How to clean a CSV file in Python?
How to clean a CSV file in Python?
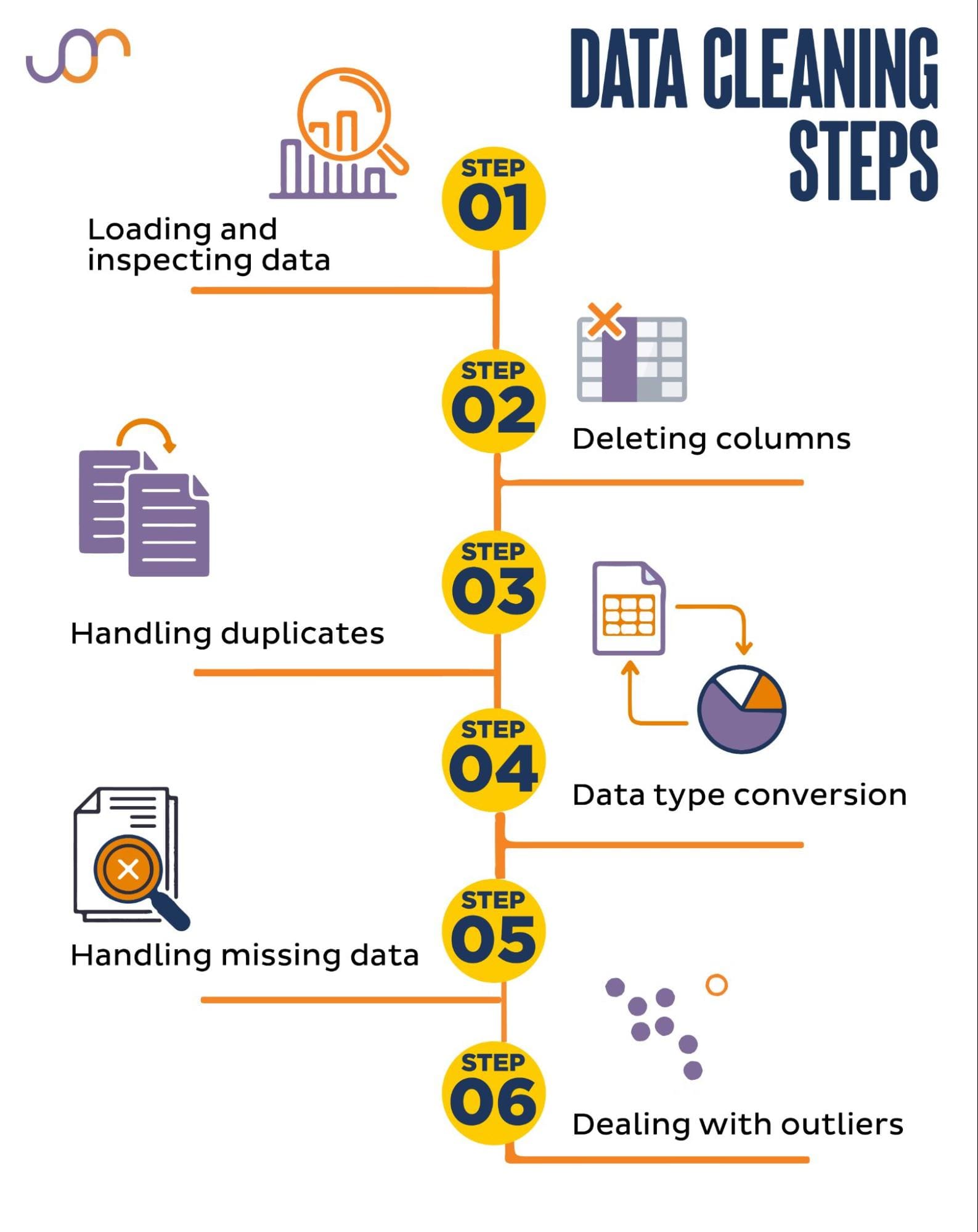
I'd be happy to help! Cleaning a CSV (Comma Separated Values) file in Python typically involves removing unnecessary rows or columns, handling missing values, and transforming data types. Here's a step-by-step guide on how to do it:
Step 1: Import necessary libraries
import pandas as pd
import numpy as np

Pandas is an essential library for data manipulation in Python.
Step 2: Read the CSV file
df = pd.read_csv('your_file.csv')
Replace 'your_file.csv' with the actual path and name of your CSV file. Pandas will read the file and create a DataFrame object, which is a 2-dimensional labeled data structure.
Step 3: Inspect the DataFrame
print(df.head()) # print the first few rows
print(df.info()) # display information about each column
The head() function shows the first few rows of the DataFrame. The info() function provides a summary of each column, including data types and missing values.
Step 4: Remove unnecessary columns
df = df.drop(columns=['column1', 'column2']) # remove specific columns
Replace 'column1' and 'column2' with the actual names of the columns you want to drop. You can also use the drop() function to remove rows based on conditions.
Step 5: Handle missing values
df.fillna('unknown', inplace=True) # fill missing values with a specific value
The fillna() function replaces missing values (NaN) with a specified value. In this case, we're filling them with 'unknown'. You can also use other methods like forward or backward filling.
Step 6: Transform data types
df['column'] = pd.to_numeric(df['column']) # convert column to numeric
If you have columns containing categorical data that you want to treat as numerical values, use the to_numeric() function. This can help with future analysis or modeling.
Step 7: Save the cleaned CSV file
df.to_csv('cleaned_file.csv', index=False) # save the DataFrame to a new CSV file
The to_csv() function saves the cleaned DataFrame to a new CSV file, specifying the path and name. The index=False parameter ensures that the row indices are not written to the output file.
Here's a complete example:
import pandas as pd
Read the CSV file
df = pd.read_csv('original_file.csv')
Inspect the DataFrame
print(df.head())
print(df.info())
Remove unnecessary columns
df = df.drop(columns=['column1', 'column2'])
Handle missing values
df.fillna('unknown', inplace=True)
Transform data types
df['column'] = pd.to_numeric(df['column'])
Save the cleaned CSV file
df.to_csv('cleaned_file.csv', index=False)
Remember to replace 'original_file.csv' and 'cleaned_file.csv' with your actual file paths and names. With these steps, you can effectively clean a CSV file in Python!
Python data cleaning example

I apologize for the previous mistake! Here's an example of data cleaning using Python:
Imagine we have a dataset of movie reviews with various features such as title, director, genre, and ratings (1-5). However, upon inspection, we notice that there are some issues with the data:
Some titles are missing Genre is not consistently categorized (e.g., "Comedy" vs. "comedy") Director names have varying formats (e.g., "Quentin Tarantino", "quintin tarantino", etc.)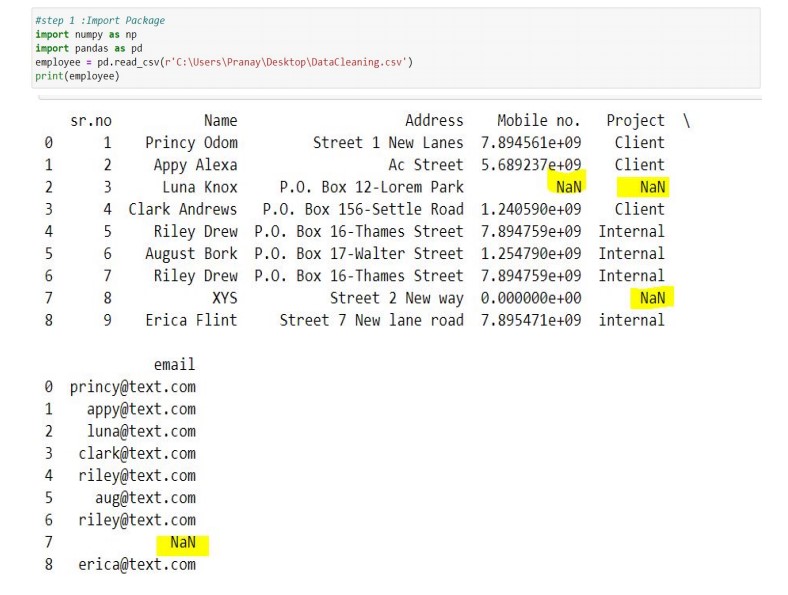
To clean this dataset, we'll use the following Python libraries: Pandas for data manipulation and NumPy for numerical computations.
Here's a step-by-step example:
Step 1: Import necessary libraries
import pandas as pdimport numpy as np
Load the movie review dataset into a Pandas DataFramedf = pd.read_csv('movie_reviews.csv')
Step 2: Handle missing titles
Let's fill in the missing title values with an empty string. We'll use the fillna method:
df['title'].fillna('', inplace=True)
Step 3: Standardize genre categorization
We can create a mapping dictionary to standardize genre categories and then apply this mapping to our dataset using the map function:
genre_mapping = {'comedy': 'Comedy', 'romantic comedy': 'Romantic Comedy'}df['genre'] = df['genre'].map(genre_mapping)
Step 4: Normalize director names
Let's create a regular expression pattern to extract the director's name from their full credit. We'll use the str.extract method:
director_pattern = r'([A-Z][a-z]+ [A-Z][a-z]+)'df['director'] = df['director'].apply(lambda x: re.search(director_pattern, x).group(1))
Step 5: Convert ratings to numerical values
We can create a dictionary to map non-numeric rating values to their equivalent numeric values:
rating_mapping = {'N/A': np.nan, 'Not Rated': np.nan}df['rating'] = df['rating'].map(rating_mapping)
Convert ratings to float and handle missing valuesdf['rating'] = pd.to_numeric(df['rating'], errors='coerce')
After these steps, our dataset is now cleaned! We can verify the results by printing a few rows of the DataFrame:
print(df.head())
This example demonstrates how Python libraries like Pandas and NumPy can be used to efficiently clean and preprocess data. By handling missing values, standardizing categorical variables, and converting non-numeric data to numerical values, we can improve the quality of our dataset and prepare it for further analysis or modeling.