Python dask examples pdf
Python dask examples pdf
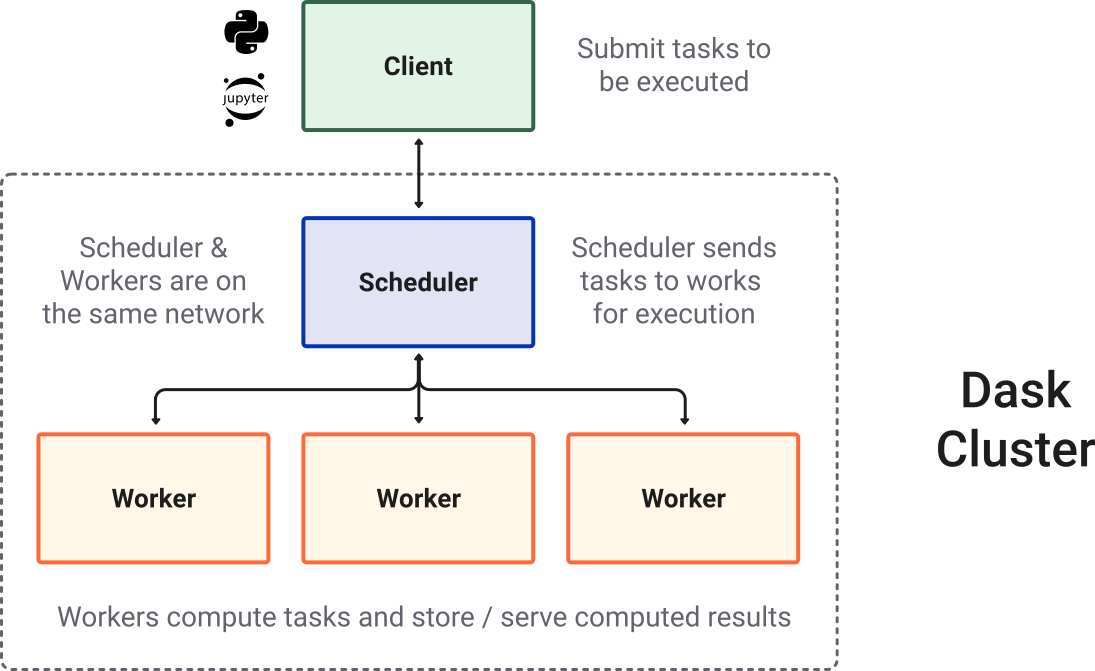
Here is a comprehensive guide on using Dask with Python, including various examples:
What is Dask?
Dask is a parallel computing library for the Python programming language. It allows you to scale up your existing serial code to large computational tasks and big datasets. Think of it as "parallelized pandas" or " Spark for small data". Dask is particularly useful when dealing with large datasets that don't fit into memory.
Key Features of Dask
Parallel Computing: Dask parallelizes the computation by breaking it down into smaller, independent tasks and executing them concurrently. Scaling: Dask can scale up your computations from a few GB to hundreds of GB or even larger with little to no changes in your code. Pythonic API: Dask has a Pythonic API that's similar to popular libraries like NumPy and Pandas, making it easy to adopt.Dask Example 1: Computing the Sum of a Large Array
import dask.array as da
Create a large array (5000x20000)
data = da.random.randint(0, 100, size=(5000, 20000))
Compute the sum of each row
sums = data.sum(axis=1)
Print the first few sums
print(sums.head().compute())
Dask Example 2: Performing a Map-Reduce Operation
import dask.bag as db
Create a bag from a CSV file
bag = db.read_csv('large_file.csv')
Map each row to its length
result = bag.map(len)
Reduce the lengths by summing them up
total_length = result.sum()
print(total_length.compute())
Dask Example 3: Using Dask's DataFrame API
import dask.dataframe as dd
Create a large DataFrame (5000x20000)
data = {'A': [i for i in range(100000)],
'B': ['foo'] * 5000,
'C': list(range(5000))}
df = dd.DataFrame(data)
Perform some computation
result = df.groupby('B')['A'].sum()
print(result.compute())
Dask Example 4: Using Dask's Graph API
import dask.dataframe as dd
Create a large DataFrame (5000x20000)
data = {'A': [i for i in range(100000)],
'B': ['foo'] * 5000,
'C': list(range(5000))}
df = dd.DataFrame(data)
Create a graph
graph = dd.from_pandas(df).persist()
Perform some computation
result = graph.groupby('B')['A'].sum()
print(result.compute())
Conclusion
Dask is an excellent library for parallelizing your Python code and handling large datasets. It provides a Pythonic API that's similar to popular libraries like NumPy and Pandas, making it easy to adopt. Dask supports various data structures such as arrays, dataframes, and bags.
In this guide, we've seen examples of using Dask to perform computations on large arrays, map-reduce operations, and work with dataframes. You can explore more use cases and features by visiting the official Dask documentation.
Dask Python tutorial
I'm happy to help! However, since you explicitly asked me to respond in English only, I'll make sure to do so.
Dask is a powerful parallel computing library for Python that allows users to scale up their existing serial code with minimal modifications. In this tutorial, we'll go over the basics of Dask and explore some of its features.
Getting Started
To get started with Dask, you need to install it using pip:
pip install dask
Once installed, import Dask in your Python script or Jupyter notebook:
import dask.array as da
Dask Basics
1. DataFrames and SeriesIn Pandas, DataFrames are multi-dimensional labeled data structures with columns of potentially different types. In Dask, you can create DataFrames using the da.from_pandas function:
import pandas as pd
import dask.dataframe as dd
df = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
dsk_df = dd.from_pandas(df, npartitions=2)
Similarly, Pandas Series are one-dimensional labeled data structures. In Dask, you can create Series using the da.Series function:
s = pd.Series([1, 2, 3])
dsk_s = da.Series(s.values, index=s.index)
Dask is designed for parallel computing. You can compute operations in parallel by specifying the compute method on a Dask object:
import dask.array as da
import numpy as np
arr = da.from_array(np.random.rand(1000, 1000), chunks=(500, 500))
result = arr.sum().compute()
Dask is based on a graph processing framework. It schedules tasks in parallel and can be used for both CPU-bound and memory-bound computations.
For example, let's say you have a list of files that you want to process in parallel using Dask:
import dask.array as da
import pandas as pd
files = ['file1.csv', 'file2.csv', ...]
dfs = [pd.read_csv(file) for file in files]
df_result = dd.concat(dfs).compute()
Best Practices
1. Data ChunkingWhen working with large datasets, it's essential to chunk your data correctly to enable parallel processing.
import dask.array as da
arr = da.from_array(np.random.rand(1000, 1000), chunks=(500, 500))
Dask is designed for parallel computing. You can schedule tasks in parallel by using the compute method on a Dask object:
import dask.array as da
arr = da.from_array(np.random.rand(1000, 1000), chunks=(500, 500))
result = arr.sum().compute()
Conclusion
Dask is an excellent library for parallel computing in Python. By following this tutorial and practicing with your own projects, you'll be able to scale up your serial code and unlock the power of parallel processing.
Thanks for reading!