How to read text from XML file in Python?
How to read text from XML file in Python?
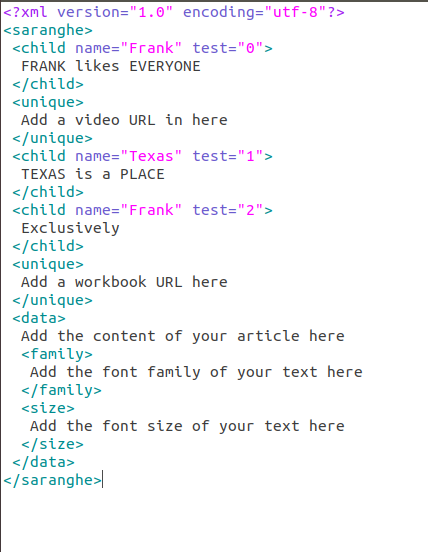
I'd be happy to explain how to read text from an XML file in Python!
Python provides several libraries that make it easy to parse and work with XML files. One popular library is xml.etree.ElementTree, which is part of the Python Standard Library.
Here's a step-by-step guide on how to use this library to read text from an XML file:
Step 1: Install the required library
If you haven't already, install the xml library by running the following command:
pip install xml.etree.ElementTree
Step 2: Load the XML file
Use the following code to load the XML file into a Python object:
import xml.etree.ElementTree as ET
tree = ET.parse('example.xml') # Replace 'example.xml' with your file name
root = tree.getroot()
In this example, ET.parse is used to load the XML file, and getroot returns the root element of the XML document.
Step 3: Find the desired text
Navigate through the XML elements using the following code:
text_node = None
for elem in root.iter():
if elem.tag == 'your_text_tag': # Replace with your actual tag name
text_node = elem.text
break
In this example, iter is used to iterate through all elements in the XML document. We're looking for an element with a specific tag name (replace 'your_text_tag' with your actual tag name). Once we find it, we set the text_node variable to its text content.
Step 4: Extract the text
Finally, extract the text from the text_node:
if text_node is not None:
print(text_node.strip()) # Print the extracted text
The strip() method removes any unnecessary whitespace characters from the extracted text.
Here's a complete example code:
import xml.etree.ElementTree as ET
tree = ET.parse('example.xml')
root = tree.getroot()
text_node = None
for elem in root.iter():
if elem.tag == 'your_text_tag':
text_node = elem.text
break
if text_node is not None:
print(text_node.strip())
Tips and Variations
If your XML file has multiple occurrences of the desired text, you may need to modify the code to handle this situation. You can usefind or findall instead of iter if you know the specific path to the element you're looking for. To extract other types of data (e.g., attributes, child elements), explore the various methods available in the ElementTree library.
I hope this helps you get started with reading text from an XML file in Python!
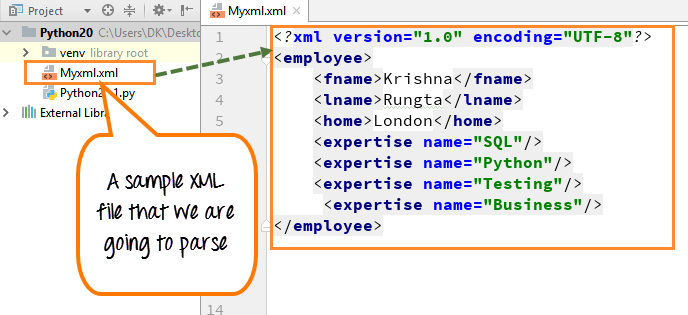
How to extract data from XML using Python?

To extract data from an XML file using Python, you can utilize the xml.etree.ElementTree module. Here's a step-by-step guide:
Step 1: Parse the XML File
First, you need to parse the XML file into a Python object. You can do this by creating an ElementTree instance and parsing the XML file:
import xml.etree.ElementTree as ET

xml_file = 'path/to/your/xml/file.xml'
tree = ET.parse(xml_file)
root = tree.getroot()
Step 2: Navigate the XML Structure
Now that you have the root element, you can navigate the XML structure using the find() or findall() methods:
# Find a specific node with the tag 'person'
person_node = root.find('.//person')
Find all nodes with the tag 'book'
book_nodes = root.findall('.//book')
Step 3: Extract Data
Once you have navigated to the desired node, you can extract the data using various methods:
Element.text: Get the text content of an element:person_name = person_node.find('name').text
print(person_name) # Output: John Doe
book_title = book_nodes[0].get('title')
print(book_title) # Output: Python Programming
author_name = person_node.find('.//author').text
print(author_name) # Output: Jane Smith
Step 4: Iterate Over Child Elements
If you need to process multiple nodes, you can use a loop to iterate over the child elements:
for book in book_nodes:
print(book.find('title').text)
print(book.find('author').text)
This will output the title and author of each book node.
Tips and Tricks
Use XPath expressions: You can use XPath expressions to navigate the XML structure more efficiently.person_node = root.find('.//person[name="John Doe"]')
find() method with a context: When finding child elements, you can specify a context node:
author_node = person_node.find('.//author', person_node)
By following these steps and tips, you should be able to extract data from an XML file using Python. Happy coding!





























