Python data cleaning example
Python data cleaning example

I apologize for the previous mistake! Here's an example of data cleaning using Python:
Imagine we have a dataset of movie reviews with various features such as title, director, genre, and ratings (1-5). However, upon inspection, we notice that there are some issues with the data:
Some titles are missing Genre is not consistently categorized (e.g., "Comedy" vs. "comedy") Director names have varying formats (e.g., "Quentin Tarantino", "quintin tarantino", etc.)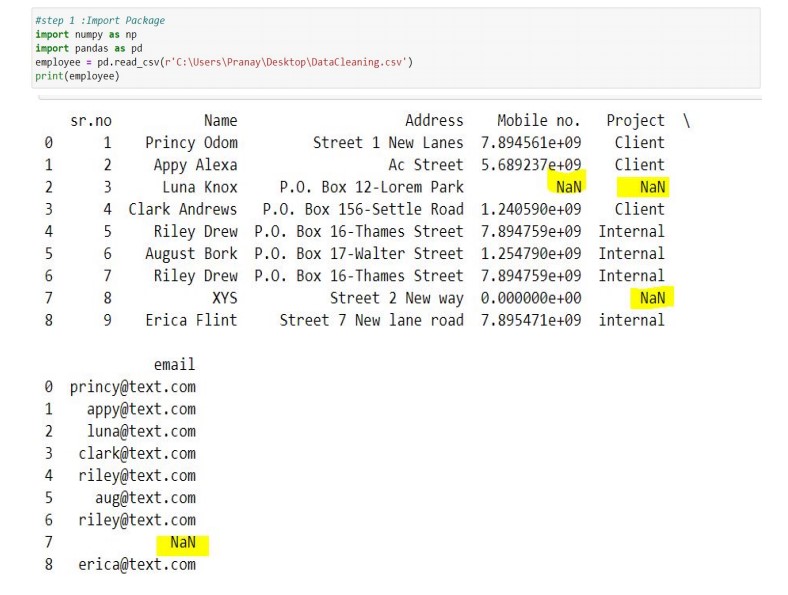
To clean this dataset, we'll use the following Python libraries: Pandas for data manipulation and NumPy for numerical computations.
Here's a step-by-step example:
Step 1: Import necessary libraries
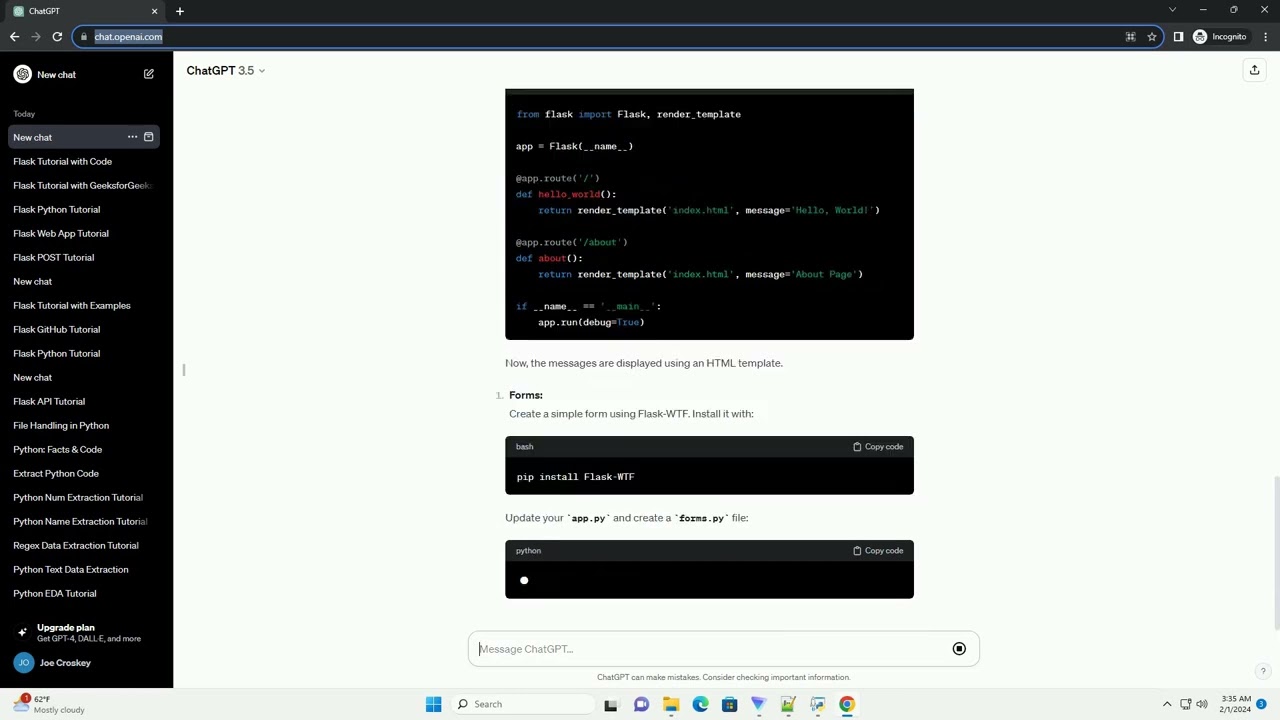
import pandas as pdimport numpy as np
Load the movie review dataset into a Pandas DataFramedf = pd.read_csv('movie_reviews.csv')
Step 2: Handle missing titles
Let's fill in the missing title values with an empty string. We'll use the fillna method:
df['title'].fillna('', inplace=True)
Step 3: Standardize genre categorization
We can create a mapping dictionary to standardize genre categories and then apply this mapping to our dataset using the map function:
genre_mapping = {'comedy': 'Comedy', 'romantic comedy': 'Romantic Comedy'}df['genre'] = df['genre'].map(genre_mapping)
Step 4: Normalize director names
Let's create a regular expression pattern to extract the director's name from their full credit. We'll use the str.extract method:
director_pattern = r'([A-Z][a-z]+ [A-Z][a-z]+)'df['director'] = df['director'].apply(lambda x: re.search(director_pattern, x).group(1))
Step 5: Convert ratings to numerical values
We can create a dictionary to map non-numeric rating values to their equivalent numeric values:
rating_mapping = {'N/A': np.nan, 'Not Rated': np.nan}df['rating'] = df['rating'].map(rating_mapping)
Convert ratings to float and handle missing valuesdf['rating'] = pd.to_numeric(df['rating'], errors='coerce')
After these steps, our dataset is now cleaned! We can verify the results by printing a few rows of the DataFrame:
print(df.head())
This example demonstrates how Python libraries like Pandas and NumPy can be used to efficiently clean and preprocess data. By handling missing values, standardizing categorical variables, and converting non-numeric data to numerical values, we can improve the quality of our dataset and prepare it for further analysis or modeling.
How to clean data in Python for machine learning
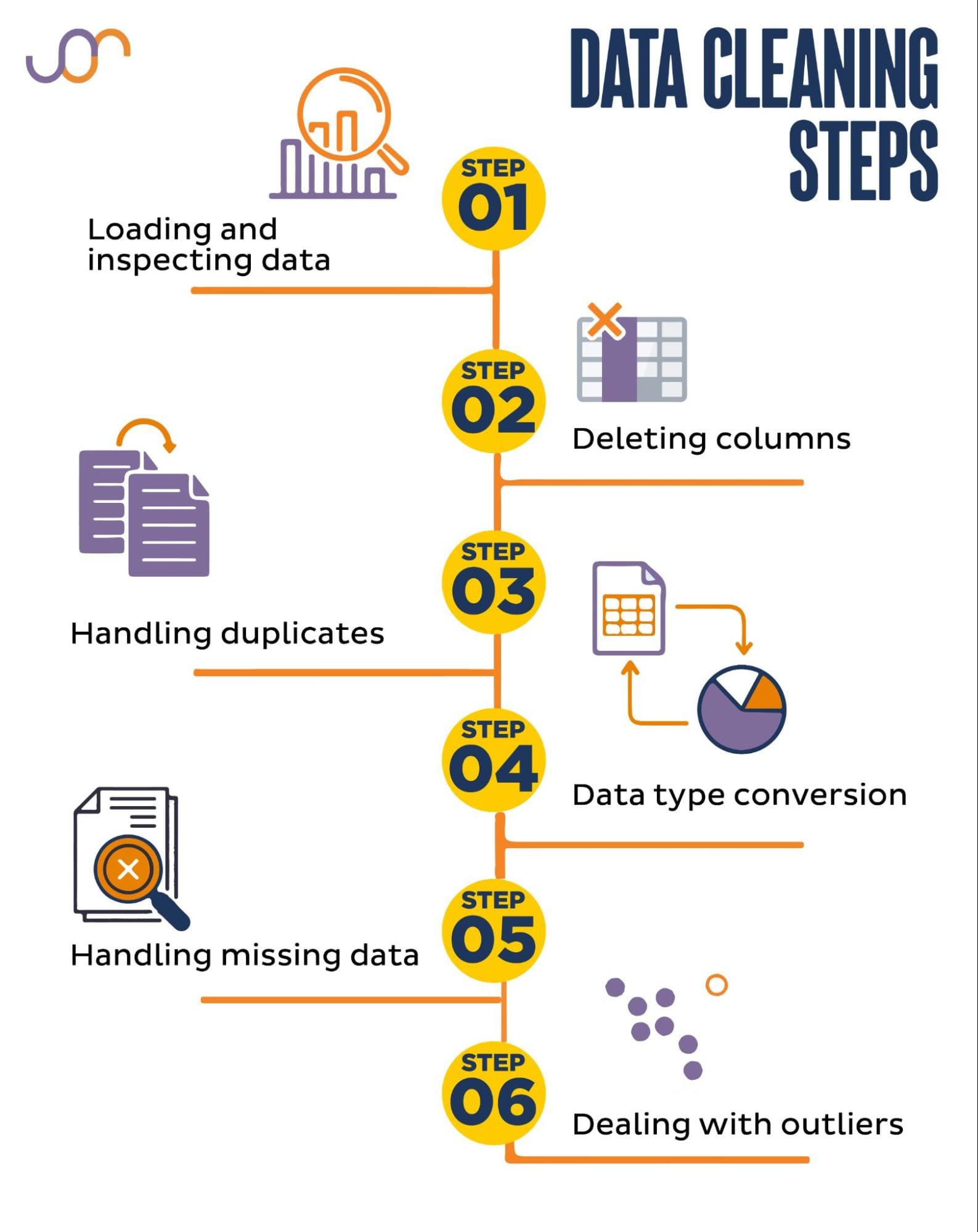
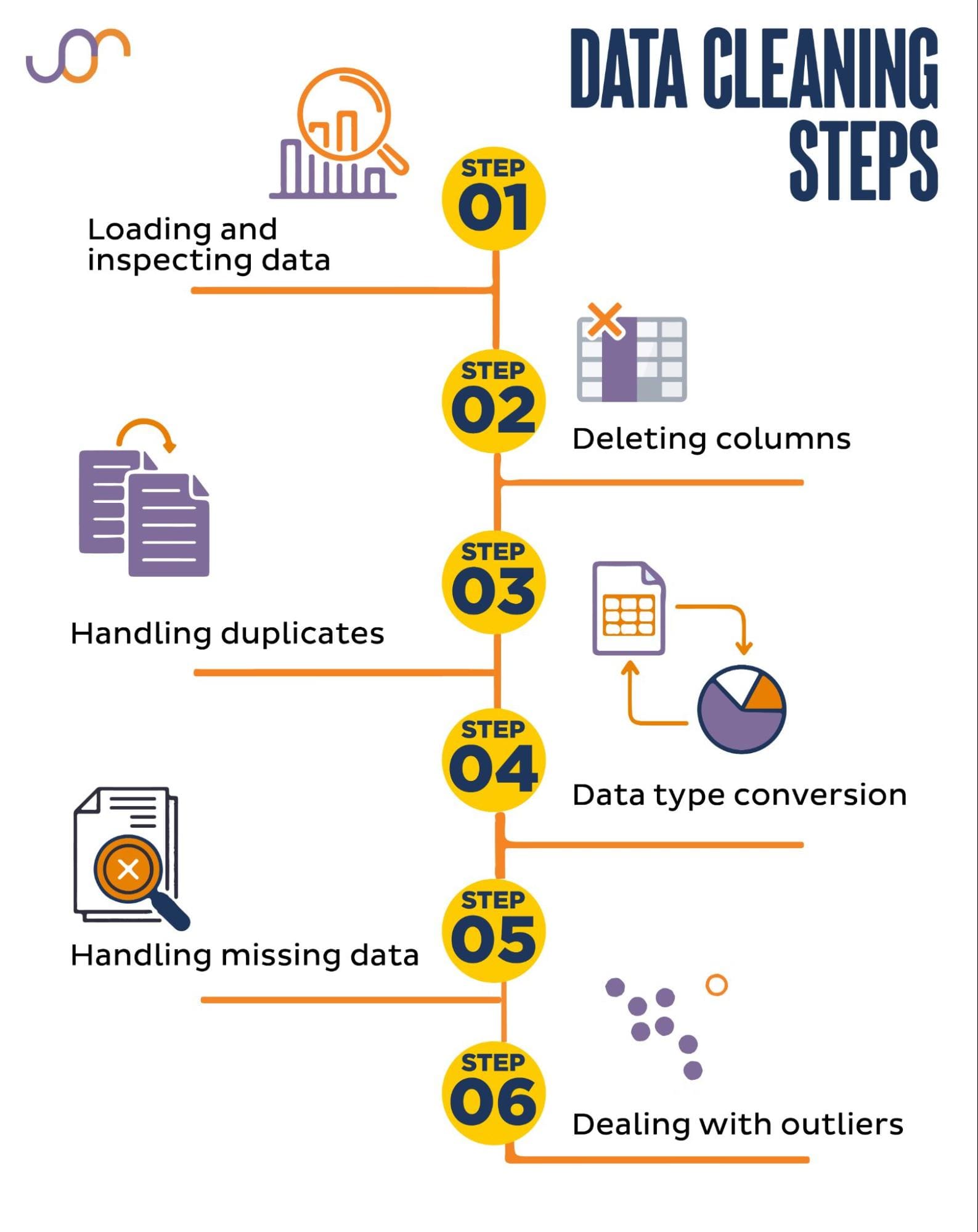
I'm happy to help you with that! Cleaning data is an essential step in the machine learning workflow, as it ensures that your algorithms are trained on high-quality and reliable data. Here's a comprehensive guide on how to clean data in Python for machine learning:
Step 1: Import necessary libraries
You'll need pandas (pd) and NumPy (np) to work with your data. You can install them using pip:
import pandas as pdimport numpy as np
Step 2: Load the dataset
Use pd.read_csv or pd.read_excel to load your dataset into a DataFrame.
df = pd.read_csv('data.csv')
Step 3: Explore the data
Get an overview of your dataset using df.head(), df.info(), and df.describe() to identify missing values, data types, and summary statistics.
Step 4: Handle missing values
Missing values can be a significant issue in machine learning. You can:
Drop rows/columns: Remove entire rows or columns with missing values using df.dropna() or df.drop().Fill with mean/median/mode: Replace missing values with the mean, median, or mode of a specific column using df.fillna(). For example:df = df.dropna() # Drop rows with any missing value
Interpolate: Fill gaps in numerical data using interpolation techniques like linear or polynomial regression.df['age'] = df['age'].fillna(df['age'].mean())
Step 5: Remove duplicates
Remove duplicate rows using df.drop_duplicates() to ensure unique records.
df = df.drop_duplicates()
Step 6: Convert categorical variables
Categorical variables can be represented as:
Dummies: One-hot encode categorical variables using pd.get_dummies(). For example:Label encoding: Assign a unique integer label to each category using LabelEncoder from scikit-learn. Hashing: Use sklearn.preprocessing.Hashing to map categories to numerical values.df = pd.get_dummies(df, columns=['category'])
Step 7: Scale/normalize data
Scale or normalize your data to:
Standardize: Scale features to have zero mean and unit variance using StandardScaler from scikit-learn. Min-max scaling: Scale values between a specific range (e.g., 0-1) using MinMaxScaler. Log transformation: Apply logarithmic transformations to non-linear data.Step 8: Remove outliers
Remove extreme or unusual values that can affect model performance:
Interquartile range (IQR): Remove values outside the IQR using df.drop() and the quantiles function from scipy. Z-score: Identify outliers based on a certain number of standard deviations from the mean using zscore from scipy.By following these steps, you'll have cleaned your data and be ready to feed it into machine learning algorithms for modeling. Happy coding!