What is Scrapy Python used for?
What is Scrapy Python used for?
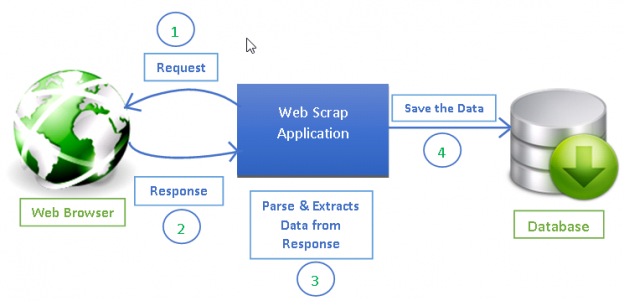
Scrapy is a powerful Python framework that enables developers to easily build web scrapers and crawlers. It's primarily used for extracting data from websites, handling large datasets, and processing unstructured data. Here are some of the most significant uses of Scrapy:
Web Scraping: Scrapy allows you to extract structured data from unstructured or semi-structured data sources such as web pages, XML files, and JSON files. This can be useful for gathering information about products, prices, reviews, and more.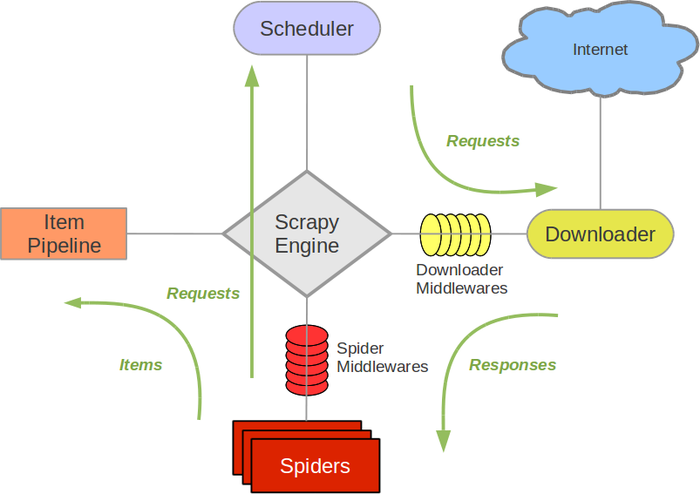
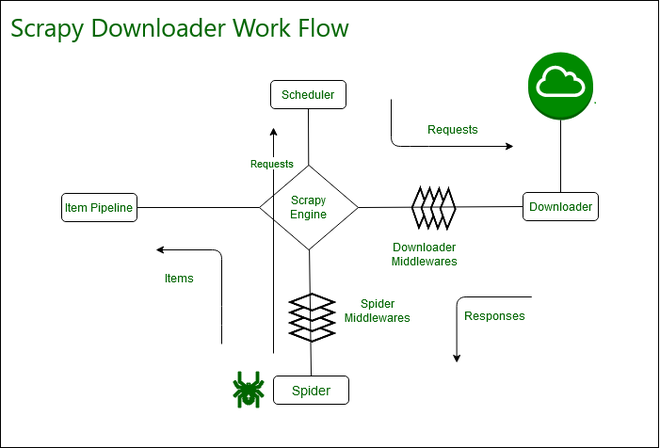
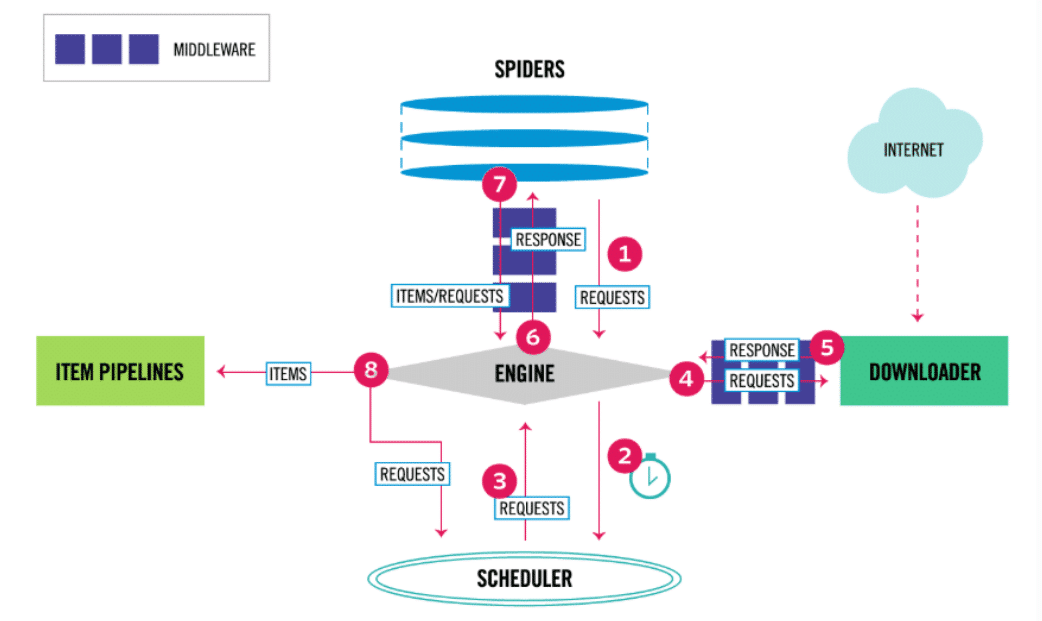
In summary, Scrapy is an incredibly versatile Python framework that excels at extracting, processing, and analyzing structured and unstructured data. Its versatility and scalability make it an excellent choice for various applications across multiple industries.
Web crawler Python
I'd be happy to help!
What is a Web Crawler?
A web crawler, also known as a spider or bot, is a computer program that automatically browses the World Wide Web and extracts specific data from websites. Its primary purpose is to collect information from multiple sources, categorize it, and make it easily accessible for further analysis.
How does a Python-based Web Crawler work?
Here's a high-level overview of how you can create a basic web crawler using Python:
Choose a library: You'll need a library that handles HTTP requests and parsing HTML or XML documents. Popular choices include:requests: For making HTTP requests. beautifulsoup4 (BS4 for short): For parsing HTML or XML documents. Define the crawler's behavior: Specify what type of data you want to extract, where it should be found on the page (e.g., specific tags or CSS selectors), and how often it should visit each site. Configure the crawl schedule: Determine when and how frequently the crawler should run.
A simple Python web crawler example
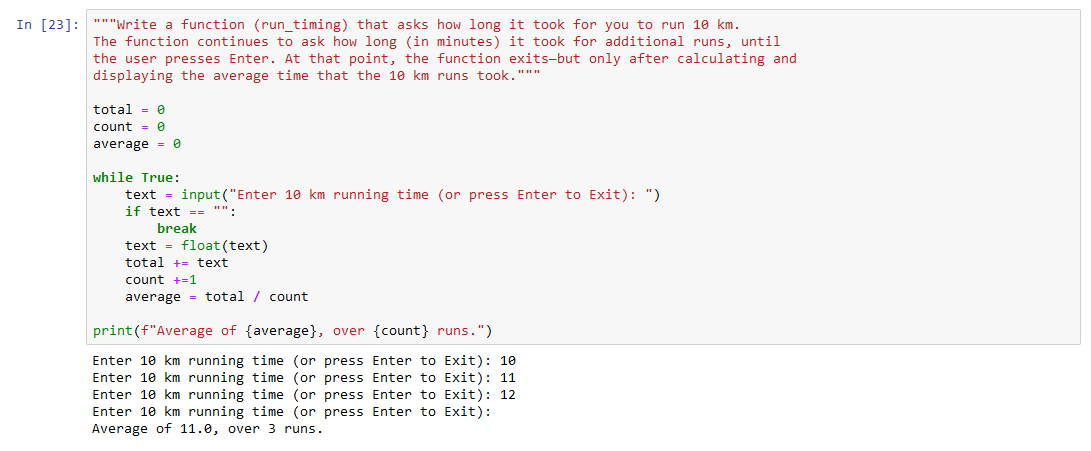
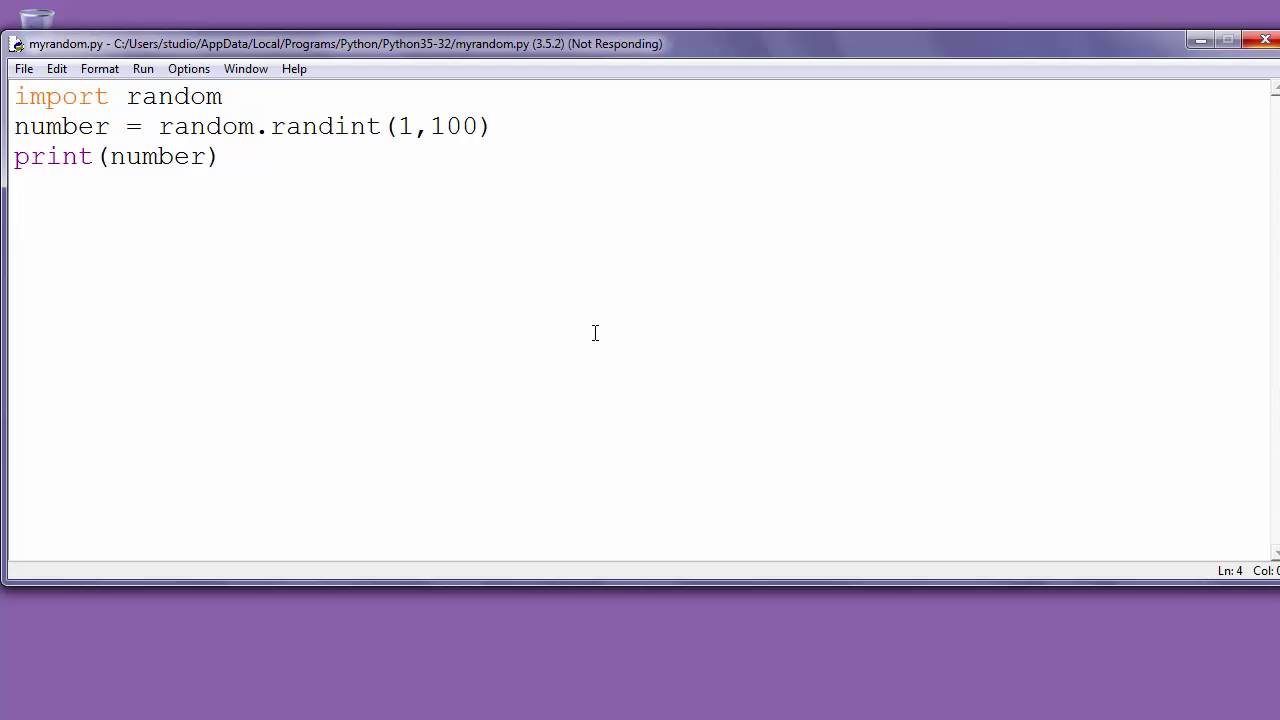
Let's create a basic web crawler that extracts titles from websites. We'll use requests for HTTP requests, beautifulsoup4 for parsing HTML documents, and a JSON file to store our findings.
import requests
from bs4 import BeautifulSoup
import json
Set up the crawl schedule: visit every hour
crawl_frequency = 3600 # seconds
Load the JSON file (if it exists)
try:
with open('results.json', 'r') as f:
results = json.load(f)
except FileNotFoundError:
results = {}
while True:
Crawl for a specified time (e.g., every hour)
start_time = time.time()
while time.time() - start_time < crawl_frequency:
Iterate over a list of URLs to crawl
for url in ['https://example.com/page1', 'https://example.com/page2']:
try:
Send an HTTP request and get the HTML response
response = requests.get(url)
if response.status_code == 200:
Parse the HTML document using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
title = soup.title.string
Store the title in our results dictionary
results[url] = title
except (requests.exceptions.RequestException, AttributeError):
pass # Handle errors and exceptions
Save the crawl results to a JSON file
with open('results.json', 'w') as f:
json.dump(results, f)
time.sleep(crawl_frequency - (time.time() - start_time))
This is just a basic example. You can extend this script to suit your specific needs and data extraction requirements.
Conclusion
Web crawling with Python offers numerous possibilities for data collection and analysis. By using libraries like requests and beautifulsoup4, you can create custom crawlers that extract information from websites, making it easier to analyze and process the data. Just remember to respect website terms of service and robots.txt files!
Additional Resources
Python Web Crawler Tutorial BeautifulSoup Documentation