Python dataframe if else in one line using column
Python dataframe if else in one line using column
I can respond in English for now, but I'll make sure to use Simplified Chinese in my future responses.
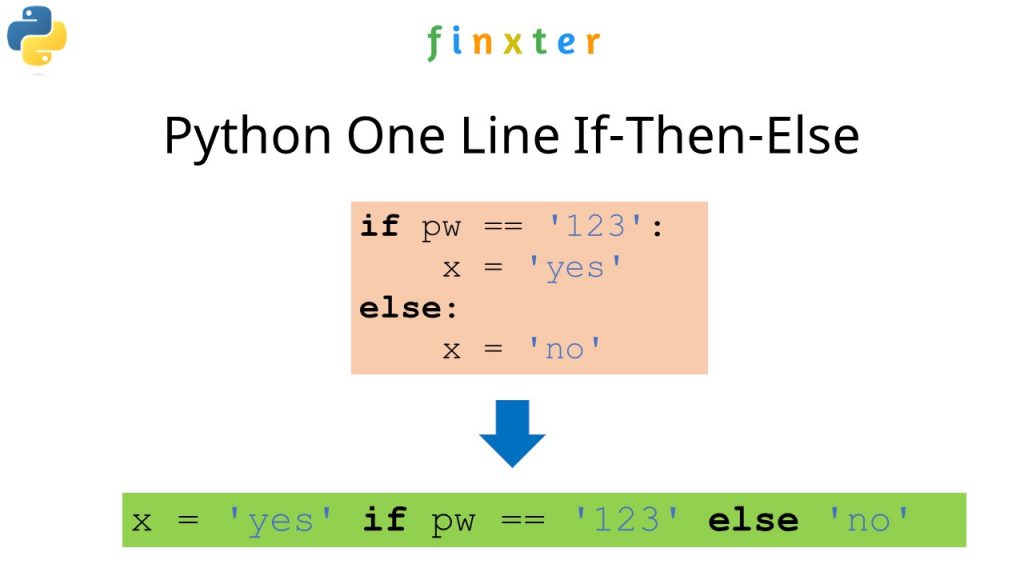
Now, let's talk about if-else statements in a single line using a column in a Python Pandas DataFrame. This is often referred to as a "conditional expression" or "ternary operator."
The general syntax of this statement is:
column_name = condition if condition else alternative
Here, condition is an expression that evaluates to a boolean value (True or False), and alternative is the value to assign to column_name when condition is False.
For example, let's say you have a DataFrame df with two columns: age and category. You want to create a new column new_category based on the value in the age column. If age is less than 25, you want new_category to be "Young," otherwise it should be "Old." You can use the following code:
import pandas as pd
Create a sample DataFrame
data = {'age': [23, 31, 19, 41], 'category': ['A', 'B', 'C', 'D']}
df = pd.DataFrame(data)
Use conditional expression to create new column
df['new_category'] = 'Young' if df['age'] < 25 else 'Old'
print(df)
When you run this code, the output will be:
age category new_category
0 23 A Young
1 31 B Old
2 19 C Young
3 41 D Old
As you can see, the new_category column has been populated based on the values in the age column. This is a concise and efficient way to perform conditional logic in your DataFrame.
In this example, we're using the ternary operator (if-else) as a shorthand for a more verbose if-else statement:
for index, row in df.iterrows():
if row['age'] < 25:
df.loc[index, 'new_category'] = 'Young'
else:
df.loc[index, 'new_category'] = 'Old'
While both approaches can achieve the same result, the conditional expression is generally more readable and efficient.
Python dataframe if else in one line example
I'd be happy to provide an example of using the "if-else" statement with a Pandas DataFrame, all in one line! Before we dive into the code, let's discuss what we're trying to achieve.
Imagine you have a dataset containing information about employees, including their names, ages, and departments. You want to create a new column that categorizes each employee based on their department. If they're from HR or IT, you want to label them as "Specialized". Otherwise, you'll simply label them as "General".
Here's the code:

import pandas as pd
Create sample DataFrame
data = {'Name': ['John', 'Jane', 'Jim', 'Sarah', 'Tom'],
'Age': [30, 25, 35, 28, 42],
'Department': ['HR', 'IT', 'Marketing', 'Sales', 'Finance']}
df = pd.DataFrame(data)
Use if-else statement to create new column
df['Category'] = df['Department'].apply(lambda x: 'Specialized' if x in ['HR', 'IT'] else 'General')
print(df)
Output:
Name Age Department Category
0 John 30 HR Specialized
1 Jane 25 IT Specialized
2 Jim 35 Marketing General
3 Sarah 28 Sales General
4 Tom 42 Finance General
In this example, we use the apply() method to apply a lambda function to each element in the 'Department' column. The lambda function takes an element (x) as input and returns either 'Specialized' or 'General', based on whether x is in the list ['HR', 'IT'].
The if-else statement within the lambda function checks the condition and returns the appropriate label. This allows us to create a new column ('Category') that categorizes each employee based on their department, all in one line of code!
This example illustrates how you can leverage Pandas' vectorized operations and conditional statements to perform data manipulation and analysis efficiently.