How to test a trained model in Python?
How to test a trained model in Python?
Testing a trained model in Python is crucial to evaluate its performance and identify potential issues before deploying it in a production environment. Here's a step-by-step guide on how to test a trained model in Python:
1. Load the Model: Start by importing the necessary libraries and loading your trained model from disk or memory. For example, if you used TensorFlow or Keras to train your model, you can load it using:
import tensorflow as tf
model = tf.keras.models.load_model('path/to/model.h5')
2. Prepare Test Data: Create a test dataset that represents the type of data your model will encounter in production. This should include input features and corresponding output labels (if applicable). You can use libraries like Pandas or NumPy to manipulate your data.
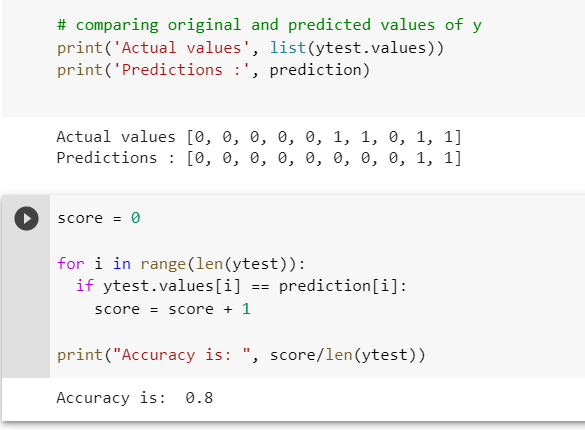
3. Evaluate the Model: Use evaluation metrics specific to your problem domain, such as accuracy, precision, recall, F1-score, mean squared error, or R-squared. Some popular evaluation methods include:
Accuracy: Measures the proportion of correctly classified instances. Precision: Measures the proportion of true positives among all positive predictions. Recall (Sensitivity): Measures the proportion of true positives among all actual positive instances. F1-score: Harmonic mean of precision and recall.You can use libraries like Scikit-learn or Statsmodels to calculate these metrics:
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(test_data)
y_true = test_labels
print("Accuracy:", accuracy_score(y_true, y_pred))
print(classification_report(y_true, y_pred))
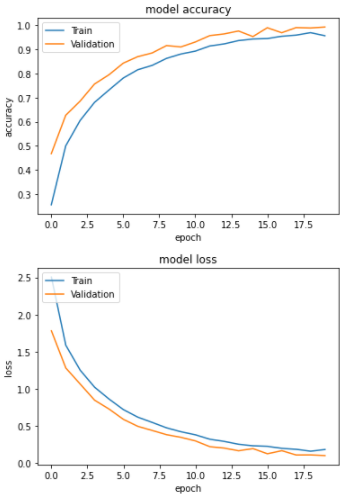
4. Visualize Performance: Use visualization tools like Matplotlib or Seaborn to illustrate the performance of your model:
import matplotlib.pyplot as plt
plt.plot(test_data[:, 0], y_pred)
plt.xlabel('Input Feature')
plt.ylabel('Predicted Output')
plt.title('Model Performance')
plt.show()
5. Handle Edge Cases: Test your model on edge cases, such as:
Boundary values: Test the model with input values near the boundaries (e.g., 0 and 1). Outliers: Test the model's performance when presented with outlier data points. NaN or Inf values: Ensure your model can handle NaN or Inf values correctly.6. Benchmarking: Compare the performance of your trained model against other models, such as:
Baseline model: A simple model that predicts a constant output (e.g., mean or median). Other models: Train and evaluate other models using different algorithms or hyperparameters.import time
start_time = time.time()
model.evaluate(test_data, test_labels)
end_time = time.time()
print("Evaluation took {:.2f} seconds".format(end_time - start_time))
7. Model Interpretability: Visualize the model's decision-making process to gain insights into its behavior:
import lime
from sklearn_explain import LimeExplainer
explainer = LimeExplainer()
exp = explainer.explain_instance(test_data[0], model.predict, num_features=10)
By following these steps, you can thoroughly test your trained model in Python, identifying potential issues and verifying its performance on a range of input data.
How do you test the accuracy of a model in Python?
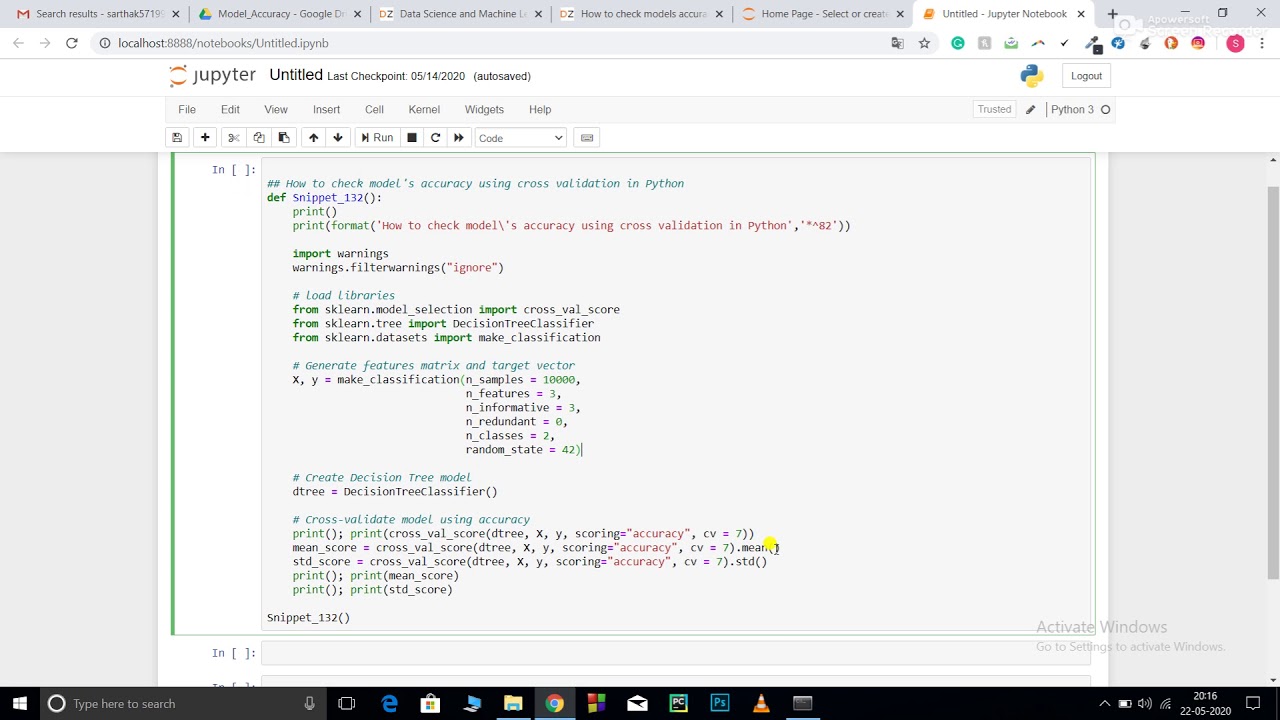
Testing the accuracy of a model is an essential step in machine learning to ensure it is performing well and can make reliable predictions on new, unseen data. In Python, there are several ways to evaluate the performance of a model, depending on the type of problem you're trying to solve and the metrics that are most relevant to your use case.
Mean Absolute Error (MAE): This metric is used for regression problems where the goal is to predict a continuous value. It calculates the average difference between predicted and actual values. from sklearn.metrics import mean_absolute_error
y_pred = model.predict(X_test)

mae = mean_absolute_error(y_test, y_pred)
print("Mean Absolute Error:", mae)
from sklearn.metrics import mean_squared_error
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
from sklearn.metrics import r2_score
y_pred = model.predict(X_test)
r2 = r2_score(y_test, y_pred)
print("R-Squared:", r2)
from sklearn.metrics import accuracy_score
y_pred = model.predict(X_test)
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)
from sklearn.metrics import f1_score
y_pred = model.predict(X_test)
f1 = f1_score(y_test, y_pred, average='macro')
print("F1 Score:", f1)
from sklearn.metrics import confusion_matrix
y_pred = model.predict(X_test)
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:n", cm)
Remember to always split your dataset into training and testing sets before evaluating your model. This will ensure that the metrics you calculate are a good representation of how well your model will perform on new data.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Also, it's important to remember that evaluating a model is not just about calculating metrics. You should also consider factors such as overfitting and underfitting, which can affect the performance of your model on unseen data.
I hope this helps! Let me know if you have any questions or need further clarification.





























