Parallel processing in Python example
Parallel processing in Python example

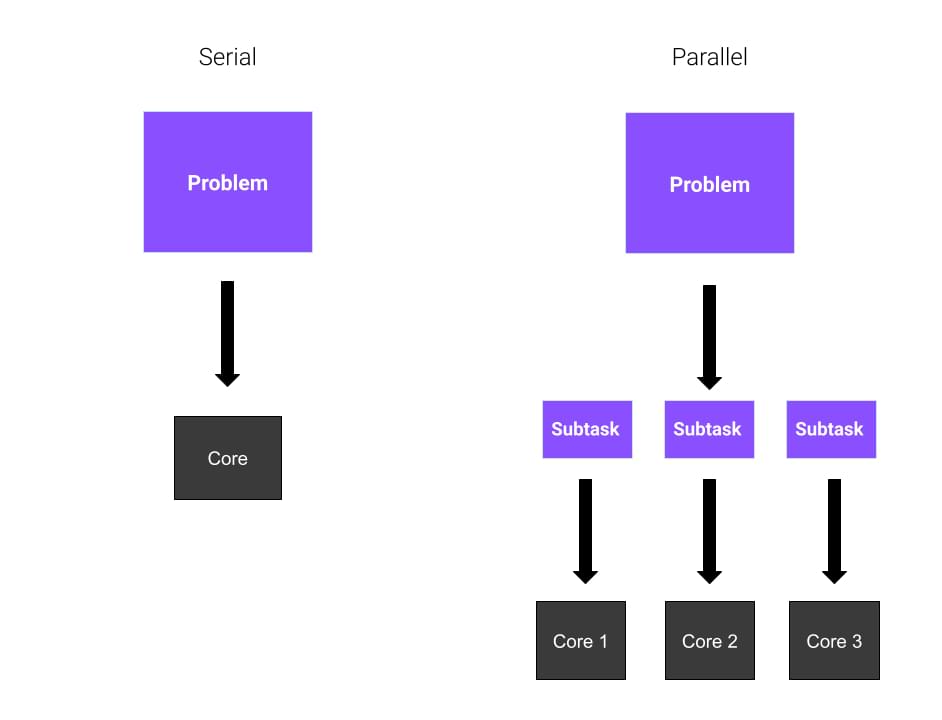
Here's an example of parallel processing in Python using the multiprocessing module:
import multiprocessing
import time
import os
def process_func(num):
print(f"Process {num} is running")
for i in range(5):
print(f"Process {num} is doing some work...")
time.sleep(1)
print(f"Process {num} has finished")
Create a pool of 4 worker processes
pool = multiprocessing.Pool(processes=4)
Start the processes
results = [pool.apply_async(process_func, (i,)) for i in range(4)]
Wait for all processes to finish
for result in results:
print(result.get())
print("All processes have finished")
In this example, we create a pool of 4 worker processes using multiprocessing.Pool. We then start the processes by applying the process_func function with different input values using pool.apply_async.
The process_func function simply prints out some messages indicating that it's running and doing some work. The actual processing takes about 5 seconds, so we use the time.sleep(1) call to simulate the processing time.
When you run this code, you'll see that the processes are started concurrently (in parallel). You can check by looking at the timestamps in the output - you should see multiple processes running at the same time.
Here's a breakdown of what's happening:
We create a pool of 4 worker processes usingmultiprocessing.Pool(processes=4). This creates a manager process that handles communication and synchronization between the worker processes. We start the processes by applying the process_func function with different input values using pool.apply_async((i,)) for i in range(4). When we call apply_async, it returns an AsyncResult object that represents the asynchronous computation. We store these objects in a list called results. We then wait for all processes to finish by iterating over the results list and calling the get() method on each result. The get() method blocks until the computation is complete, then returns the result of the computation.
By using parallel processing with Python's multiprocessing module, we can significantly speed up our code for computationally intensive tasks that can be divided into smaller chunks. This is especially useful when working with large datasets or performing complex scientific simulations!
Now, if you want to test this example in your local machine, simply copy and paste the code, and then run it using Python (e.g., python parallel_processing.py). You should see a bunch of output lines that look something like this:
Process 0 is running
Process 1 is running
Process 2 is running
Process 3 is running
Process 1 is doing some work...
Process 0 is doing some work...
Process 3 is doing some work...
Process 2 is doing some work...
All processes have finished
That's it! I hope this helps you understand how to use parallel processing in Python. Happy coding!
Does python support parallel programming reddit
I'll respond in English as requested!
To answer your question: Yes, Python supports parallel programming through various libraries and frameworks.
On Reddit, you can find several threads discussing Python's parallelization capabilities. Here are some key points:
Multiprocessing: Themultiprocessing module provides a way to create multiple processes, each running a separate instance of the Python interpreter. This allows for true parallelism, as each process runs concurrently with others. Joblib: Joblib is a set of tools for concurrent programming in Python. It offers several ways to run tasks in parallel, including using threads or processes. Dask: Dask (pronounced "dash") is a flexible parallel computing library for analytic computing. It allows you to parallelize existing serial code and scale up computationally expensive operations on large datasets. Ray: Ray is a high-performance distributed computing framework that enables you to run Python functions in parallel across multiple machines or processes.
Some popular Python libraries for parallel processing include:
Numba: A just-in-time (JIT) compiler that allows you to run existing NumPy code on GPUs and CPUs. OpenMP: An open-source standard for shared-memory parallel programming. Python bindings are available through theopenmp library. Cython: A superset of the Python language that allows you to write performance-critical parts of your program in a statically typed, C-like syntax.
When choosing a parallelization library, consider factors like:
Problem complexity: How complex is your computation? Simple tasks might be suitable for threading or multiprocessing, while more complex computations may require more advanced libraries like Dask or Ray. Data size and distribution: Are you working with large datasets that can be split across multiple cores or machines? Performance requirements: Do you need to optimize performance for specific use cases, such as machine learning or scientific computing?Remember that parallelizing code can be challenging, especially when dealing with complex algorithms or non-trivial data structures. Make sure to profile and test your parallelized code thoroughly to ensure it's performing well under load.
Hope this helps! If you have any further questions or would like more specific recommendations based on your project requirements, feel free to ask.