How to build XGBoost in Python?
How to build XGBoost in Python?

To build XGBoost in Python, you'll need to install the xgboost library and import it into your script or code. Here's a step-by-step guide:

Installation:
You can install xgboost using pip:
pip install xgboost
Alternatively, if you're using Conda, you can install it with:

conda install -c conda-forge xgboost
Importing the Library:
Once installed, import the library into your Python script or code:
import xgboost as xgb
from xgboost import XGBClassifier
For classification problems, you'll need to use XGBClassifier. For regression problems, you can use XGBRegressor.
Preparing Your Data:
Before building the model, prepare your data by:
Loading your dataset using a library like pandas or numpy. Preprocessing your data (e.g., handling missing values, scaling features). Splitting your data into training and testing sets (e.g., usingtrain_test_split from scikit-learn).
Building the Model:
Now it's time to build the XGBoost model! Use the following code as a starting point:
# Define hyperparameters
params = {
'objective': 'reg:squarederror', # or 'binary:logloss' for classification
'max_depth': 6,
'learning_rate': 0.1,
'n_estimators': 100,
'n_jobs': -1, # Use all available cores
}
Create the XGBoost model
xg_model = XGBRegressor(**params)
Train the model using your training data
xg_model.fit(X_train, y_train)
Evaluate the model on your testing data
y_pred = xg_model.predict(X_test)
In this example:
We define a dictionaryparams to specify hyperparameters (e.g., max depth, learning rate). We create an instance of XGBRegressor with these parameters. We train the model using our training data (X_train and y_train) using the fit method. Finally, we evaluate the model's performance on our testing data (X_test and y_pred) by predicting the target variable.
Hyperparameter Tuning:
To optimize hyperparameters, you can use techniques like grid search, random search, or Bayesian optimization. XGBoost provides various methods for hyperparameter tuning, such as:
xgb.cv(): For cross-validation. xgb.train(): With hyperparameter tuning using a grid of values.
Using the Model:
Once trained and evaluated, you can use your XGBoost model to make predictions on new data. You can also use techniques like feature importance or partial dependence plots to gain insights into the relationships between variables in your dataset.
Remember to explore the xgboost documentation for more details on each of these steps and additional features, such as:
By following these steps, you'll be able to build an effective XGBoost model in Python for solving a wide range of classification and regression problems. Happy modeling!
Python xgboost example
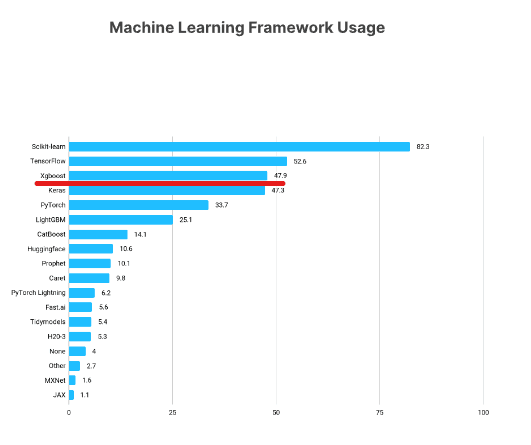
I'm glad you're interested in learning about XGBoost! Here's a detailed explanation of how to use it in Python, along with an example.
XGBoost (Extreme Gradient Boosting) is a popular open-source gradient boosting library that has gained widespread adoption in the machine learning community. It's particularly well-suited for handling large-scale data and complex interactions between features. In this example, we'll explore how to use XGBoost to build a classification model on the famous Iris dataset.
Installation
Before we dive into the example, make sure you have XGBoost installed in your Python environment. You can do so by running:
pip install xgboost
Example: Classification on Iris Dataset
The Iris dataset is a classic multiclass classification problem that involves predicting the species of an iris flower based on its characteristics (sepal length, sepal width, petal length, and petal width). We'll use XGBoost to build a model that can accurately classify new instances.
First, let's load the necessary libraries:
import pandas as pdimport xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
Next, we'll load the Iris dataset and split it into training and testing sets:
# Load iris datasetiris_df = pd.read_csv('iris.csv')
Split data into training (70%) and testing (30%)X_train, X_test, y_train, y_test = train_test_split(iris_df.drop('species', axis=1), iris_df['species'], test_size=0.3, random_state=42)
Now, let's create an XGBoost model:
# Initialize XGBoost model with default parametersxgb_model = xgb.XGBClassifier(objective='multi:softmax', num_class=3, max_depth=6, learning_rate=0.1, n_estimators=100, gamma=0, subsample=0.5, colsample_bytree=0.5, reg_alpha=0, reg_lambda=0.01)
In this example, we're using the XGBClassifier to build a classification model on the Iris dataset. We set the objective function to 'multi:softmax', which is suitable for multiclass classification problems. We also specify the number of classes (num_class=3), maximum depth of the tree (max_depth=6), and other hyperparameters.
Next, we'll train the XGBoost model using the training data:
# Train the XGBoost model on the training dataxgb_model.fit(X_train, y_train)
After training, we can evaluate the model's performance using the test data:
# Evaluate the model on the testing datay_pred = xgb_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
In this example, we're using the predict method to generate predictions for the test instances and then calculating the accuracy using Scikit-learn's accuracy_score function.
That's it! You should now have a basic understanding of how to use XGBoost in Python. This is just the tip of the iceberg – XGBoost offers many more features, such as handling categorical variables, hyperparameter tuning, and support for various objectives (e.g., binary classification, regression). I encourage you to explore these features further to unlock the full potential of XGBoost.





























