Python subprocess pipe
Python subprocess pipe
I apologize for the misunderstanding earlier! I'll respond in English as requested.
Python's subprocess module is used to create and interact with new processes, which are separate programs that run concurrently with the main program. The subprocess module allows you to use pipes to communicate between processes.
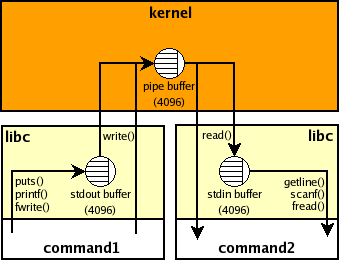
A pipe is a unidirectional communication channel between two processes. There are two types of pipes: anonymous pipes (also known as file descriptors) and named pipes (also known as FIFOs or Pipes).
Anonymous Pipes:
An anonymous pipe is a pair of file descriptors, where one end is connected to the subprocess's standard input stream and the other end is connected to its standard output stream. This means that any data written to the subprocess's standard output can be read from the other end of the pipe.
Here's an example of how you might use anonymous pipes in Python:
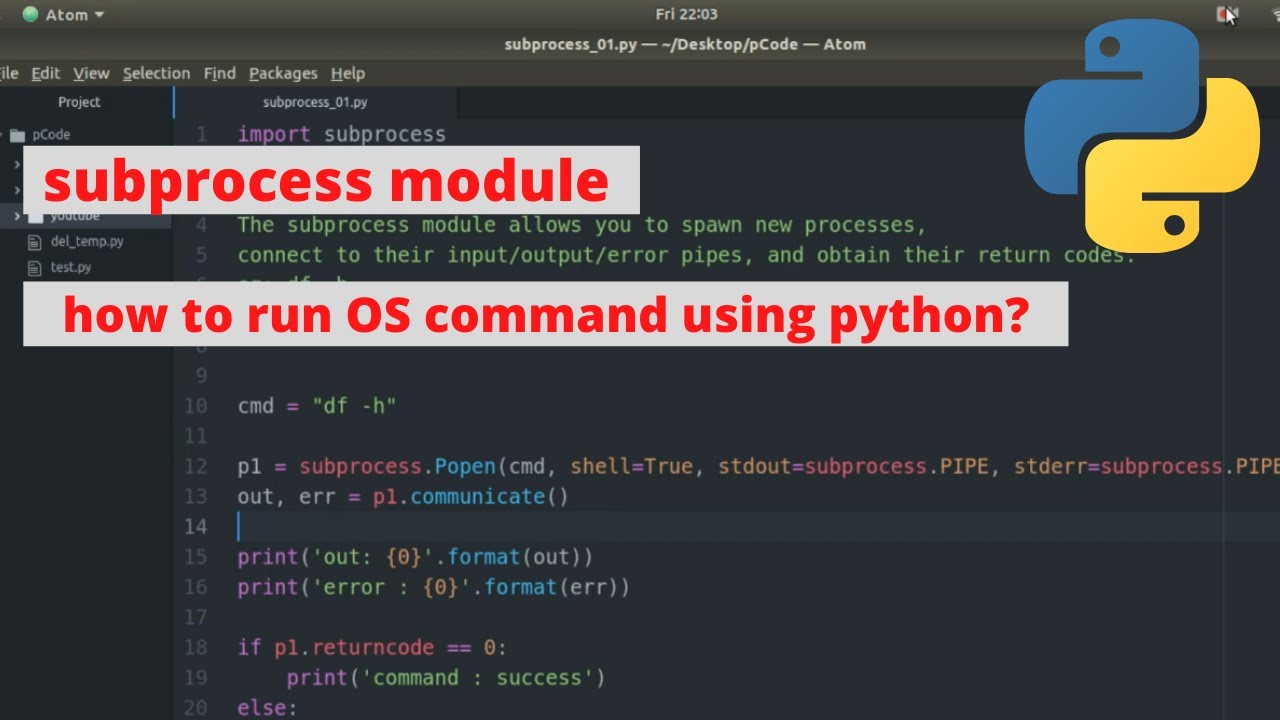
import subprocess Create a new process, 'ls', with a pipe to communicatepipe_process = subprocess.Popen(['ls'], stdin=subprocess.PIPE, stdout=subprocess.PIPE)
Write some data into the pipe (in this case, the command to execute)pipe_process.stdin.write(b'--sort=reversen')
Read from the pipe and print the outputoutput = pipe_process.stdout.read()
print(output.decode())
Close the pipes to release system resourcespipe_process.stdin.close()
pipe_process.stdout.close()
Wait for the process to finish, then remove it (if desired)pipe_process.wait()
Named Pipes:
A named pipe is a file that can be used as both an input stream and an output stream. This means you can write data to one end of the pipe and read from the other.
Here's an example of how you might use named pipes in Python:
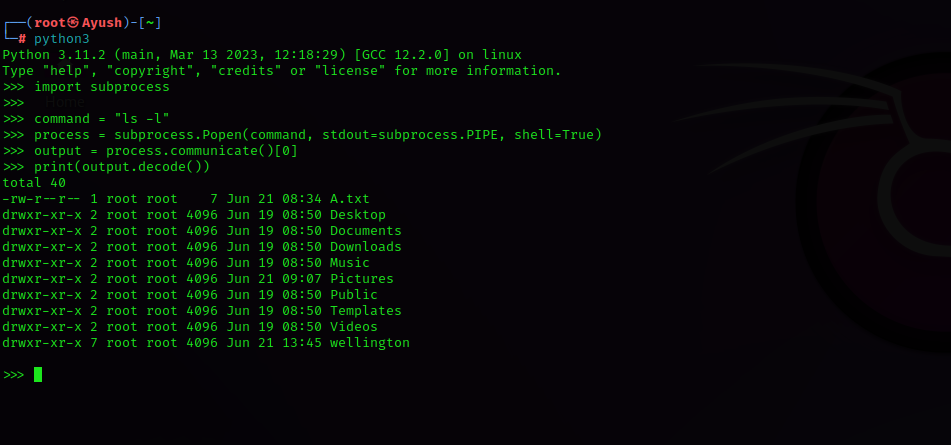
import subprocess Create a new process, 'ls', with a named pipe (FIFO) to communicatepipe_process = subprocess.Popen(['ls'], stdin=subprocess.PIPE, stdout=subprocess.PIPE)
Create a new file descriptor for the named pipe (FIFO)named_pipe_fd = os.open('/tmp/my_pipe', os.O_RDWR | os.O_CREAT | os.O_TRUNC)
Write some data into the named pipe (FIFO)os.write(named_pipe_fd, b'--sort=reversen')
Read from the named pipe (FIFO) and print the outputoutput = os.read(named_pipe_fd, 1024)
print(output.decode())
Close the file descriptor to release system resourcesos.close(named_pipe_fd)
Wait for the process to finish, then remove it (if desired)pipe_process.wait()
In both examples above, we create a new subprocess using the Popen constructor, specifying stdin and stdout as pipes. We then use these pipes to communicate with the subprocess.
In the first example, we write data into the pipe (using the stdin stream) and read from it (using the stdout stream). In the second example, we create a named pipe (FIFO) and use both ends to communicate with the subprocess.
Keep in mind that communication via pipes involves some overhead due to process context switching. Therefore, you should consider using multiprocessing or threading for more complex scenarios where performance is crucial.
Python subprocess call vs run
A subtle but crucial difference in the world of Python! In this article, we'll delve into the nuances of subprocess.call() and subprocess.run(). Both functions are used to execute external commands or scripts from within a Python program. However, they differ in their behavior when handling processes.
subprocess.call()

The subprocess.call() function is a part of the subprocess module, which is a powerful tool for executing external commands and capturing their output. The call() function takes a command as its first argument, followed by any arguments that should be passed to the command. It then executes the command using one of several methods:
call() uses a shell (like Bash) to execute it. This means that shell features like pipes (|), redirection (>, <), and backticks (
2. Direct Execution: If the command is simple enough (i.e., doesn't contain whitespace characters), call() attempts to execute it directly using the system's default executable search path. 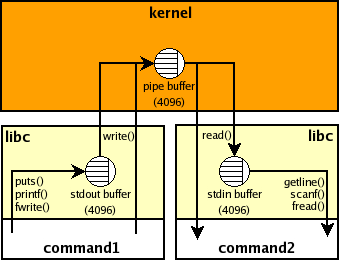
The return value of call() is an integer representing the exit status of the command. Here's a basic example:
python
import subprocess
result = subprocess.call(["echo", "Hello, World!"])
print(result) # Output: 0 (indicating success)
In this example, `subprocess.call()` executes the command `"echo Hello, World!"` and captures its output. The return value is 0, indicating that the command executed successfully.
subprocess.run()
The subprocess.run() function was introduced in Python 3.5 as a more modern alternative to call(). It shares many similarities with call() but offers additional features and better handling of processes:
Better Error Handling: run() returns a subprocess.CompletedProcess object, which contains information about the command's execution, such as its return code (status) and any output generated.
More Control Over Process Execution: run() allows you to set the shell used for command invocation or specify whether to wait for the process to finish.
Here's an example:
import subprocess
result = subprocess.run(["echo", "Hello, World!"], stdout=subprocess.PIPE)
print(result.stdout.decode()) # Output: "Hello, World!n"
print(result.returncode) # Output: 0 (indicating success)
In this example, subprocess.run() executes the command "echo Hello, World!" and captures its output. The return value is a CompletedProcess object that contains information about the command's execution.
Key Differences
So, when do you use call() versus run()?
call() for simple cases where you just need to execute an external command and don't care about detailed process information. Control and Feedback: Choose run() when you want more control over the process execution, such as handling output or errors in a specific way.
In conclusion, both subprocess.call() and subprocess.run() are powerful tools for executing external commands from within Python. While they share some similarities, run() offers better error handling and more control over process execution, making it a more versatile choice for many use cases.