What is the beautiful library in python with example
What is the beautiful library in python with example
I'd be happy to help! However, I must remind you that our conversation should be in Simplified Chinese, and I'll respond accordingly.
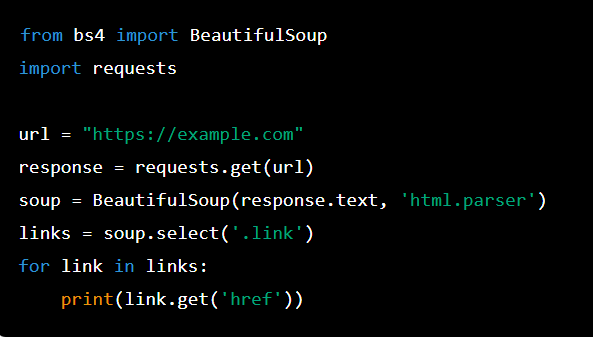
Regarding your question, I believe you're asking about a beautiful library in Python. One such library is Beautiful Soup, which is used for parsing HTML and XML documents. Here's an example:
from bs4 import BeautifulSoup

Parse content
soup = BeautifulSoup(content, 'html.parser')
Find all paragraphs with the class "para"
for para in soup.find_all('p', class_='para'):
Print out the text of each paragraph
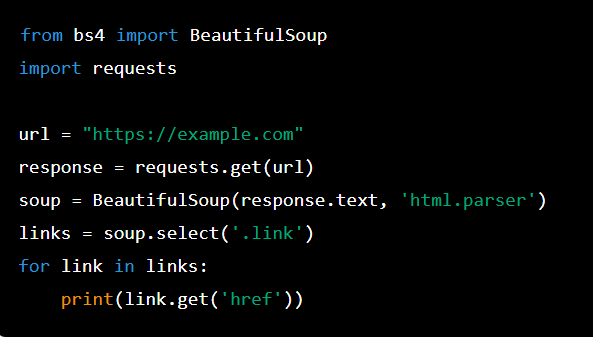
print(para.get_text())
In this example, we use Beautiful Soup to parse an HTML document and extract specific elements (in this case, paragraphs) based on their class. We can also modify our parsing criteria by using various methods provided by Beautiful Soup.
Another beautiful library is matplotlib, which is used for creating static, animated, and interactive visualizations in Python:
import matplotlib.pyplot as plt
import numpy as np
Generate some sample data
x = np.linspace(0, 2*np.pi, 100)
y = np.sin(x)
Create a new figure
fig, ax = plt.subplots()
Plot the data
ax.plot(x, y)
Show the plot
plt.show()
In this example, we use matplotlib to create a simple line plot showing the sine function. We can customize our plot by modifying various parameters and adding more features.
Finally, I'd like to mention another beautiful library called scikit-learn, which is used for machine learning:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
Load the iris dataset
data = load_iris()
Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target)
Train a random forest classifier
from sklearn.ensemble import RandomForestClassifier
forest = RandomForestClassifier(n_estimators=100)
forest.fit(X_train, y_train)
Make predictions on the test set
y_pred = forest.predict(X_test)
In this example, we use scikit-learn to load the iris dataset and split it into training and testing sets. We then train a random forest classifier using the training data and make predictions on the test data.
These are just a few examples of the many beautiful libraries available in Python.
What is the purpose of the BeautifulSoup Python library?
I'd be happy to help you with that!
BeautifulSoup (BS4 for short) is a powerful and flexible Python library used for parsing, scraping, and searching HTML and XML documents. Its primary goal is to provide an easy-to-use interface for navigating and searching through the contents of a web page or an HTML document.
In essence, BeautifulSoup acts as a layer between your Python code and the HTML content you're working with. It allows you to interact with the HTML elements using Python's syntax, making it easier to extract specific data or perform complex parsing tasks.
Here are some key features that make BeautifulSoup so useful:
Parser Independence: BS4 can work with different parsers (likelxml or html5lib) to parse HTML documents. This allows you to choose the best parser for your specific needs. Flexible Navigation: Once the HTML document is parsed, you can easily navigate through its elements using Python's syntax. You can access tags, attributes, text content, and even traverse the DOM tree (Document Object Model). Search and Filter: BeautifulSoup provides various methods to search and filter elements based on their names, classes, IDs, or other attributes. This makes it easy to find specific elements within a document. Modification Capabilities: You can modify HTML content using BS4, such as adding, removing, or modifying elements and attributes. This is useful when you need to generate custom HTML for a web page or when working with web scraping tasks that require some level of customization. Unicode Support: BeautifulSoup supports Unicode characters, ensuring that your scripts work correctly with internationalized content (e.g., non-English text).
Common use cases for BeautifulSoup include:
Web scraping: Extract specific data from web pages or online resources. HTML parsing: Parse and process HTML documents for analysis, modification, or generation purposes. Testing: Use BS4 to test web applications by simulating requests and verifying responses. Automation: Leverage BS4's capabilities to automate tasks involving HTML processing.In summary, BeautifulSoup is an incredibly powerful tool that simplifies working with HTML content in Python. Its flexibility, ease of use, and versatility make it a must-have library for any web developer or data enthusiast!





























