Python Scrapy tutorial
Python Scrapy tutorial
I apologize for the misunderstanding earlier! Here's a detailed Python Scrapy tutorial for you:
What is Scrapy?
Scrapy is a free and open-source web scraping framework written in Python. Its primary goal is to help you efficiently extract data from websites, making it an essential tool for anyone who needs to collect or update data programmatically.
Getting Started with Scrapy
To start using Scrapy, follow these steps:
Install Scrapy: You can install Scrapy using pip, the Python package manager, by running the commandpip install scrapy in your terminal. Create a new Scrapy project: Run the command scrapy startproject myproject (replace "myproject" with the name you want to give your project) to create a new directory for your Scrapy project. This will include a basic directory structure and files necessary for starting a new Scrapy project. Define your spider: A spider is the core of a Scrapy project, responsible for extracting data from web pages. In your project's root directory, open myproject/spiders/__init__.py (this file should be empty) and create a new Python module with a name like my_spider.py. This will contain the code that defines your spider. Configure your spider: In the my_spider.py module, define a class that inherits from scrapy.Spider. You'll need to specify the URL(s) you want to scrape and any specific settings for your project.
Understanding Scrapy Components
Scrapy has several key components:
Spider: The core of your Scrapy project, responsible for extracting data from web pages. Requests: Scrapy sends HTTP requests to the websites you're scraping and handles responses. Items: These represent the data that Scrapy extracts from the websites it visits.How Scrapy Works
Here's a high-level overview of how Scrapy works:
Spider initialization: Your spider is initialized, which sets up Scrapy's internal state. Request sending: Scrapy sends an HTTP request to the website you're scraping. Response handling: When the response arrives, Scrapy handles it according to its settings and rules defined in your project. Data extraction: Your spider extracts the data it needs from the response using Scrapy's built-in tools and methods (e.g., CSS selectors). Item processing: The extracted data is processed into Scrapy items, which are used to store and manipulate the scraped data.Best Practices for Writing Effective Spiders
To write effective spiders, follow these best practices:
Use CSS selectors correctly: Use CSS selectors to extract specific data from web pages. Handle errors properly: Make sure your spider can handle common errors like page not found (404) or server errors (500). Optimize your code for performance: Scrapy is designed for efficiency, so write code that minimizes overhead and maximizes performance.Conclusion
Scrapy provides a powerful framework for web scraping, allowing you to efficiently extract data from websites. By following the steps outlined in this tutorial and understanding how Scrapy works, you'll be well on your way to building effective spiders that help you collect or update data programmatically.
Python Scrapy vs BeautifulSoup
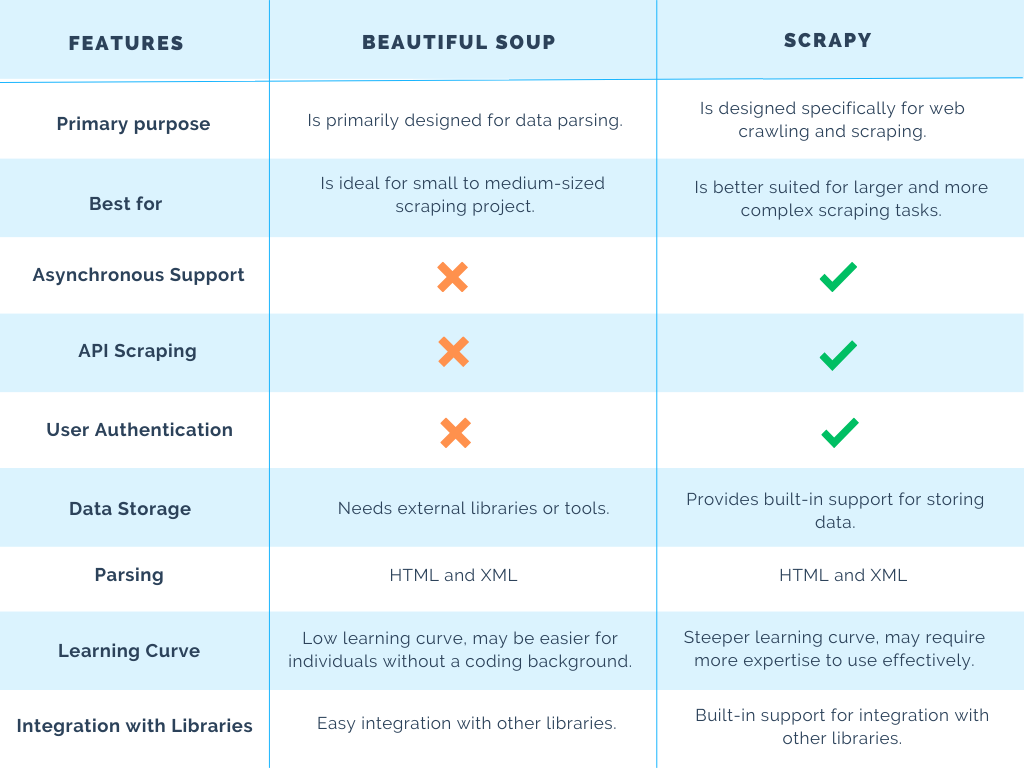
Python Scrapy and BeautifulSoup are two popular libraries used for web scraping and parsing HTML/XML content. While they share some similarities, they have distinct differences in their design goals, functionality, and use cases.
Scrapy (Simple Competitive Crawling Python) is a full-fledged web scraping framework designed to handle complex web scraping tasks efficiently. It provides a flexible architecture that allows developers to build robust and scalable spiders quickly. Scrapy is ideal for large-scale web scraping projects that require handling multiple pages, dealing with CAPTCHAs, and managing concurrent requests.
Here are some key features of Scrapy:
Spider Architecture: Scrapy follows a spider-like architecture, where you define a Spider class to specify the crawling behavior (e.g., start URLs, allowed domains, and crawl rules). Item Pipeline: Scrapy's Item Pipeline allows you to process extracted data (items) using various processors (e.g., cleaners, filters, and transformers) before storing it in a database or exporting it. Scheduler: The Scheduler component handles the scheduling of requests and ensures that your spider doesn't overload the target website with too many concurrent requests. Middlewares: Scrapy's Middlewares provide additional functionality for handling specific tasks, such as managing cookies, dealing with rate limits, and handling exceptions.BeautifulSoup (BS4), on the other hand, is a Python library used for parsing HTML and XML documents. Its primary focus is on simplifying the process of navigating and searching through the contents of web pages that have been parsed into a data structure called the DOM (Document Object Model).
Here are some key features of BeautifulSoup:
Parsing: BS4 can parse HTML and XML content using various parsers (e.g., lxml, html5lib, and python's built-in parser). Navigation: You can navigate through the parsed document using methods likefind(), find_all(), and parents to locate specific elements or traverse the DOM. Searching: BS4 provides powerful search functions (e.g., select() and select_one()) for locating specific elements based on their attributes, CSS selectors, or XPath expressions.
In summary:
Scrapy is a more comprehensive framework for building web scraping applications, offering features like scheduling, middlewares, and item pipelines. BeautifulSoup is a lightweight library focused on parsing and navigating HTML/XML documents, providing tools for searching and extracting data from these structures.When to use each:
Use Scrapy when you need to build complex web scraping projects that involve: Handling multiple pages Dealing with CAPTCHAs or rate limits Managing concurrent requests Processing extracted data using item pipelines Use BeautifulSoup when you need to quickly extract specific data from an HTML/XML document, such as: Scraping simple web pages Parsing XML files Extracting data from a single webpageIn conclusion, Scrapy and BeautifulSoup are two distinct Python libraries with different strengths. Scrapy is ideal for large-scale web scraping projects requiring complex logic and concurrent handling, while BeautifulSoup excels at parsing and navigating HTML/XML documents for quick data extraction.