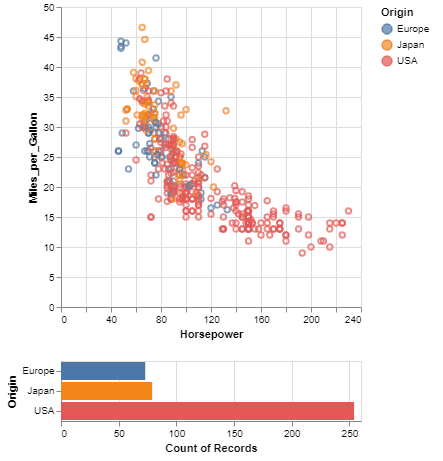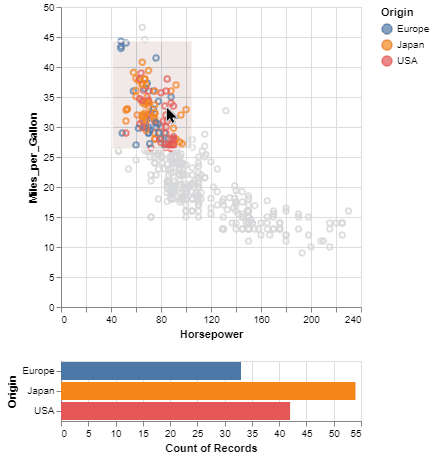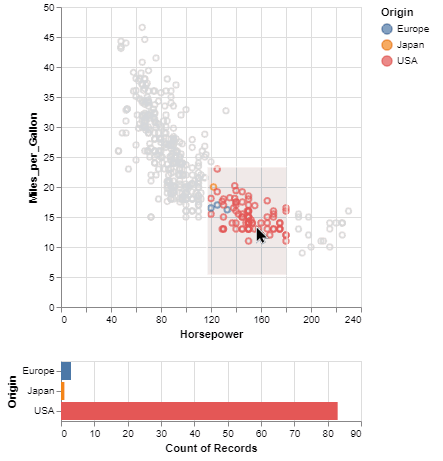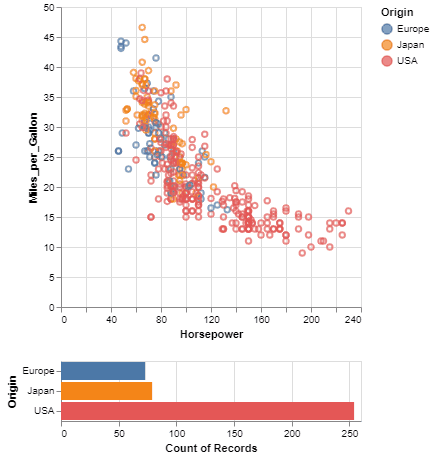
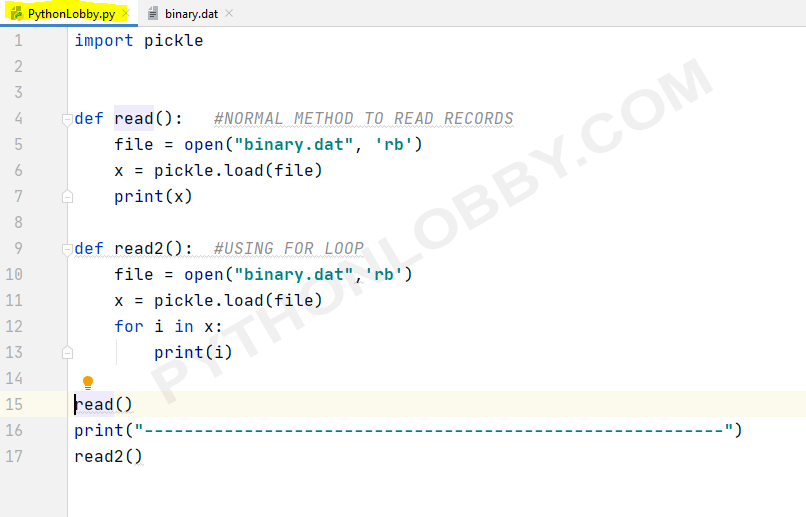
Can you clean data with python w3schools
Can you clean data with python w3schools
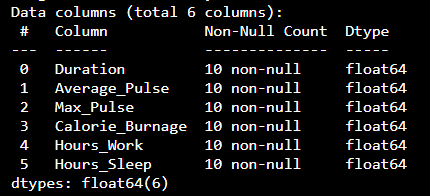
Here's a comprehensive guide on cleaning data using Python and W3Schools:
Importing the Necessary Libraries
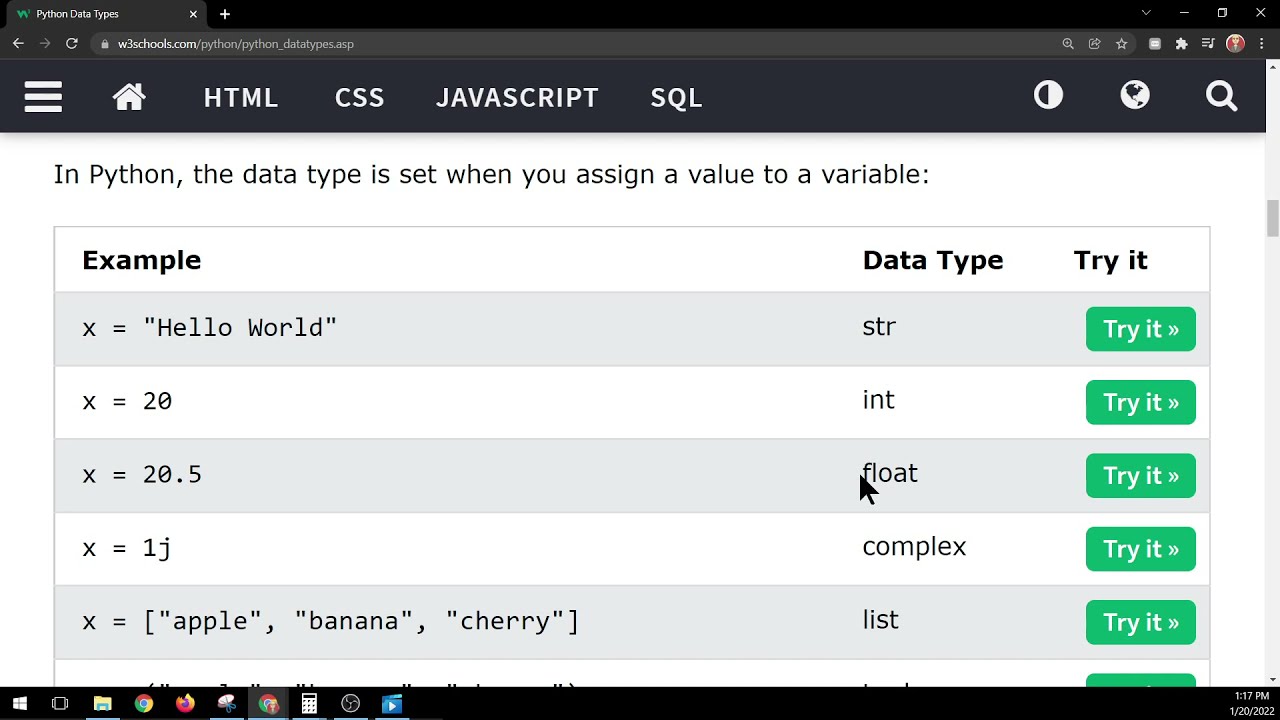
Before we dive into cleaning data, let's import the necessary libraries:
import pandas as pd
In this example, we're going to use the pandas library to work with our data.
Loading Your Data
Now that we have our libraries set up, let's load your data into a Pandas DataFrame:
data = pd.read_csv('your_data.csv')
Replace 'your_data.csv' with the path to your dataset. Make sure it's in CSV format (Comma Separated Values).
Basic Data Cleaning
Now that our data is loaded, let's perform some basic cleaning tasks:
Handling Missing Values: Sometimes, datasets can have missing values represented byNaN or empty strings. We can replace these with mean values or drop them altogether.
data.fillna(data.mean(), inplace=True)
Or
data = data.dropna()
drop_duplicates() function:
data = data.drop_duplicates()
import re
def clean_text(text):
return ' '.join(re.split('[^a-zA-Z0-9s]', text)).lower()
data['your_column'] = data['your_column'].apply(clean_text)
Replace 'your_column' with the name of your text column.
Advanced Data Cleaning
Now that we've covered some basic cleaning tasks, let's move on to more advanced ones:
Handling Outliers: Your dataset might have outliers (values significantly different from others) in certain columns. You can detect these using thequantile() function and then remove them if necessary.
import numpy as np
def identify_outliers(data):
quantile = data.quantile(0.75)
for column in data:
if len(data[(data[column] > quantile[column]).index]) > 0.25 * len(data):
return column
return None
outlier_column = identify_outliers(data)
if outlier_column is not None:
data = data.drop([outlier_column], axis=1)
datetime).
import datetime as dt
def convert_to_datetime(date_string):
return dt.datetime.strptime(date_string, '%Y-%m-%d %H:%M:%S')
data['date_column'] = data['date_column'].apply(convert_to_datetime)
Replace 'date_column' with the name of your date column.
And that's it! By now, you should have a good grasp of how to clean your data using Python and W3Schools.
Is Python good for data manipulation?
I see you want me to respond in English! Alright!
Python is an excellent choice for data manipulation. Here's why:
Ease of use: Python has a simple syntax, making it easy to learn and use, even for those without extensive programming experience. Powerful libraries: Python has numerous libraries dedicated to data manipulation, such as: NumPy: Efficient numerical computations Pandas: Data manipulation and analysis (think Excel, but better!) Matplotlib and Seaborn: Data visualization Scikit-learn: Machine learning and statistical modeling Flexibility: Python can handle a wide range of data types, from simple CSV files to complex datasets with multiple formats. Speed: Python is generally faster than languages like R or Excel when working with large datasets. Integration: Python seamlessly integrates with other tools and technologies, such as: Spreadsheets: Import/export data directly into Excel, Google Sheets, or LibreOffice Calc Databases: Connect to MySQL, PostgreSQL, SQLite, and more for data storage and retrieval Other programming languages: Easily call functions from Python in R, Java, C++, or MATLAB, and vice versa Data analysis: Python's libraries provide robust tools for data cleaning, transformation, visualization, and modeling. Machine learning: Python is a popular choice for machine learning tasks due to its extensive libraries and ease of use with neural networks, decision trees, clustering, and more. Large community: The Python community is vast and active, with numerous resources available, such as tutorials, documentation, and forums, making it easy to find help when needed.Some examples of what you can do with Python for data manipulation:
Clean and preprocess large datasets Perform statistical analysis and modeling Visualize complex data patterns using plots and charts Automate tasks by integrating Python scripts with other tools or systems Develop custom machine learning models for specific problemsIn conclusion, Python is an excellent choice for data manipulation due to its ease of use, powerful libraries, flexibility, speed, integration capabilities, and large community support.