How to run Scrapy in Python?
How to run Scrapy in Python?
I'd be happy to help!
Scrapy is a powerful Python framework used for building web scrapers. To run Scrapy, you need to have Python installed on your system (Python 3.x or higher is recommended). Here's a step-by-step guide on how to get started:
Installation
You can install Scrapy using pip, the package installer for Python. Open a terminal or command prompt and type:
pip install scrapy
This might take a few seconds to complete, depending on your internet connection.
Creating a new project
Once Scrapy is installed, you can create a new project by running the following command:
scrapy startproject myproject
Replace myproject with any name you like. This will create a basic directory structure for your project.
myproject/
myproject/
init.py
items.py
pipelines.py
settings.py
spiders/
init.py
my_spider.py
startups.cfg
The scrapy command has created a basic directory structure for you. You'll see several files and directories, including:
items.py: This file defines the data structures used to store scraped items. pipelines.py: This file contains code that will be executed after each item is processed. settings.py: This file contains all the settings for your Scrapy project. spiders/: This directory will contain one or more spider files, which define how the scraper extracts data from a website.
Running a spider
To run a spider, navigate to the spiders directory and execute:
scrapy crawl my_spider
Replace my_spider with the name of your spider file. This will start the scraping process, and you'll see output indicating what items are being scraped.
Writing a spider
To write a spider, create a new file in the spiders directory called, for example, my_spider.py. Here's an example:
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = [
'https://www.example.com',
]
def parse(self, response):
Extract data from the page
title = response.css('title::text').get()
yield {'title': title}
This spider will extract the title of each web page at https://www.example.com. You can customize this code to suit your needs.
Tips and tricks
Scrapy has an extensive documentation, which is well worth reading. Check out the official Scrapy documentation for more information. To debug your spider, use thescrapy shell command, which allows you to interactively explore the HTML of a website. If you encounter issues running Scrapy, check your Python and pip versions. Make sure they are up-to-date.
That's it! With these steps, you should be able to run Scrapy in Python and start building your own web scrapers. Happy scraping!
What is Scrapy Python used for?
Scrapy is a powerful Python framework that enables developers to easily build web scrapers and crawlers. It's primarily used for extracting data from websites, handling large datasets, and processing unstructured data. Here are some of the most significant uses of Scrapy:
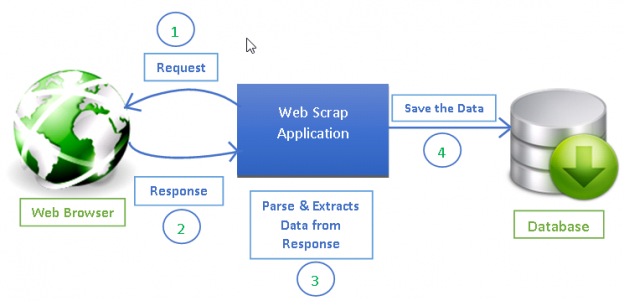
Web Scraping: Scrapy allows you to extract structured data from unstructured or semi-structured data sources such as web pages, XML files, and JSON files. This can be useful for gathering information about products, prices, reviews, and more.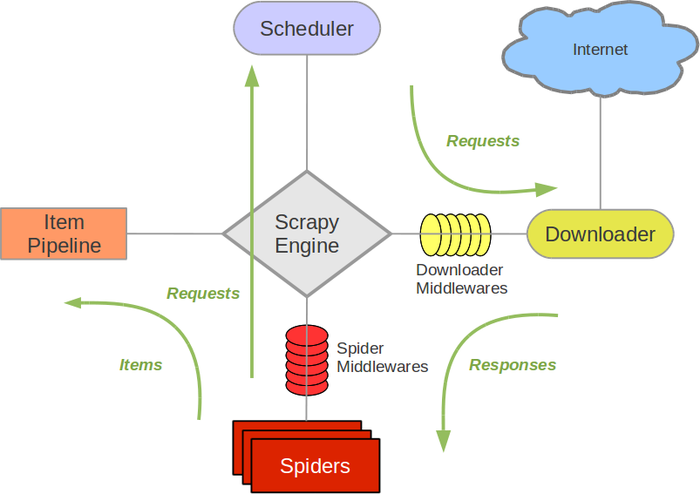
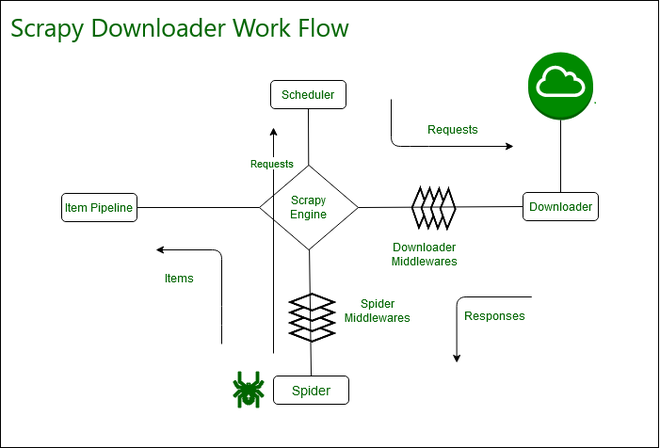
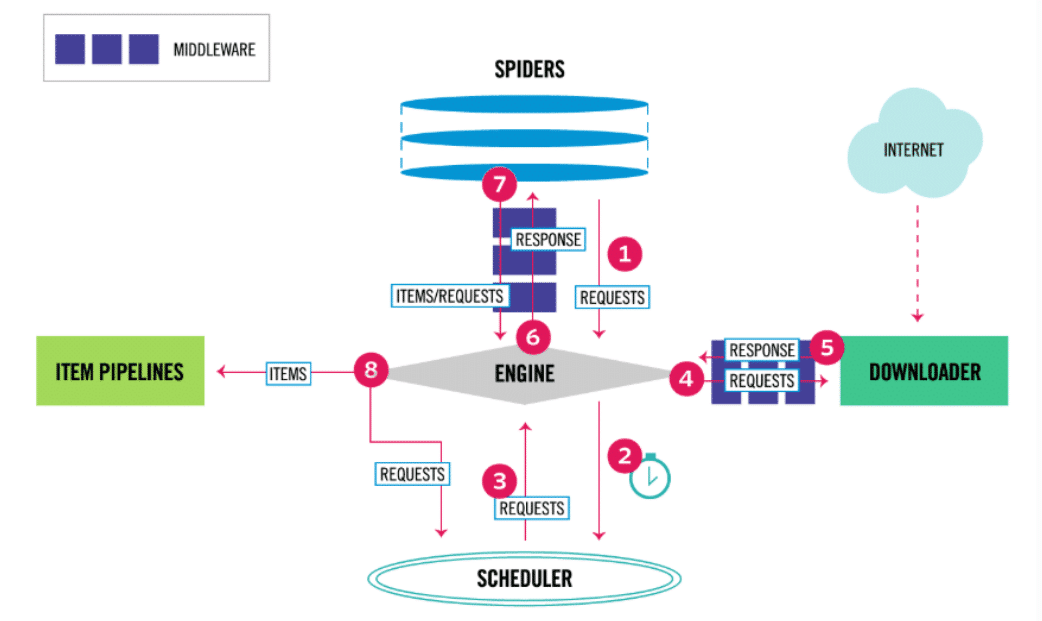
In summary, Scrapy is an incredibly versatile Python framework that excels at extracting, processing, and analyzing structured and unstructured data. Its versatility and scalability make it an excellent choice for various applications across multiple industries.