Python concurrent futures
Python concurrent futures
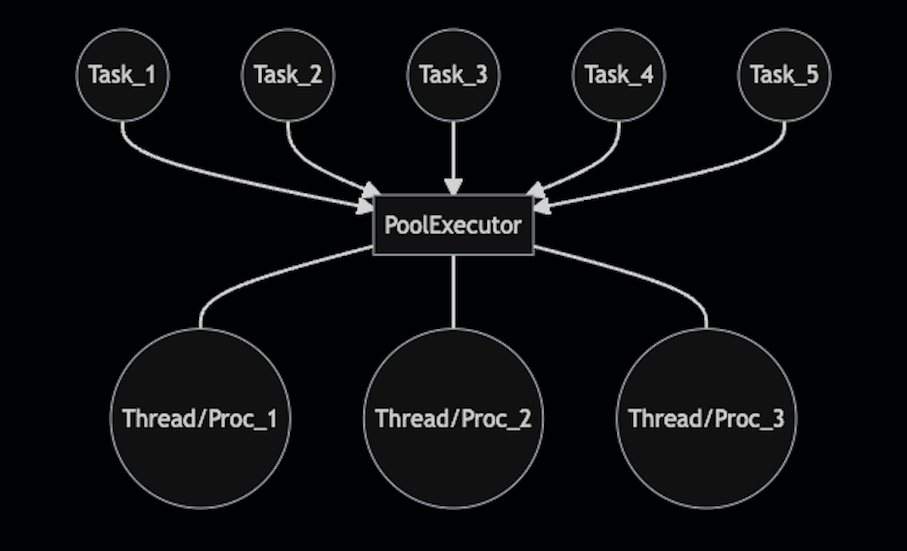
Here's an overview of Python concurrent futures:
Python provides a convenient way to handle concurrency using the concurrent.futures module, which was introduced in Python 3.2. This module allows you to easily parallelize and execute asynchronous tasks.
What is concurrent.futures?
The concurrent.futures module is a high-level interface for asynchronously executing callables. It provides a way to schedule the execution of multiple tasks concurrently and collect their results.
When should I use concurrent.futures?
You should consider using concurrent.futures in situations where you have:
concurrent.futures can help you execute them concurrently. I/O-bound operations: If your tasks involve I/O operations (e.g., reading or writing files, making network requests), concurrent.futures can help you utilize the system's resources more effectively by executing multiple tasks at once. CPU-bound operations: If your tasks are CPU-bound and you want to take advantage of multi-core processors, concurrent.futures can help you parallelize your code.
How does concurrent.futures work?
The concurrent.futures module provides two main classes:
ThreadPoolExecutor, but it uses processes instead of threads.
To use concurrent.futures, you create an instance of one of these classes and then submit tasks (functions) for execution using its submit() method. The tasks will be executed asynchronously, and the results can be collected using the result() or done() methods.
Here's a simple example:
import concurrent.futures
import time
def task(x):
print(f"Task {x} started")
time.sleep(2)
print(f"Task {x} finished")
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
for i in range(5):
executor.submit(task, i)
print("Main thread finished")
In this example, we create a ThreadPoolExecutor with 3 worker threads and submit 5 tasks (functions) to be executed concurrently. The tasks print a message indicating when they start and finish.
Benefits of using concurrent.futures
Using concurrent.futures can bring several benefits:
concurrent.futures provides a high-level interface that simplifies the process of managing concurrency in your code. Easy debugging: With concurrent.futures, you can easily debug your concurrent code by printing log messages or using logging libraries.
Overall, concurrent.futures is a powerful and convenient way to handle concurrency in Python, making it easier for developers to write efficient and scalable programs.
Python concurrent programming examples
I'm happy to help! Here are some Python concurrent programming examples for you:
Example 1: Simple Concurrent Execution
In this example, we'll use the concurrent.futures module to execute two tasks concurrently:
import concurrent.futuresimport time
def task1():
print("Task 1 started")
time.sleep(2)
print("Task 1 finished")
def task2():
print("Task 2 started")
time.sleep(3)
print("Task 2 finished")
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = [executor.submit(task1), executor.submit(task2)]
for future in concurrent.futures.as_completed(futures):
future.result()
This code creates a thread pool and submits two tasks to it. The as_completed function is used to get the results of the completed tasks.
Example 2: Concurrent Execution with Multiple Threads
In this example, we'll create multiple threads using the threading module:
import threadingdef worker(thread_id):
print(f"Thread {thread_id} started")
time.sleep(1)
print(f"Thread {thread_id} finished")
threads = []
for i in range(5):
t = threading.Thread(target=worker, args=(i,))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
This code creates 5 threads and starts them all concurrently. Each thread executes the worker function with a different thread ID.
Example 3: Concurrent Execution with Process Pool
In this example, we'll use the multiprocessing module to create a process pool and execute tasks concurrently:
import multiprocessingdef worker(process_id):
print(f"Process {process_id} started")
time.sleep(1)
print(f"Process {process_id} finished")
processes = []
for i in range(5):
p = multiprocessing.Process(target=worker, args=(i,))
processes.append(p)
for p in processes:
p.start()
for p in processes:
p.join()
This code creates 5 processes and starts them all concurrently. Each process executes the worker function with a different process ID.
Example 4: Concurrent Execution with Asyncio
In this example, we'll use the asyncio module to create an event loop and execute tasks concurrently:
import asyncioasync def worker(task_id):
print(f"Task {task_id} started")
await asyncio.sleep(1)
print(f"Task {task_id} finished")
tasks = []
for i in range(5):
task = asyncio.create_task(worker(i))
tasks.append(task)
await asyncio.gather(*tasks)
This code creates 5 tasks and starts them all concurrently. Each task executes the worker function with a different task ID.
These are just a few examples of how you can use concurrent programming in Python to improve performance and responsiveness in your applications.