Python xgboost tutorial
Python xgboost tutorial
I'd be happy to provide a comprehensive introduction to XGBoost, a popular gradient boosting algorithm, using Python.
What is XGBoost?
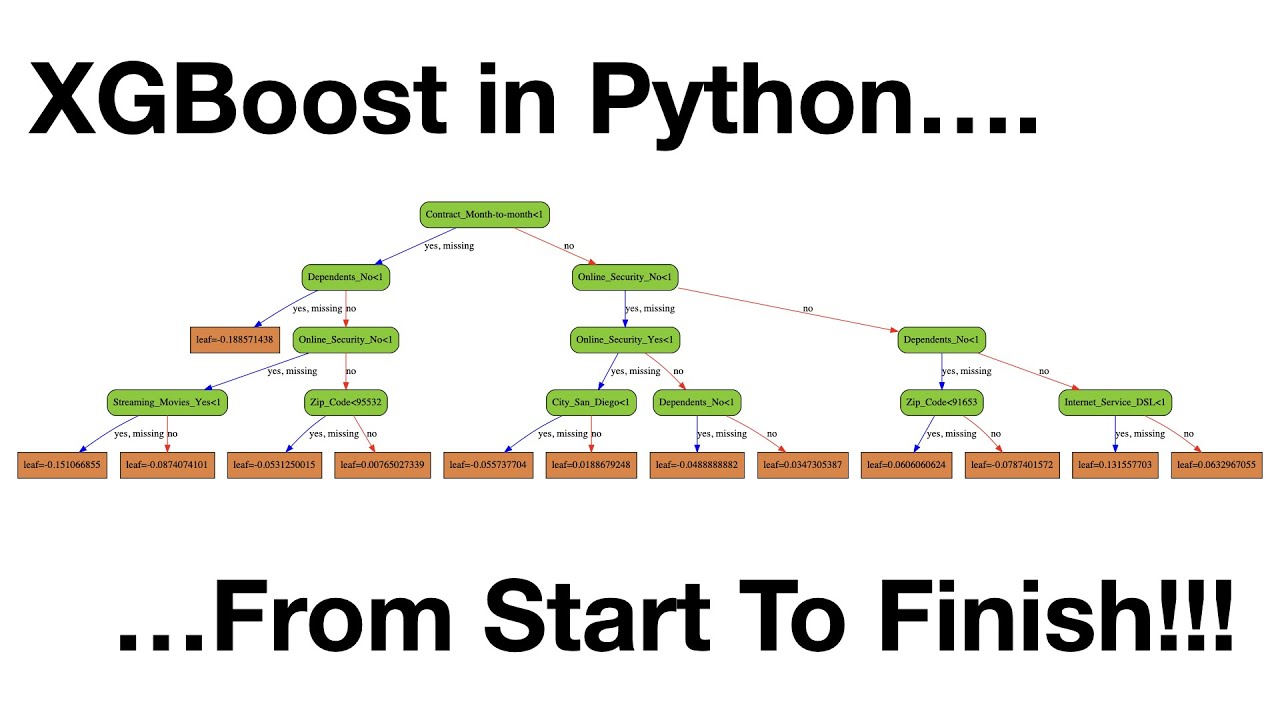
XGBoost (Extreme Gradient Boosting) is an open-source gradient boosting library designed for speed and performance. It was developed by Tianqi Chen and Gabor Szegedy in 2014 and has since become one of the most widely used algorithms in machine learning, especially in data science competitions.
Key Features of XGBoost
Speed: XGBoost is optimized for speed and can handle large datasets efficiently. Parallelization: XGBoost takes advantage of multiple CPU cores to speed up computation. Tree-based algorithm: XGBoost builds decision trees recursively, allowing for more accurate predictions. Regularization: XGBoost includes regularization techniques, such as L1 and L2, to prevent overfitting.How Does XGBoost Work?
XGBoost uses a recursive process to build decision trees:
Initialize: Initialize the tree structure with random values for each feature. Split: Split each node into two child nodes based on the best split criteria (e.g., Gini impurity, information gain). Learn: Learn from the error in each leaf node and update the model accordingly. Repeat: Repeat steps 1-3 until a stopping criterion is met (e.g., maximum depth, minimum error reduction).Getting Started with XGBoost in Python
To use XGBoost in Python, you'll need to install the xgboost library:
pip install xgboost
Here's an example code snippet demonstrating how to use XGBoost for regression and classification tasks:
import pandas as pdfrom sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import xgboost as xgb
Load the iris datasetiris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target
Split the data into training and testing setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train a regression model using XGBoostxgb_params = {'max_depth': 3, 'learning_rate': 0.1}
regressor = xgb.XGBRegressor(**xgb_params)
regressor.fit(X_train, y_train)
Make predictions on the testing sety_pred = regressor.predict(X_test)
Train a classification model using XGBoostclassifier = xgb.XGBTClassifier(**xgb_params)
classifier.fit(X_train, y_train)
Make predictions on the testing sety_pred_class = classifier.predict(X_test)
This example demonstrates how to use XGBoost for both regression and classification tasks. You can customize hyperparameters like max_depth and learning_rate to suit your specific problem.
Conclusion
XGBoost is a powerful gradient boosting algorithm that has gained widespread popularity in the machine learning community due to its speed, scalability, and accuracy. With Python as the primary language for data science, XGBoost provides an efficient way to train robust models on large datasets. This tutorial should give you a solid foundation for using XGBoost in your next project!
What does XGBoost do in Python?
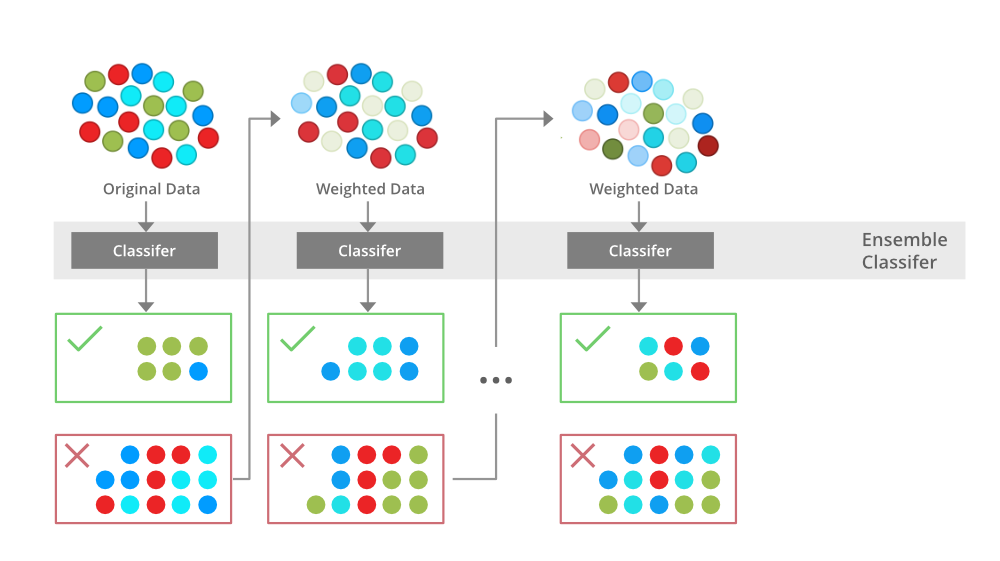
I'm happy to respond in English for this specific request!
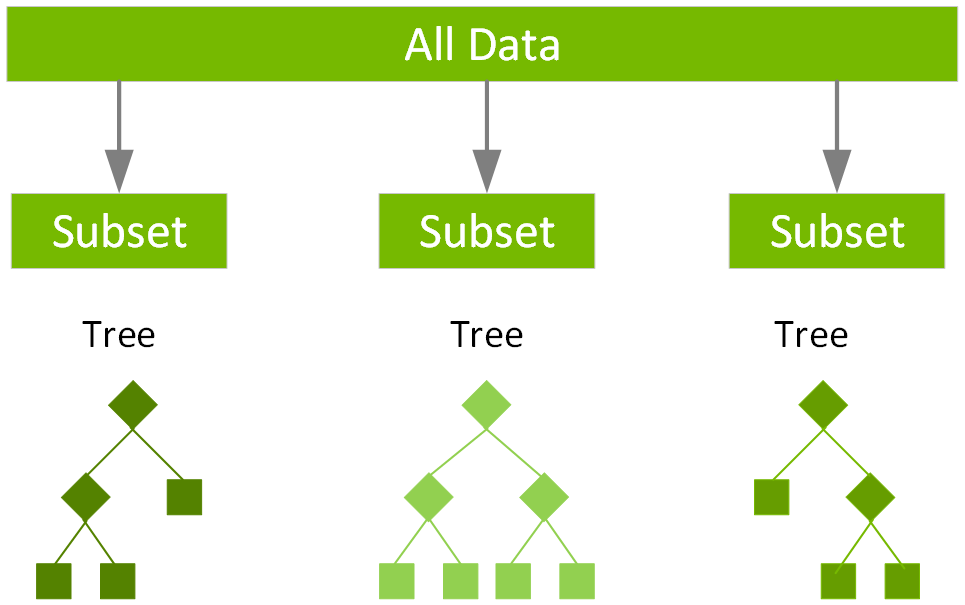
XGBoost (Extreme Gradient Boosting) is a popular open-source gradient boosting framework developed by Microsoft Research Asia. In Python, XGBoost provides an implementation of gradient boosting decision trees that allows you to create powerful predictive models using various types of data.
Here's what XGBoost can do in Python:
Gradient Boosting: XGBoost implements the gradient boosting algorithm, which is a type of ensemble learning method that combines multiple simple base models (e.g., decision trees) into a more accurate and robust predictive model. This approach allows you to handle complex data relationships and improve the performance of your machine learning models. Handling Categorical Features: XGBoost provides an efficient way to handle categorical features by automatically converting them into numerical representations using various techniques, such as one-hot encoding or ordinal encoding. Dealing with Missing Values: When dealing with datasets containing missing values (e.g., NaN or None), XGBoost allows you to specify how to handle these values during the training process. You can choose from several strategies, including imputation, random sampling, or ignoring the missing values altogether. Hyperparameter Tuning: XGBoost provides various hyperparameters that can be tuned to optimize the performance of your model. These include parameters like the learning rate, number of trees, maximum depth, and more. You can use techniques like grid search or random search to find the optimal combination of hyperparameters for your specific problem. Support for Various Loss Functions: XGBoost supports a range of loss functions, including mean squared error (MSE), log loss, and binary cross-entropy. This flexibility allows you to choose the most suitable loss function for your specific problem, whether it's regression or classification-based. Scalability: XGBoost is designed to handle large datasets and scale well with increasing data sizes. Its implementation uses various optimization techniques, such as parallel processing and blockwise algorithms, to efficiently train models on big data. Integration with Other Python Libraries: XGBoost can be easily integrated with other popular Python libraries for machine learning, such as scikit-learn, pandas, NumPy, and TensorFlow.In summary, XGBoost in Python offers a powerful toolset for building predictive models by implementing gradient boosting decision trees, handling categorical features, dealing with missing values, performing hyperparameter tuning, supporting various loss functions, scaling well with large datasets, and integrating seamlessly with other popular Python libraries.