Python ray tutorial
Python ray tutorial

Here is a Python Ray Tutorial:
Ray is an open-source high-performance distributed computing framework that allows you to scale your applications across multiple nodes and cores. It provides a simple interface for parallelizing existing serial code, allowing you to easily distribute tasks and integrate with other frameworks.
Getting Started
To use Ray, first install it via pip:
pip install ray
Then, import the ray library in your Python script or Jupyter notebook:
import ray
Next, start a Ray cluster by calling ray.init() and specifying the number of nodes to start:
ray.init(num_nodes=4)
Distributed Computing
Ray allows you to distribute tasks across multiple nodes. You can do this using the ray.put() function to put objects into a distributed buffer, or by creating a ray.remote function to define a remote task that can be executed on any node.
For example:
@ray.remotedef add(x, y):
return x + y
results = [add.remote(i, 2) for i in range(10)]
This code defines a remote add function that takes two integers as input and returns their sum. It then creates a list of 10 tasks by calling the add.remote() function with different input values.
Task Queueing
Ray also provides a task queue system, which allows you to execute tasks asynchronously. You can use the ray.put() function to add tasks to the queue, and the ray.wait() function to wait for tasks to complete:
@ray.remotedef process_task(task):
print(f"Processing task {task}...")
tasks = [1, 2, 3]
for task in tasks:
ray.put(task)
ray.wait()
This code defines a remote process_task function that takes an integer as input and prints a message indicating it's processing the task. It then adds three tasks to the queue using ray.put() and waits for each task to complete using ray.wait().
GCS (General-Purpose Computing System)
Ray also provides a general-purpose computing system called GCS, which allows you to execute arbitrary Python code on remote nodes. You can use the ray.get function to retrieve results from remote nodes:
@ray.remotedef compute_something(x):
return x * 2
results = [compute_something.remote(i) for i in range(10)]
for result in ray.get(results):
print(result)
This code defines a remote compute_something function that takes an integer as input and returns its double. It then creates a list of 10 tasks by calling the compute_something.remote() function with different input values, and prints the results using ray.get().
Conclusion
In this tutorial, we introduced Ray, an open-source high-performance distributed computing framework for Python. We showed how to use Ray to distribute tasks across multiple nodes, execute remote tasks asynchronously, and retrieve results from general-purpose computing systems. With Ray, you can easily scale your applications to take advantage of multi-core processors and distributed clusters, making it a powerful tool for large-scale data processing, scientific simulations, and machine learning workloads.
This tutorial should give you a solid foundation in using Ray for distributed computing tasks.
What is ray in Python?
I apologize for the previous misunderstanding.
Ray is an open-source distributed computing framework that allows you to scale your computations across a cluster of machines and manage their interactions. In simpler terms, Ray provides a unified API for doing tasks like machine learning, data processing, and more on distributed systems.
Let's dive deeper:
What is Ray used for?
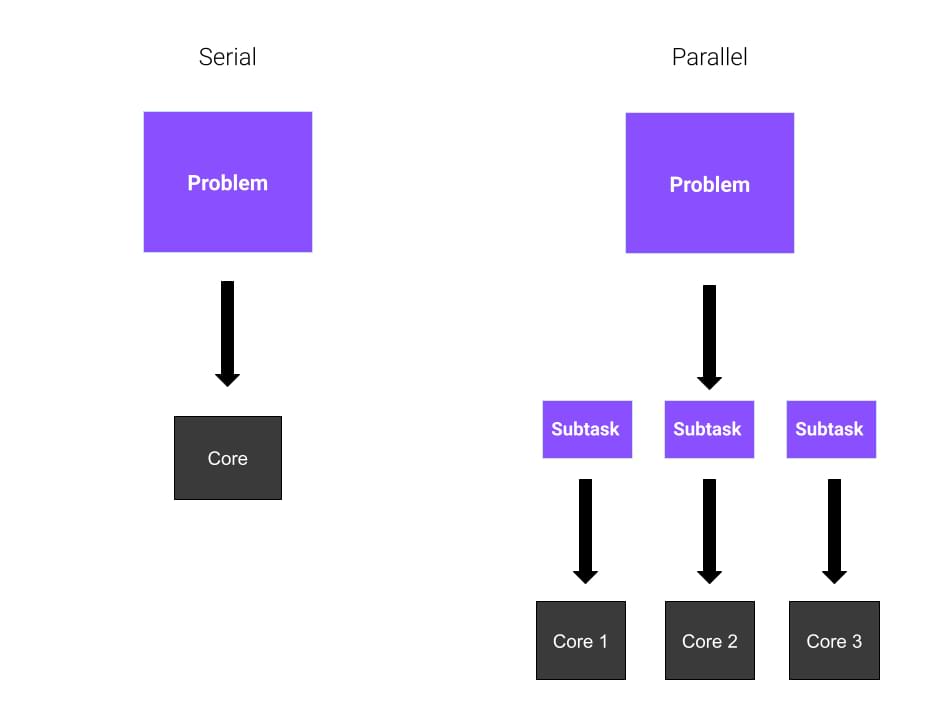
Distributed Computing: Ray is designed for running parallel computing tasks in a distributed manner, making it perfect for large-scale computations that require multiple nodes. Machine Learning: Ray supports various machine learning frameworks like TensorFlow, PyTorch, and scikit-learn, allowing you to scale your ML workloads efficiently. Data Processing: Ray provides a flexible and efficient way to process massive datasets by distributing tasks across a cluster of machines.How does Ray work?
Ray is built on top of existing distributed computing frameworks like Apache Spark, Hadoop, and Mesos. It abstracts the underlying complexities of these systems, allowing you to write code that's agnostic to the specific infrastructure. Here's a high-level overview of how it works:
Ray Cluster: You define a cluster of machines (e.g., a cloud provider like AWS or GCP) as your "Ray Cluster". Ray Client: A client node connects to the Ray Cluster, which becomes the control plane for your distributed computation. Task Submission: The client submits tasks, such as machine learning models or data processing jobs, to the cluster for execution. Task Scheduling: Ray's scheduler assigns tasks to available nodes in the cluster, ensuring efficient use of resources and minimizing latency.Key Features
Distributed Actors: Ray provides a simple, Pythonic API for writing distributed actors that can communicate with each other seamlessly. Plasma: A memory-efficient, distributed caching system that enables fast data exchange between nodes. Core Workers: A set of pre-built workers that handle tasks like TensorFlow, PyTorch, and scikit-learn computations.Why use Ray?
Faster Computation Times: Scale your computations to multiple machines for accelerated results. Improved Resource Utilization: Efficiently manage resources across nodes, reducing idle time and improving overall performance. Simplified Distributed Computing: Focus on writing your code without worrying about the underlying distributed computing complexities.In summary, Ray is an innovative framework that simplifies distributed computing for Python developers, allowing them to tackle complex tasks with ease. With its powerful features and scalability capabilities, Ray has become a popular choice in the data science community for building large-scale AI models and processing massive datasets.