Data preprocessing in Python CSV
Data preprocessing in Python CSV
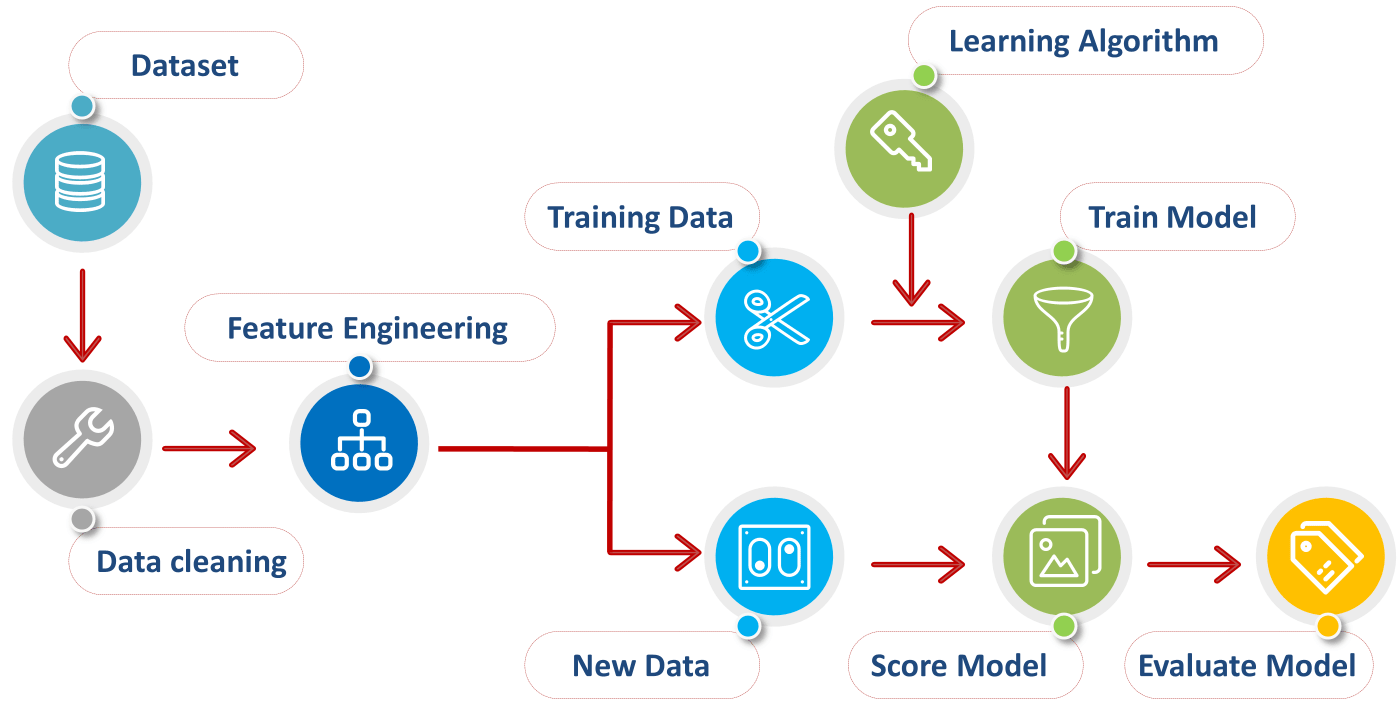
I'm happy to help you with that!
Data Preprocessing in Python using CSV
CSV (Comma Separated Values) files are a common format for storing tabular data. However, they can become unmanageable if not properly preprocessed. In this response, I'll guide you through the steps of preprocessing a CSV file using Python.
Step 1: Import necessary libraries
import csv
import pandas as pd
We'll use the csv module to read and write CSV files, and the pandas library ( alias pd) for data manipulation and analysis.
Step 2: Load the CSV file
with open('data.csv', 'r') as csvfile:
reader = csv.reader(csvfile)
data = list(reader)
Replace 'data.csv' with the path to your CSV file. We use the open function to read the file, and then create a csv.reader object to parse the contents.
Step 3: Convert to a Pandas DataFrame
df = pd.DataFrame(data, columns=[row[0] for row in data])
The pd.DataFrame constructor takes a list of lists (our data) as input. We use a list comprehension to extract the first element of each row as column names.
Step 4: Handle missing values
Detect missing values: Use theisnull method to identify rows or columns with missing values.
print(df.isnull().sum()) # Print the number of missing values in each column
fillna method. For example, you could fill NaN values with the mean or median of that column:
df.fillna(df.mean(), inplace=True) # Fill NaN with column means
Step 5: Data cleaning and transformation
Remove duplicates: Use thedrop_duplicates method to remove duplicate rows.
df.drop_duplicates(inplace=True)
astype method to convert column types (e.g., string, integer, float).
df['column_name'] = df['column_name'].astype(str) # Convert a column to string type
Step 6: Save the preprocessed CSV file
Write the DataFrame to a new CSV file: Use theto_csv method to write the preprocessed data to a new CSV file.
df.to_csv('preprocessed_data.csv', index=False)
Replace 'preprocessed_data.csv' with the desired output file name. The index=False parameter ensures that row indices are not written to the output file.
These steps provide a solid foundation for preprocessing your CSV data in Python. Remember to adjust the code according to your specific needs and dataset characteristics.
Do you have any questions or would you like me to elaborate on these steps?
Python data preprocessing geeksforgeeks
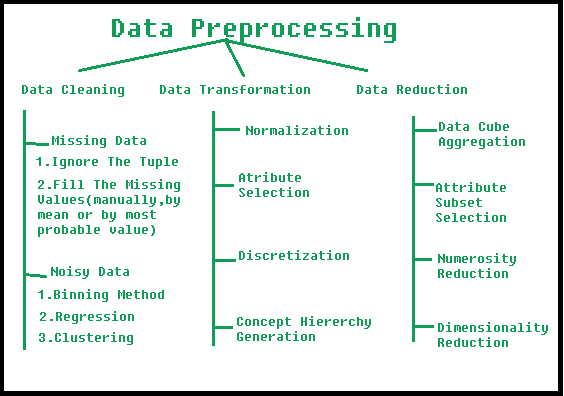
Here's a comprehensive overview of python data preprocessing for geeksforgeeks:
Data Preprocessing: The Foundation of Data Science
In the realm of data science, data preprocessing is the most crucial step that sets the tone for all subsequent steps, including modeling, visualization, and analysis. It's an art and science that requires careful attention to detail, a deep understanding of the problem domain, and proficiency in Python programming. In this article, we'll delve into the world of Python data preprocessing and explore the various techniques and tools available for geeksforgeeks.

What is Data Preprocessing?
Data preprocessing is the process of converting raw data into a format that's suitable for analysis. It involves several steps:
Handling Missing Values: Dealing with missing or null values is crucial in data preprocessing. Python offers thepandas library, which provides efficient methods to handle missing values, such as filling them with mean, median, or mode values. Data Transformation: Transforming data from one format to another can be achieved using various Python libraries like numpy, scipy, and pandas. For instance, converting categorical variables into numerical values or performing logarithmic transformations on skewed data. Handling Outliers: Identifying and addressing outliers is vital in data preprocessing. Python's scipy library offers a range of statistical techniques, such as z-score calculation and outlier detection using the Modified Z-Score method.
Python Libraries for Data Preprocessing:
Pandas: A powerful library for handling structured data, including tabular data such as spreadsheets and SQL tables. Pandas provides efficient methods for missing value handling, data transformation, grouping, and merging. NumPy: A library for performing numerical operations in Python. NumPy is essential for performing various data transformations, such as reshaping arrays, calculating statistics, and creating masks. Scipy: A scientific computing library that provides a wide range of algorithms for scientific and engineering applications. Scipy is useful for tasks like outlier detection, statistical modeling, and time-series analysis.Python Data Preprocessing Techniques:
Data Cleaning: Removing duplicates, handling missing values, and correcting errors in the data. Data Integration: Combining multiple datasets into a single cohesive dataset. Data Transformation: Converting categorical variables into numerical values or performing logarithmic transformations on skewed data. Feature Engineering: Creating new features from existing ones to improve modeling performance.Python Data Preprocessing Best Practices:
Document Your Process: Keep track of your preprocessing steps and the decisions you make along the way. Test and Validate: Verify that your preprocessing steps are working correctly and do not introduce any biases or errors. Iterate and Refine: Continuously iterate and refine your preprocessing pipeline as needed.Conclusion:
Data preprocessing is a critical step in the data science workflow. Python provides an array of libraries, techniques, and best practices to help geeksforgeeks handle raw data with precision and care. By mastering these skills, you'll be well-equipped to tackle complex data preprocessing tasks and unlock meaningful insights from your datasets. Happy coding!





























