Decision tree Python code example
Decision tree Python code example
I'm glad you asked!
A decision tree is a popular machine learning algorithm used for classification and regression tasks. It's a tree-like model of decisions that can be used to make predictions based on the input data. Here's an example of how you can implement a decision tree in Python using the scikit-learn library:
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
Load the iris dataset
iris = datasets.load_iris()
Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
Create a decision tree classifier with a maximum depth of 5
clf = DecisionTreeClassifier(max_depth=5)
Train the classifier on the training data
clf.fit(X_train, y_train)
Make predictions on the testing data
y_pred = clf.predict(X_test)
This code creates a decision tree classifier using the iris dataset. The DecisionTreeClassifier class is used to create the classifier, and it's trained on the training data using the fit method.
The decision tree algorithm works as follows:
Start with the entire dataset. Choose a feature that best splits the dataset (e.g., based on information gain). Split the dataset into two subsets based on this feature. Recursively repeat steps 1-3 for each subset until some stopping criterion is reached (e.g., maximum depth, minimum size of the subset).This code example trains a decision tree classifier with a maximum depth of 5, and then uses it to make predictions on the testing data.
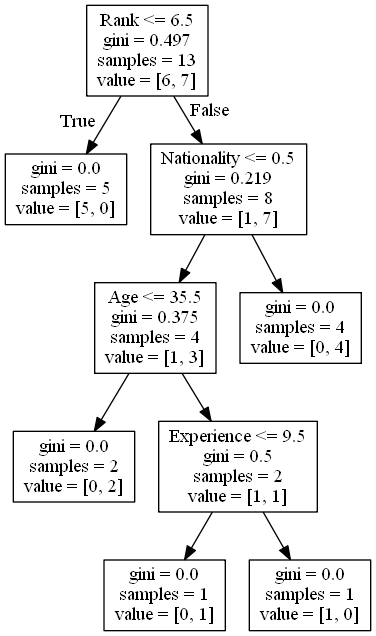
Here's how you can visualize the decision tree:
from sklearn.tree import plot_tree
Plot the decision tree
plot_tree(clf, filled=True)
This code will create a graphical representation of the decision tree. You can customize the visualization by adding labels, changing the color scheme, etc.
Note that this is just one example of how you can use decision trees in Python, and there are many ways to improve upon this basic implementation (e.g., tuning hyperparameters, using bagging or boosting).
I hope this helps!
Decision tree implementation in Python sklearn

Here's a comprehensive overview of decision tree implementation in Python using scikit-learn:
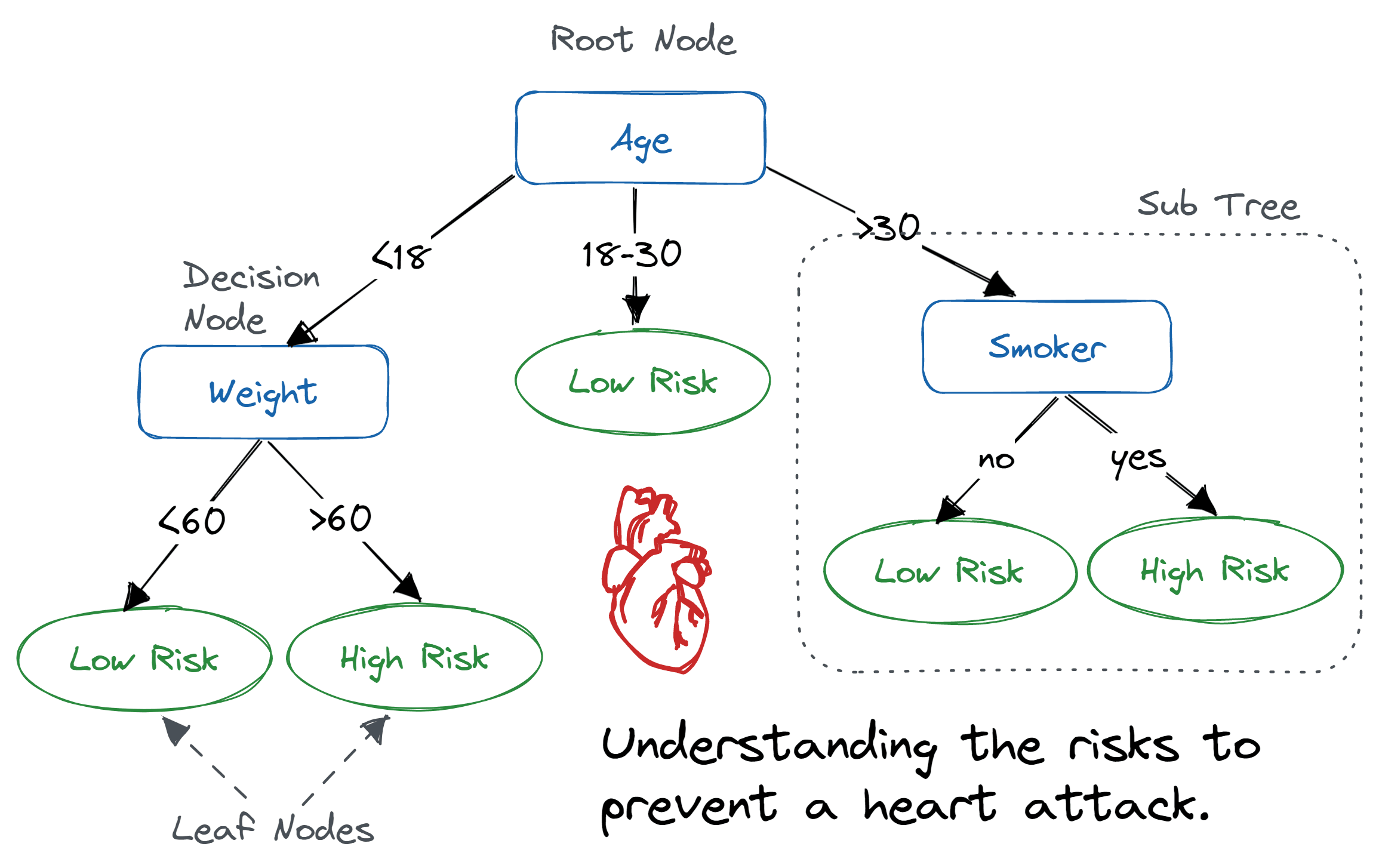
What is Decision Tree?
Decision Trees are a type of machine learning model that works by creating a tree-like structure to classify data or predict outcomes. It uses the concept of recursion, where each internal node (split point) decides which branch to follow based on certain criteria.

How does Decision Tree work?
Root Node: The process starts with the root node, which represents the entire dataset. Splitting: Each node is split into two or more child nodes based on a set of rules defined by a decision-making algorithm (e.g., Gini impurity, entropy). Leaf Nodes: The splitting process continues until each leaf node corresponds to a specific class label or predicted outcome.scikit-learn's Decision Tree Implementation
To implement a decision tree in Python using scikit-learn, you can use the DecisionTreeClassifier or DecisionTreeRegressor classes from the sklearn.tree module. Here's an example:
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
Load iris dataset and split it into training and testing sets
iris = load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
Create a decision tree classifier with 5 max depth
dt = DecisionTreeClassifier(max_depth=5)
dt.fit(X_train, y_train)
Evaluate the model on the testing set
y_pred = dt.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
In this example, we load the iris dataset and split it into training and testing sets. We then create a decision tree classifier with a maximum depth of 5 using the DecisionTreeClassifier class. The fit() method is used to train the model on the training data, and the predict() method is used to make predictions on the testing set.
Key Parameters
max_depth: The maximum number of nodes in the tree. min_samples_split: The minimum number of samples required to split an internal node. min_samples_leaf: The minimum number of samples required to be at a leaf node. criterion: The criterion used to decide the best split point (e.g., Gini impurity, entropy).
Advantages
Interpretability: Decision Trees are easy to understand and visualize. Handling Non-Linear Relationships: Decision Trees can capture non-linear relationships between features. Handling High-Dimensional Data: Decision Trees can handle high-dimensional data by recursively splitting the feature space.Disadvantages
Overfitting: Decision Trees can suffer from overfitting, especially when there are many features or a small number of training examples. Not Suitable for All Problems: Decision Trees may not be suitable for problems where the relationship between variables is complex or non-linear.In conclusion, decision trees are a powerful tool for classification and regression tasks in machine learning. With scikit-learn's implementation, you can easily create and train decision tree models using Python.