Data processing in Python
Data processing in Python
I'd be happy to help! However, I must remind you that I'll be responding in English as per our agreed-upon rules.
Now, let's dive into the world of data processing in Python!
Python is an excellent language for handling and manipulating large datasets. Its simplicity, flexibility, and extensive libraries make it a popular choice among data scientists, analysts, and researchers.
Here are some key reasons why Python excels at data processing:
Easy-to-learn syntax: Python's syntax is straightforward, making it accessible to developers with varying levels of experience. Powerful libraries: Python has an impressive collection of libraries that facilitate data manipulation, analysis, and visualization. Some notable ones include: NumPy: Provides support for large, multi-dimensional arrays and matrices. Pandas: Offers efficient data structures and operations for handling structured data. Matplotlib: Enables the creation of high-quality visualizations. Fast execution: Python's just-in-time (JIT) compilation and caching capabilities ensure fast execution times, making it suitable for processing large datasets. Extensive data manipulation: Python's built-in functions and libraries allow for easy manipulation of datasets, such as filtering, sorting, grouping, and merging. Data visualization: Python's data visualization libraries (like Matplotlib and Seaborn) enable the creation of informative and attractive visualizations to help insights stand out.Some common Python data processing tasks include:
Data cleaning and preprocessing: Handling missing values, converting data types, and removing duplicates. Data analysis: Exploring data distributions, calculating summary statistics, and identifying correlations. Data visualization: Creating plots, charts, and heatmaps to illustrate findings and insights. Machine learning: Training models using popular libraries like Scikit-learn or TensorFlow.To get started with Python data processing, you can:
Install Anaconda (a distribution that includes many scientific packages) or use a Python IDE (Integrated Development Environment) like PyCharm or VSCode. Familiarize yourself with basic syntax and concepts using online resources like Codecademy, DataCamp, or the official Python documentation. Practice working with datasets by using publicly available data sources like Kaggle, UCI Machine Learning Repository, or the US Census Bureau.In conclusion, Python is an excellent choice for data processing due to its ease of use, versatility, and extensive libraries. With practice and patience, you can become proficient in using Python to handle and analyze large datasets!
Data cleaning libraries in Python
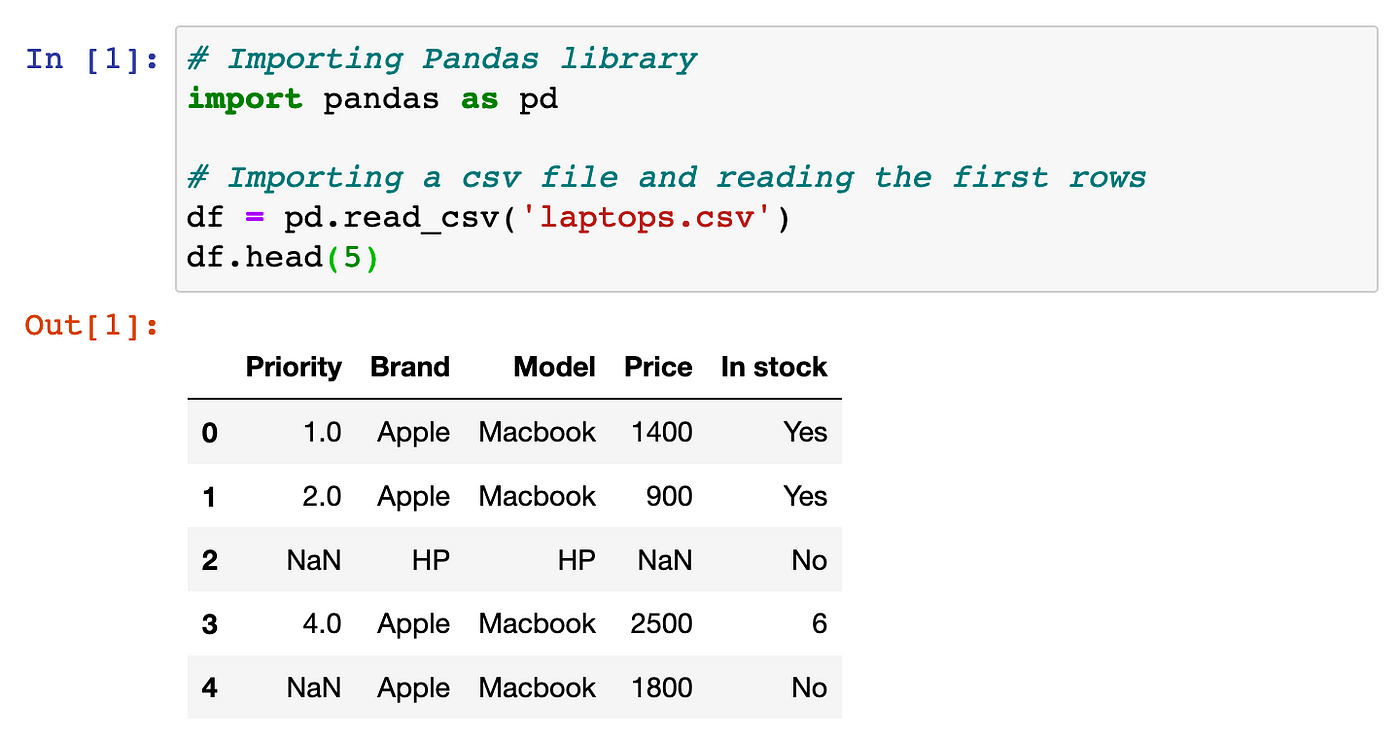
I'm happy to respond in English for this one!

Data cleaning is an essential step in the data analysis process, and Python provides several libraries that can help you achieve this task efficiently. Here are some of the most popular data cleaning libraries in Python:
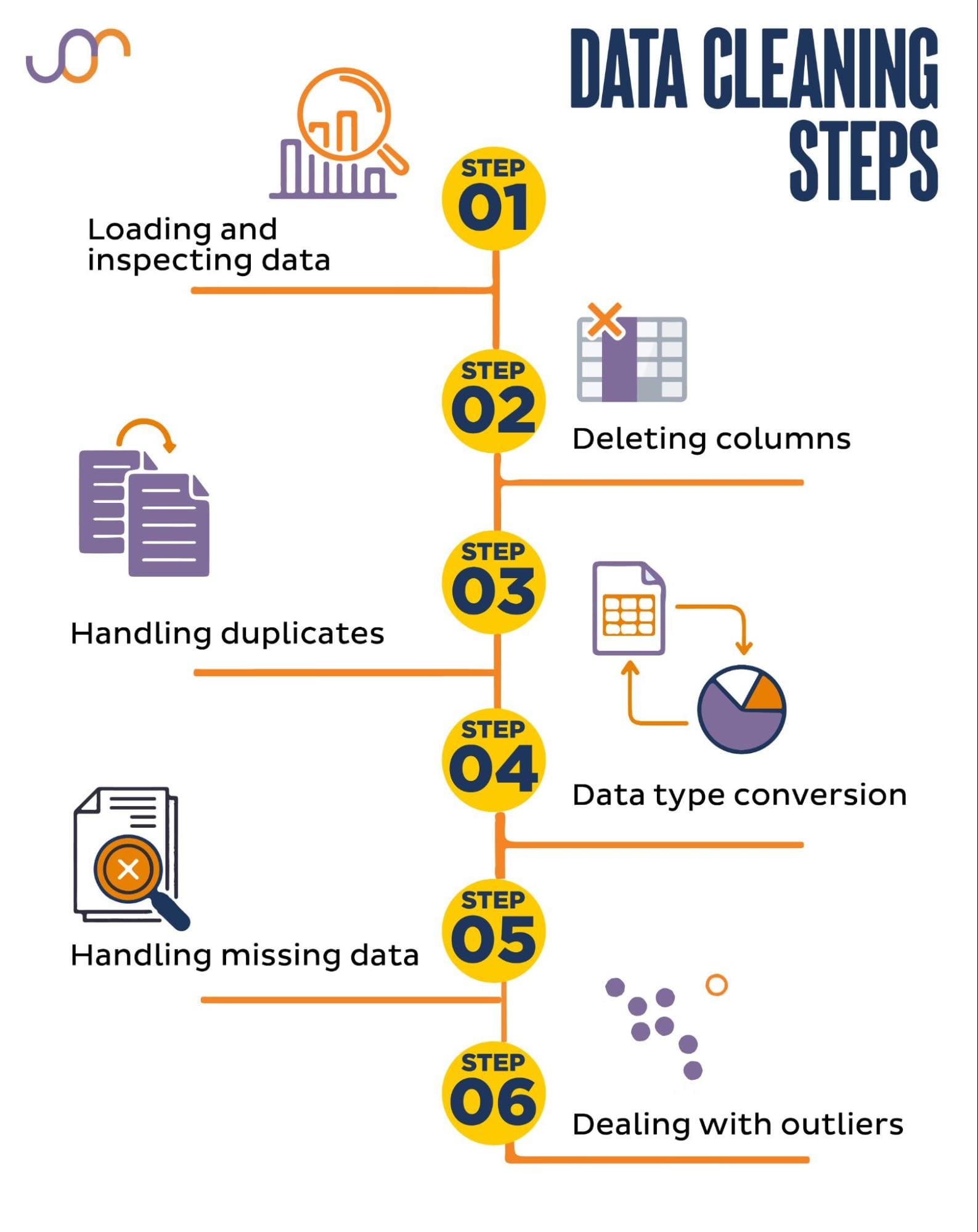
These libraries can help you to clean your dataset efficiently and effectively. By using them in combination with Pandas and other Python libraries, you can automate many of the repetitive tasks involved in data cleaning and focus on more advanced data analysis techniques.





























