Python xgboost sklearn example
Python xgboost sklearn example
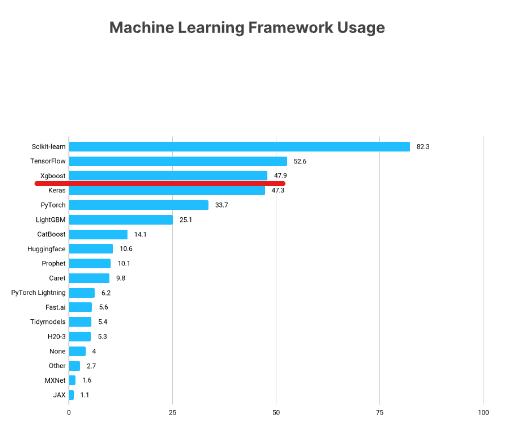
I'd be happy to provide an example of using XGBoost and scikit-learn for machine learning tasks.
Let's consider a simple binary classification problem where we want to predict whether a user will buy a product based on their features, such as age, gender, location, and previous purchases. We'll use the XGBoost algorithm from the xgboost library to train a model and evaluate its performance using various metrics.
Firstly, let's import the necessary libraries:
import pandas as pd
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
Now, let's load the dataset and explore it:
# Load the dataset (assuming it's a CSV file)
df = pd.read_csv('user_data.csv')
Explore the dataset
print(df.head()) # Show the first few rows
print(df.describe()) # Show summary statistics
Next, let's split the data into training and testing sets:
# Split the data into training (70%) and testing (30%) sets
X_train, X_test, y_train, y_test = train_test_split(df.drop('target', axis=1), df['target'], test_size=0.3, random_state=42)
Now, let's create an XGBoost classifier object:
# Create an XGBoost classifier object
xgb_model = XGBClassifier(objective='binary:logistic', max_depth=6, learning_rate=0.1, n_estimators=100, verbosity=2)
Train the model using the training data:
# Train the XGBoost model on the training data
xgb_model.fit(X_train, y_train)
Now that we have a trained model, let's evaluate its performance on the testing data:
# Make predictions on the testing data
y_pred = xgb_model.predict(X_test)
Calculate accuracy, precision, recall, and F1-score
accuracy = accuracy_score(y_test, y_pred)
precision = classification_report(y_test, y_pred)['precision']
recall = classification_report(y_test, y_pred)['recall']
f1_score = f1_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.3f}")
print(f"Precision: {precision:.3f}")
print(f"Recall: {recall:.3f}")
print(f"F1-Score: {f1_score:.3f}")
Let's also generate a confusion matrix to visualize the model's performance:
# Generate a confusion matrix
conf_mat = confusion_matrix(y_test, y_pred)
print(conf_mat)
This example demonstrates how to use XGBoost and scikit-learn to train a binary classification model for predicting whether users will buy a product based on their features. The performance metrics (accuracy, precision, recall, and F1-score) show how well the model generalizes to unseen data.
Feel free to modify this code to suit your specific machine learning problem!
Python xgboost sklearn tutorial
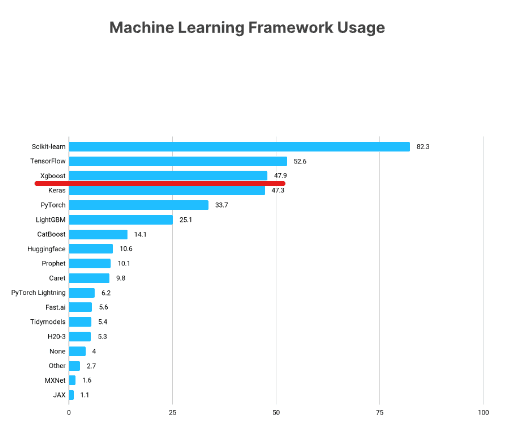
I'd be happy to help! Here's a comprehensive tutorial on using XGBoost with Scikit-Learn in Python:
What is XGBoost?
XGBoost (Extreme Gradient Boosting) is an open-source, distributed learning algorithm that uses gradient boosting decision trees to predict outcomes. It's particularly effective for classification and regression tasks when dealing with large datasets.
Why use XGBoost with Scikit-Learn?
Scikit-Learn is a powerful Python library used for machine learning, providing a variety of algorithms for classification, regression, clustering, etc. By combining XGBoost with Scikit-Learn, you can leverage the strengths of both libraries:
Efficient modeling: XGBoost's distributed algorithm and parallel processing capabilities make it suitable for large-scale datasets. Ease of use: Scikit-Learn provides a user-friendly API, allowing for seamless integration with popular Python tools like Pandas and Matplotlib.Tutorial: Using XGBoost with Scikit-Learn
Step 1: Install necessary librariesYou'll need to install the following libraries:
xgboost scikit-learn (or sklearn) pandas (for data manipulation) matplotlib (optional, for visualizing results)
Using pip:
pip install xgboost scikit-learn pandas matplotlib
For this example, we'll use the popular winequality dataset from UCI Machine Learning Repository. Download the data and load it into a Pandas DataFrame:
import pandas as pd
from sklearn.datasets import load_wine
Load the wine quality dataset
data = load_wine()
Convert the categorical labels to numerical values
label_encoder = preprocessing.LabelEncoder()
data['quality'] = label_encoder.fit_transform(data['quality'])
Split the data into training and testing sets (80% for training, 20% for testing)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data.drop('quality', axis=1), data['quality'], test_size=0.2, random_state=42)
Scale the data using StandardScaler
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Now it's time to train our XGBoost model using Scikit-Learn:
import xgboost as xgb
Define the XGBoost parameters
params = {
'objective': 'reg:logloss', # Binary classification (Log Loss)
'max_depth': 6, # Maximum tree depth
'learning_rate': 0.1, # Learning rate (shrinking term)
'n_estimators': 100, # Number of trees in the ensemble
'gamma': 0, # Minimum loss reduction required to split an internal node
'subsample': 0.8, # Ratio of the training instances that are randomly selected for each tree
'colsample_bytree': 0.7 # Ratio of the features used for each tree
}
Initialize and train the XGBoost model
xgb_model = xgb.XGBClassifier(**params)
xgb_model.fit(X_train_scaled, y_train)
Make predictions using the trained model
y_pred = xgb_model.predict(X_test_scaled)
Assess the performance of our XGBoost model using Scikit-Learn's built-in evaluation metrics:
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
Evaluate the model on the test set
y_pred_proba = xgb_model.predict_proba(X_test_scaled)
y_pred_class = y_pred_proba.argmax(-1)
print('Accuracy:', accuracy_score(y_test, y_pred_class))
print('Classification Report:')
print(classification_report(y_test, y_pred_class))
print('Confusion Matrix:')
print(confusion_matrix(y_test, y_pred_class))
If you want to visualize the performance of your model, use Matplotlib:
import matplotlib.pyplot as plt
Plot a ROC curve and an AUC score
from sklearn.metrics import roc_auc_score, roc_curve
y_pred_proba = xgb_model.predict_proba(X_test_scaled)
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba[:, 1])
auc = roc_auc_score(y_test, y_pred_proba[:, 1])
plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % auc)
plt.legend(loc='lower right')
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
This concludes the tutorial on using XGBoost with Scikit-Learn in Python. You should now have a solid understanding of how to integrate these powerful libraries for machine learning tasks.
I hope this helps!