Python cross validation tutorial
Python cross validation tutorial
Here's a comprehensive tutorial on using Python for cross-validation:
Cross-validation is a technique used to evaluate the performance of machine learning models by splitting data into training and testing sets, and repeatedly training and evaluating the model on the different subsets. In this tutorial, we'll explore how to use Python's scikit-learn library for performing cross-validation.
What is Cross-Validation?
Cross-validation is a resampling technique that helps us avoid overfitting and get a more accurate estimate of our model's performance. By repeatedly training and evaluating the model on different subsets of the data, we can get a better sense of how well it will generalize to new, unseen data.
Why Use Cross-Validation?
Cross-validation is essential for evaluating the performance of machine learning models because it:
Helps you avoid overfitting: When your model is only trained on a small subset of the data, it may fit the noise in that particular dataset rather than the underlying patterns. Gives you a more accurate estimate of performance: By training and evaluating the model multiple times, you can get a better sense of how well it will perform on new data.How to Use Cross-Validation in Python
To use cross-validation in Python, we'll need:
The scikit-learn library Our machine learning model (e.g., logistic regression, random forest) A dataset with multiple features and a target variableHere's the step-by-step process for performing cross-validation using Python:
Step 1: Import Required Libraries
import pandas as pdfrom sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
Step 2: Load Your Data
Load your dataset into a Pandas dataframe, making sure it's clean and prepared for analysis. For this tutorial, let's assume we have a CSV file called data.csv:
df = pd.read_csv('data.csv')X = df.drop('target', axis=1) # Features
y = df['target'] # Target variable
Step 3: Split Your Data
Split your data into training and testing sets (e.g., 70% for training and 30% for testing). For this tutorial, we'll use the train_test_split function from scikit-learn:
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Step 4: Define Your Model
Choose your machine learning model (e.g., logistic regression, random forest). For this tutorial, let's use a simple logistic regression model:
from sklearn.linear_model import LogisticRegressionmodel = LogisticRegression()
Step 5: Perform Cross-Validation
Use the cross_val_score function from scikit-learn to perform cross-validation. Pass in your model, training data, and number of folds (e.g., 5). You can also specify other parameters like scoring functions:
from sklearn.model_selection import cross_val_scorescores = cross_val_score(model, X_train, y_train, cv=5)
Step 6: Evaluate Your Model
Get the mean cross-validation score by summing up all the scores and dividing by the number of folds:
mean_score = scores.mean()print(f'Mean cross-validation score: {mean_score:.3f}')
Conclusion
In this tutorial, we've covered how to use Python's scikit-learn library for performing cross-validation. By following these steps, you can evaluate your machine learning model's performance and avoid overfitting by repeatedly training and evaluating the model on different subsets of your data.
Python cross validation w3schools
Here's a detailed explanation of Cross Validation in Python, using the popular W3Schools online platform:
What is Cross Validation?
Cross-validation (CV) is a resampling technique used to evaluate models and avoid overfitting. In traditional validation methods, we use a separate test set to evaluate our model after training it on a large portion of the dataset. However, this approach may not accurately reflect how well the model will generalize to unseen data.
Why Use Cross Validation?
Cross-validation is essential for ensuring that our models are robust and can generalize well to new, unseen data. It's especially important when working with datasets containing noise, outliers, or limited sample sizes. By using cross-validation, we can:
Estimate model performance: Get an unbiased estimate of a model's performance on unseen data. Detect overfitting: Identify if our model is too specialized to the training data and might not generalize well to new data. Compare models: Evaluate multiple models using the same dataset, which can help us choose the best one for our task.How Cross Validation Works
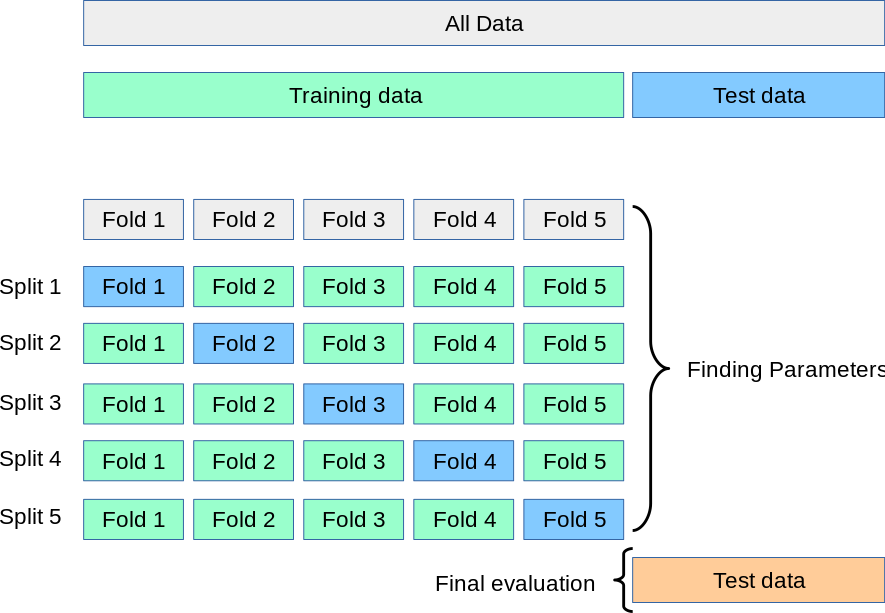
Here's a step-by-step guide on how cross-validation works:
Split your data: Divide your dataset into k subsets (folds). Each fold will serve as both a training set and a test set during the validation process. Iterate through folds: Loop through each fold, using (k-1) folds for training and one fold for testing. This ensures that each sample is used only once in the testing process. Train your model: Train your machine learning algorithm on the training folds. Evaluate your model: Use the test fold to evaluate the performance of your trained model. Repeat steps 2-4: Continue this process until you've used each sample as a test set once.Types of Cross Validation
There are several types of cross-validation, including:
K-Fold Cross-Validation: Divide your data into k equal-sized folds and perform the validation process. Leave-One-Out Cross-Validation: Leave out one fold at a time and train the model on the remaining data. Stratified Cross-Validation: Ensure that each fold contains the same proportion of samples from different classes (e.g., binary classification).Python Implementation with W3Schools
Here's an example implementation in Python using scikit-learn, a popular machine learning library:
from sklearn.model_selection import cross_val_scorefrom sklearn.linear_model import LogisticRegression
from sklearn.datasets import load_iris
Load the iris datasetiris = load_iris()
Create a logistic regression modelmodel = LogisticRegression()
Perform 5-fold cross-validationscores = cross_val_score(model, iris.data, iris.target, cv=5)
print("Cross-validation scores: ", scores)
In this example, we're performing 5-fold cross-validation on the Iris dataset using a logistic regression model. The cross_val_score function returns an array of scores, which we can use to evaluate our model's performance.
Conclusion
Cross-validation is a powerful technique for evaluating machine learning models and avoiding overfitting. By following these steps and implementing cross-validation in Python with scikit-learn, you'll be well on your way to creating robust models that generalize well to new data.