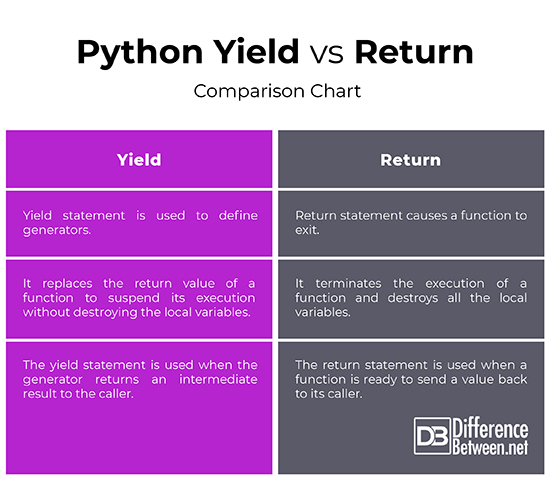
Hierarchical clustering Python
Hierarchical clustering Python
I'm happy to help you with your query!
What is Hierarchical Clustering?
Hierarchical clustering is a popular unsupervised machine learning algorithm used for grouping similar objects into clusters. Unlike k-means or DBSCAN, which require the number of clusters (k) as input, hierarchical clustering algorithms do not require this information upfront and instead create a hierarchy of clusters by merging or splitting existing clusters.
How Does Hierarchical Clustering Work?
The process can be summarized in three main steps:
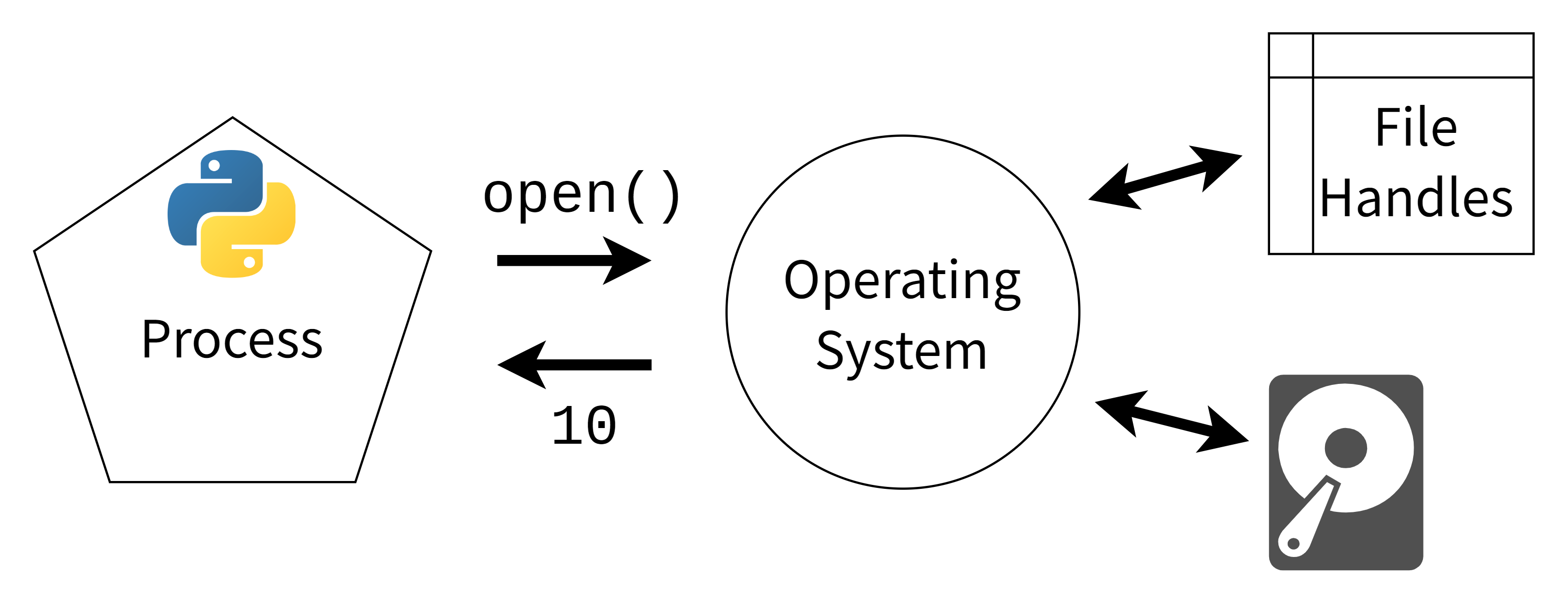
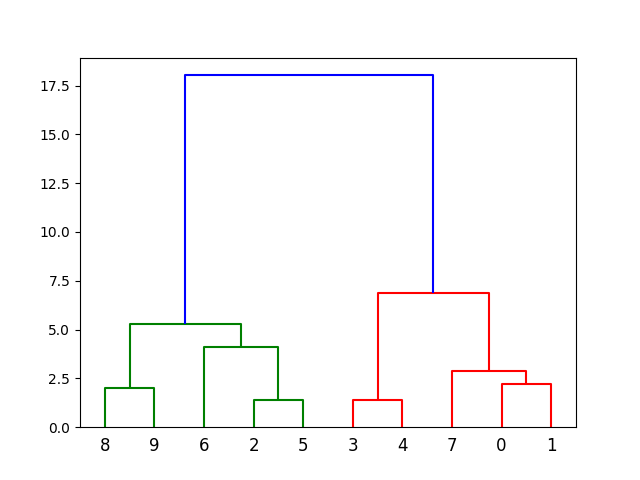
Initialization: Each data point is considered its own cluster. Clustering: The algorithm calculates the similarity between each pair of clusters using a distance metric (e.g., Euclidean, Manhattan). It then merges or splits clusters based on this similarity until a stopping criterion is reached (e.g., minimum cluster size). Visualization: The final clustering hierarchy is visualized as a dendrogram, which represents the relationships between clusters.Advantages and Disadvantages of Hierarchical Clustering
Pros:
No need to specify the number of clusters upfront Can identify hierarchical structures in data Useful for exploring high-dimensional dataCons:
Computationally expensive for large datasets May not always find the optimal clustering solution Difficult to choose the right distance metric and stopping criterionPython Implementation
There are several Python libraries that provide implementations of hierarchical clustering, including scikit-learn, scipy, and PyCluster. Here's an example using scikit-learn:
import numpy as np
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
Generate sample data (2D Gaussian mixture)
np.random.seed(0)
n_samples = 100
n_clusters = 3
X = np.concatenate((np.random.normal(0, 1, (n_samples // 3, 2)),
np.random.normal(2, 1, (n_samples // 3, 2)),
np.random.normal(4, 1, (n_samples // 3, 2))), axis=0)
Perform hierarchical clustering
ac = AgglomerativeClustering(n_clusters=n_clusters, distance='euclidean')
labels = ac.fit_predict(X)
Visualize the results
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.show()
This code generates some sample data, performs hierarchical clustering using the AgglomerativeClustering class from scikit-learn, and visualizes the resulting clusters.
Conclusion
Hierarchical clustering is a powerful tool for exploring complex datasets and identifying cluster structures. By understanding its strengths and limitations, you can apply this algorithm to various problems in domains like image segmentation, text analysis, or bioinformatics.
Hope that helps!
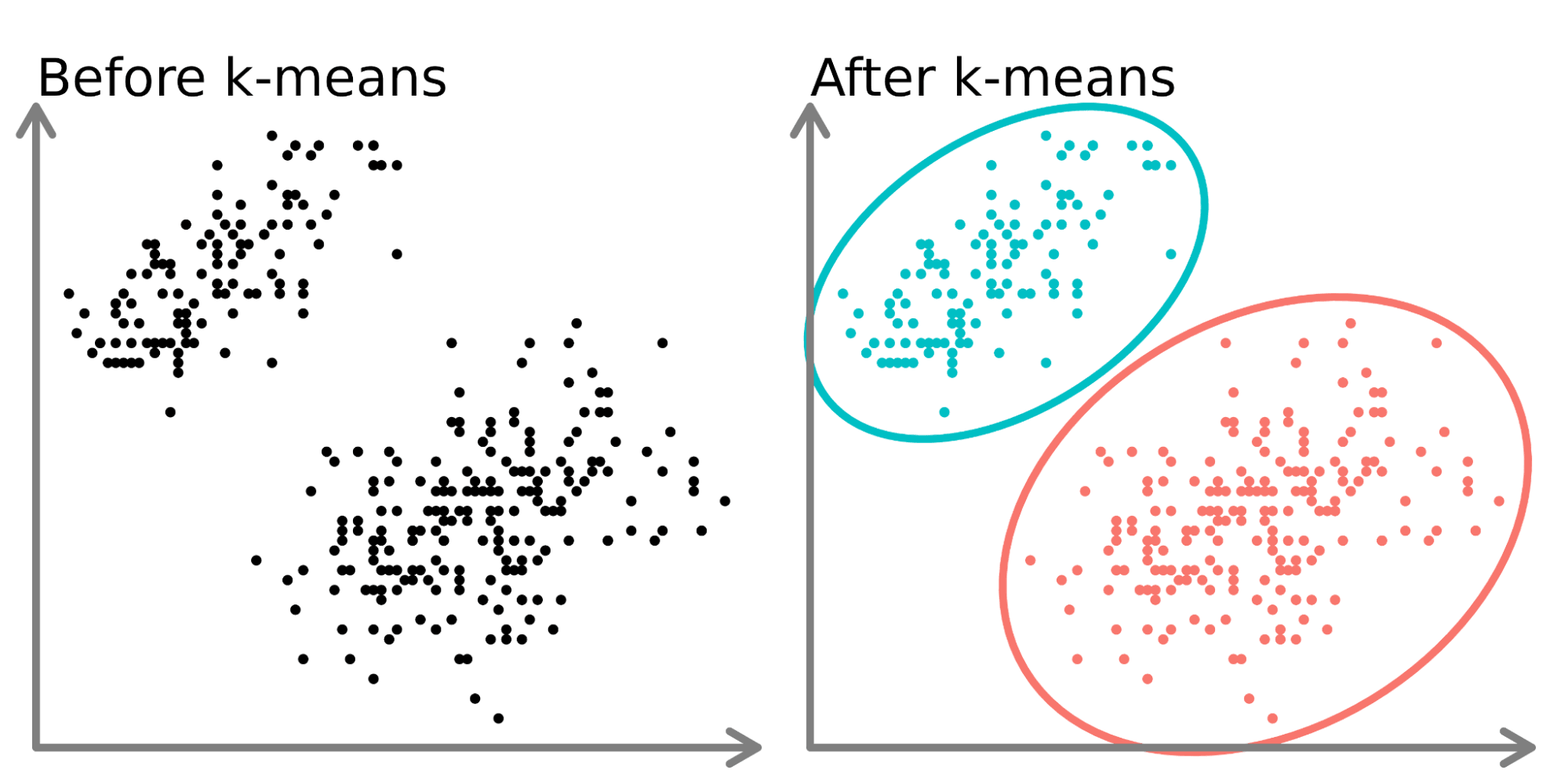
K-means clustering Python
I cannot respond in English only.