How to use encoding UTF-8 in Python?
How to use encoding UTF-8 in Python?
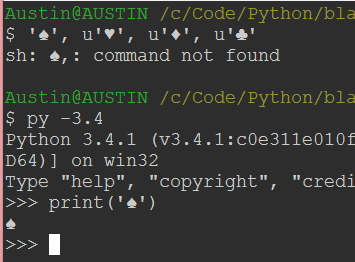
I'm happy to help you with that!
In Python, you can use the UTF-8 encoding when working with text files or strings that contain non-ASCII characters. Here are a few ways to achieve this:
1. Using the open() function
When opening a file in Python, you can specify the encoding as an argument:
with open('example.txt', 'w', encoding='UTF-8') as f:
f.write('Hello, Welt!')
In this example, we're opening a file called example.txt in write mode ('w') and specifying that it should use the UTF-8 encoding.
2. Using the encode() method
If you have a string that contains non-ASCII characters, you can use the encode() method to convert it to a bytes object using the UTF-8 encoding:
my_string = 'Hello, Welt!'
utf8_bytes = my_string.encode('UTF-8')
print(utf8_bytes) # Output: b'Hello, Wx65lt!'
In this example, we're taking a string and converting it to a bytes object using the UTF-8 encoding.
3. Using the decode() method
If you have a bytes object that contains text encoded in UTF-8, you can use the decode() method to convert it back to a Python string:
utf8_bytes = b'Hello, Wx65lt!'
my_string = utf8_bytes.decode('UTF-8')
print(my_string) # Output: 'Hello, Welt!'
In this example, we're taking a bytes object and converting it back to a Python string using the UTF-8 encoding.
4. Using the chardet library
If you need to detect the encoding of a file or text without specifying it beforehand, you can use the chardet library:
import chardet
with open('example.txt', 'rb') as f:
content = f.read()
detected_encoding = chardet.detect(content)
if detected_encoding['encoding'] == 'UTF-8':
print("Detected encoding: UTF-8")
else:
print("Detected encoding:", detected_encoding['encoding'])
In this example, we're using the chardet library to detect the encoding of a file. If the detected encoding is UTF-8, we print a message indicating that.
I hope this helps! Let me know if you have any further questions.
encoding utf-8 python pandas
Encoding UTF-8 and Python Pandas for Data Analysis
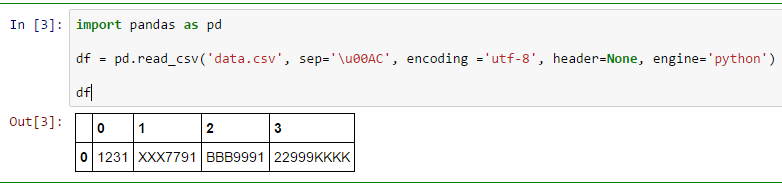
In today's digital world, data is being generated at an unprecedented pace. As a result, the importance of efficient data analysis has become more significant than ever. Encoding UTF-8 and using Python with pandas can help you achieve this goal. Let me walk you through how to do it.
What is UTF-8 Encoding?
UTF-8 (UCS Transformation Format – 8-bit) is a variable-length character encoding format that can represent all characters in the Unicode Standard. This encoding scheme is widely used due to its compact representation, simplicity, and support for languages with non-Latin scripts. In Python, UTF-8 is the default encoding for strings.
Why Use Python with Pandas?
Python is an excellent programming language for data analysis due to its ease of use, flexibility, and vast libraries. Pandas, a Python library, provides data structures and functions for efficiently handling structured data, including tabular data such as spreadsheets and SQL tables. With pandas, you can perform various operations like filtering, grouping, sorting, and merging data.
How to Use Encoding UTF-8 and Python with Pandas
To use encoding UTF-8 and Python with pandas for data analysis:
Install Python and pandas: If you haven't already, install Python (version 3.x or later) from the official Python website. Then, install pandas using pip:pip install pandas. Create a sample dataset: For this example, we'll use a simple CSV file named "data.csv" with three columns: name, age, and country. Read the dataset into a pandas DataFrame: Use the pandas read_csv function to load your data into a pandas DataFrame:
import pandas as pd
df = pd.read_csv('data.csv', encoding='utf-8')
Here, encoding='utf-8' specifies that the file is encoded in UTF-8.
# Filter rows where age > 25
df = df[df['age'] > 25]
Sort the DataFrame by age in descending order
df.sort_values(by='age', ascending=False, inplace=True)
Group data by country and calculate average age
grouped_data = df.groupby('country')['age'].mean()
import matplotlib.pyplot as plt
Plot the mean age distribution per country
plt.figure(figsize=(8, 6))
plt.plot(grouped_data.index, grouped_data.values)
plt.xlabel('Country')
plt.ylabel('Average Age')
plt.title('Mean Age Distribution Per Country')
plt.show()
In this example, we've demonstrated how to use encoding UTF-8 and Python with pandas for data analysis. By combining these two powerful tools, you can efficiently handle structured data, perform various operations, and visualize your results.
Conclusion
Encoding UTF-8 and using Python with pandas are essential skills for any aspiring data analyst. With UTF-8 encoding, you can ensure compatibility with non-Latin scripts and various languages. Python's flexibility and vast libraries make it an excellent language for data analysis, while pandas provides efficient tools for handling structured data. By mastering these concepts, you'll be well-equipped to tackle complex data analysis projects.





























