Automated feature engineering Python
Automated feature engineering Python
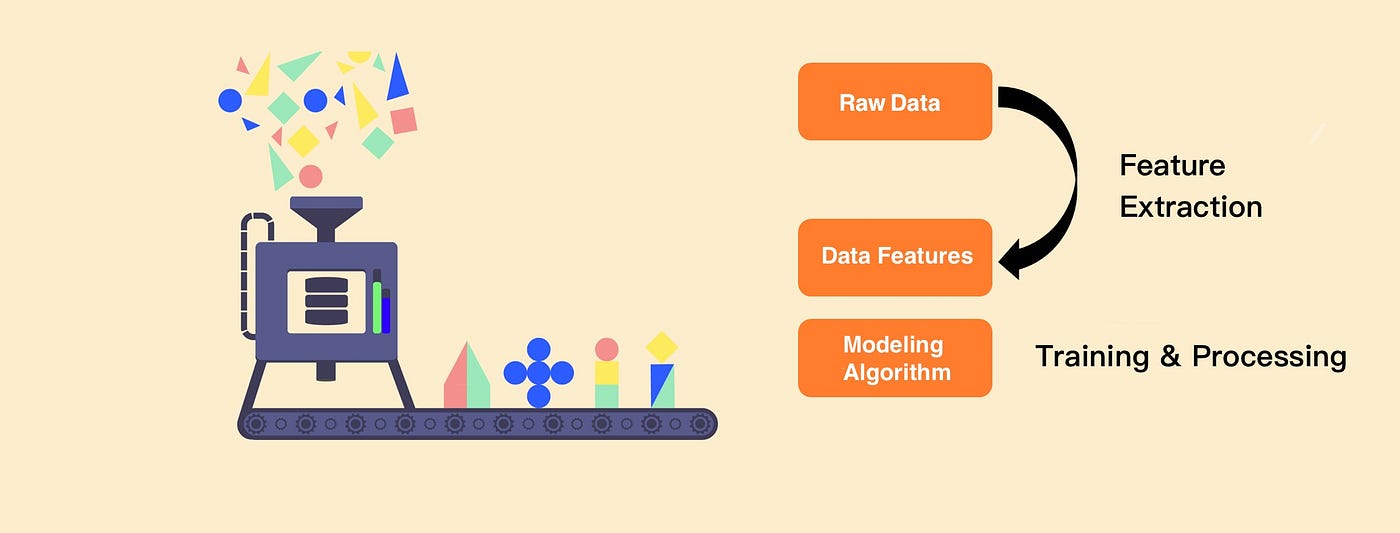
Feature engineering is a crucial step in the machine learning pipeline that involves transforming raw data into features that can be used to train accurate models. Python provides various libraries and tools to automate this process, making it easier to focus on modeling rather than manual feature extraction. Here are some popular techniques and libraries for automated feature engineering in Python:
pandas: The pandas library is widely used for data manipulation and analysis. It provides various methods likemelt, pivot_table, and get_dummies that can be used to transform data into features.
Example: Convert categorical variables into binary features using pd.get_dummies.
import pandas as pd
df = pd.read_csv("data.csv")
binary_df = pd.get_dummies(df, columns=["categorical_column"])
StandardScaler and PolynomialFeatures that can be used to transform data into features.
Example: Scale numerical features using StandardScaler.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_features = scaler.fit_transform(df[["numerical_column"]])
interaction, real_data, and cross_val_mse out of the box.
Example: Extract interaction features between two numerical columns using lightgbm.feature_importance.
import lightgbm as lgb
train_set = lgb.Dataset(df[["numerical_column1", "numerical_column2"]])
interaction_features = train_set.interaction()
date_to_datetime, categorical_to_binary, and polynomial out of the box.
Example: Convert date columns into datetime features using featurelabs.date_to_datetime.
import featurelabs as fl
df = pd.read_csv("data.csv")
datetime_df = fl.date_to_datetime(df[["date_column"]])
auto_fe, auto_impute, and auto_transform out of the box.
Example: Automatically extract features from categorical columns using automl.feature_extraction.
import automl as am
df = pd.read_csv("data.csv")
features = am.feature_extraction(df[["categorical_column"]])
bucketize, hash, and embed out of the box.
Example: Convert numerical columns into categorical features using tf.feature.bucketize.
import tensorflow as tf
df = pd.read_csv("data.csv")
feature_cols = []
for col in ["numerical_column1", "numerical_column2"]:
feature_cols.append(tf.feature.bucketize(df[col], num_buckets=5))
In conclusion, Python provides various libraries and tools for automated feature engineering. By utilizing these libraries, data scientists can focus on modeling rather than manual feature extraction, leading to improved model accuracy and efficiency.
Python feature engineering examples

Here are some Python feature engineering examples:

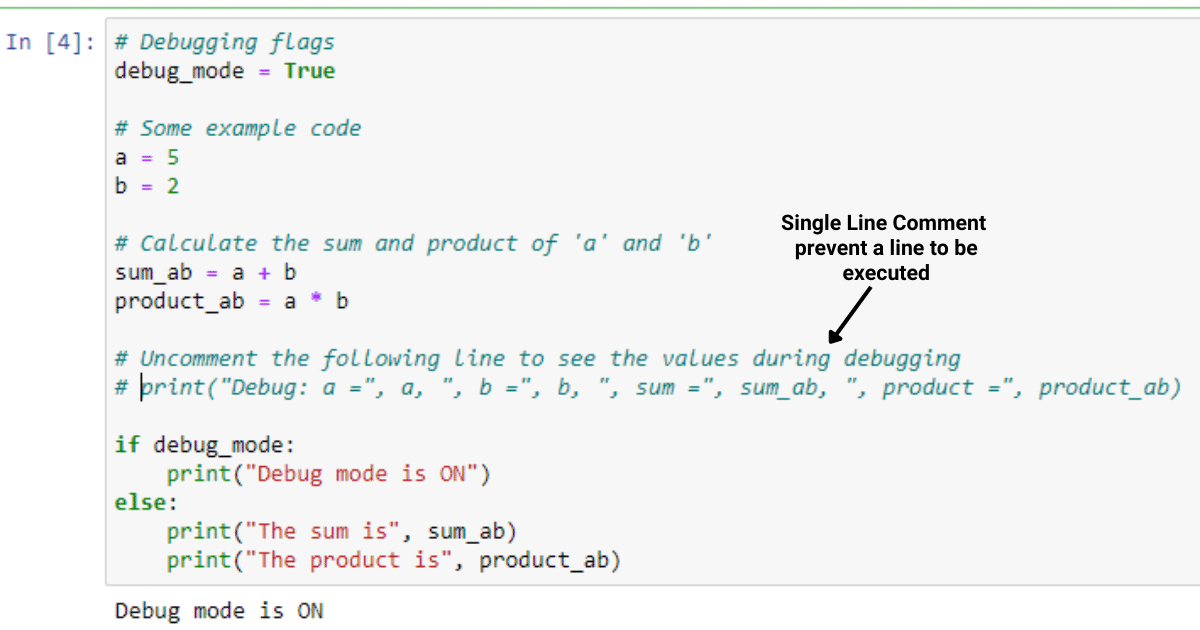
Example 1: Handling missing values
Suppose we have a dataset with missing values, and we want to impute them using the mean value of each feature.
import pandas as pd

from sklearn.impute import SimpleImputer

Load the data
data = pd.read_csv('data.csv')
Create an imputer object
imputer = SimpleImputer(strategy='mean')
Fit and transform the data
data_imputed = imputer.fit_transform(data)
Example 2: Handling categorical variables
Suppose we have a dataset with categorical variables, and we want to convert them into numerical features using one-hot encoding.
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
Load the data
data = pd.read_csv('data.csv')
Create an one-hot encoder object
ohe = OneHotEncoder()
Fit and transform the data
data_onehot = ohe.fit_transform(data[['categorical_var']]).toarray()
Example 3: Handling date features
Suppose we have a dataset with date features, and we want to convert them into numerical features using datetime functions.
import pandas as pd
import datetime as dt
Load the data
data = pd.read_csv('data.csv')
Convert date features into numerical features
data['date_feature'] = data['date_feature'].apply(lambda x: int(dt.datetime.strptime(x, '%Y-%m-%d').timestamp()))
Example 4: Handling text features
Suppose we have a dataset with text features, and we want to convert them into numerical features using TF-IDF (Term Frequency-Inverse Document Frequency) transformations.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
Load the data
data = pd.read_csv('data.csv')
Create a TF-IDF vectorizer object
vectorizer = TfidfVectorizer()
Fit and transform the text features
text_features_tfidf = vectorizer.fit_transform(data['text_feature'])
Example 5: Handling image features
Suppose we have a dataset with image features, and we want to convert them into numerical features using convolutional neural networks (CNNs).
import pandas as pd
from keras.preprocessing.image import ImageDataGenerator
Load the data
data = pd.read_csv('data.csv')
Create an image data generator object
image_generator = ImageDataGenerator(rescale=1./255)
Fit and transform the image features
image_features_cnn = []
for img in data['image_feature']:
img_array = image_generator.fit_transform(img)
img_tensor = tf.convert_to_tensor(img_array, dtype=tf.float32)
img_features_cnn.append(tf.nn.max_pool(img_tensor, ksize=[1,3,3,1], strides=[1,2,2,1], padding='SAME'))
Example 6: Handling audio features
Suppose we have a dataset with audio features, and we want to convert them into numerical features using mel-frequency cepstral coefficients (MFCCs).
import pandas as pd
from librosa.feature import mfcc
Load the data
data = pd.read_csv('data.csv')
Create an MFCC extractor object
mfcc_extractor = mfcc(data['audio_feature'], sr=22050, n_mfcc=13)
Extract MFCC features
mfcc_features = []
for audio in data['audio_feature']:
mfccs = mfcc_extractor(audio)
mfcc_features.append(mfccs)
These are just a few examples of how to perform feature engineering using Python. Depending on the nature of your dataset and the type of problem you're trying to solve, there are many other techniques and libraries available for handling missing values, categorical variables, date features, text features, image features, audio features, and more!