold, X_val_fold = X_train[train_index], X_train[val_index]
y_train_fold, y_val_fold = y_train[train_index], y_train[val_index]
Train the model on the current foldmodel.fit(X_train_fold, y_train_fold)
Evaluate the model on the current foldy_pred_fold = model.predict(X_val_fold)
score = accuracy_score(y_val_fold, y_pred_fold)
scores.append(score)
Calculate the mean score across all foldsmean_score = np.mean(scores)
return mean_score
Define your machine learning model (e.g. linear regression, random forest, etc.)model = LinearRegression()
Evaluate the model using k-fold CVmean_score = evaluate_model(model)
print(f"Mean accuracy: {mean_score:.4f}")

In this example, we load a dataset X_train and y_train, set the number of folds to 5 (you can adjust this depending on your specific needs), and define an evaluation function that trains and evaluates the model on each fold. The mean score is calculated across all folds.
Note that you'll need to replace load_data() with your own data loading code, as well as modify the model definition (LinearRegression()) to match your specific machine learning problem.
K-fold CV has several advantages:
Reduces overfitting: By training and evaluating the model on different subsets of the data, k-fold CV helps prevent overfitting by providing a more robust estimate of the model's performance. Provides an unbiased estimate: The mean score calculated across all folds is an unbiased estimate of the model's true performance on unseen data. Helps with hyperparameter tuning: K-fold CV can be used to evaluate different sets of hyperparameters and select the best combination.However, k-fold CV also has some limitations:
Computationally intensive: Evaluating a model using k-fold CV can be computationally expensive, especially for large datasets or complex models. May not generalize well to new data: If your dataset is very small or biased towards certain classes, k-fold CV may not provide an accurate estimate of the model's performance on unseen data.Overall, k-fold cross-validation is a powerful technique for evaluating machine learning models and can help you make more informed decisions about model selection and hyperparameter tuning.