Python mlflow example
Python mlflow example

I'd be happy to provide an example of using MLflow with Python!
MLflow is a popular open-source platform for managing the end-to-end machine learning (ML) lifecycle, from data preparation and model training to deployment and iteration. In this example, we'll demonstrate how to use MLflow to track experiments, log metrics, and deploy a trained model using Python.
Step 1: Install MLflow
First, you need to install MLflow using pip:
pip install mlflow
Step 2: Create an MLflow Experiment
Create a new experiment using the following code:
import mlflow Create an experiment with a name and descriptionexperiment_name = "my_experiment"
experiment_description = "This is my experiment for training a machine learning model"
mlflow.create_experiment(experiment_name, experiment_description)
Step 3: Log Parameters and Metrics
Now, let's log some parameters and metrics using the log_params and log_metrics methods:

# Log a parameter (hyperparameter) to track its impact on the modelparam = "learning_rate"
value = 0.01
mlflow.log_param(param, value)
Log some initial metrics before training the model
metric1 = "loss"
value1 = 10.0
mlflow.log_metric(metric1, value1)


Step 4: Train a Model
Train a simple linear regression model using scikit-learn and log its performance:
from sklearn.linear_model import LinearRegression Create the model and train it on some sample dataX = [[1], [2], [3]]
y = [10, 12, 15]
model = LinearRegression()
model.fit(X, y)
Log the model's metrics (e.g., R-squared)r_squared = model.score(X, y)
mlflow.log_metric("R-squared", r_squared)
Step 5: Deploy the Model
Deploy the trained model using MLflow's register_model and load_model methods:
# Register the model with a name and versionmodel_name = "my_model"
model_version = 1
mlflow.register_model("path/to/model.pkl", model_name, model_version)
Load the deployed model for inferenceloaded_model = mlflow.pyfunc.load_model(model_name + "-" + str(model_version))
Step 6: View Experiment Results
Use MLflow's view_experiment method to view the experiment results, including logged parameters, metrics, and model artifacts:
# View the experiment results (logged metrics, etc.)mlflow.view_experiment(experiment_name)
That's it! With these steps, you've successfully used MLflow to track experiments, log metrics, deploy a trained model, and view the experiment results using Python.
In this example, we've covered basic features of MLflow, such as:
Creating an experiment and tracking parameters and metrics Training a model and logging its performance Deploying the trained model for inference Viewing the experiment resultsMLflow provides many more features beyond these examples, including support for multiple frameworks (e.g., TensorFlow, PyTorch), integration with popular datastores (e.g., AWS S3, Google Cloud Storage), and collaboration tools. If you're interested in learning more about MLflow or exploring its advanced features, I encourage you to check out the official documentation or search for tutorials online!
What is MLflow in Python?
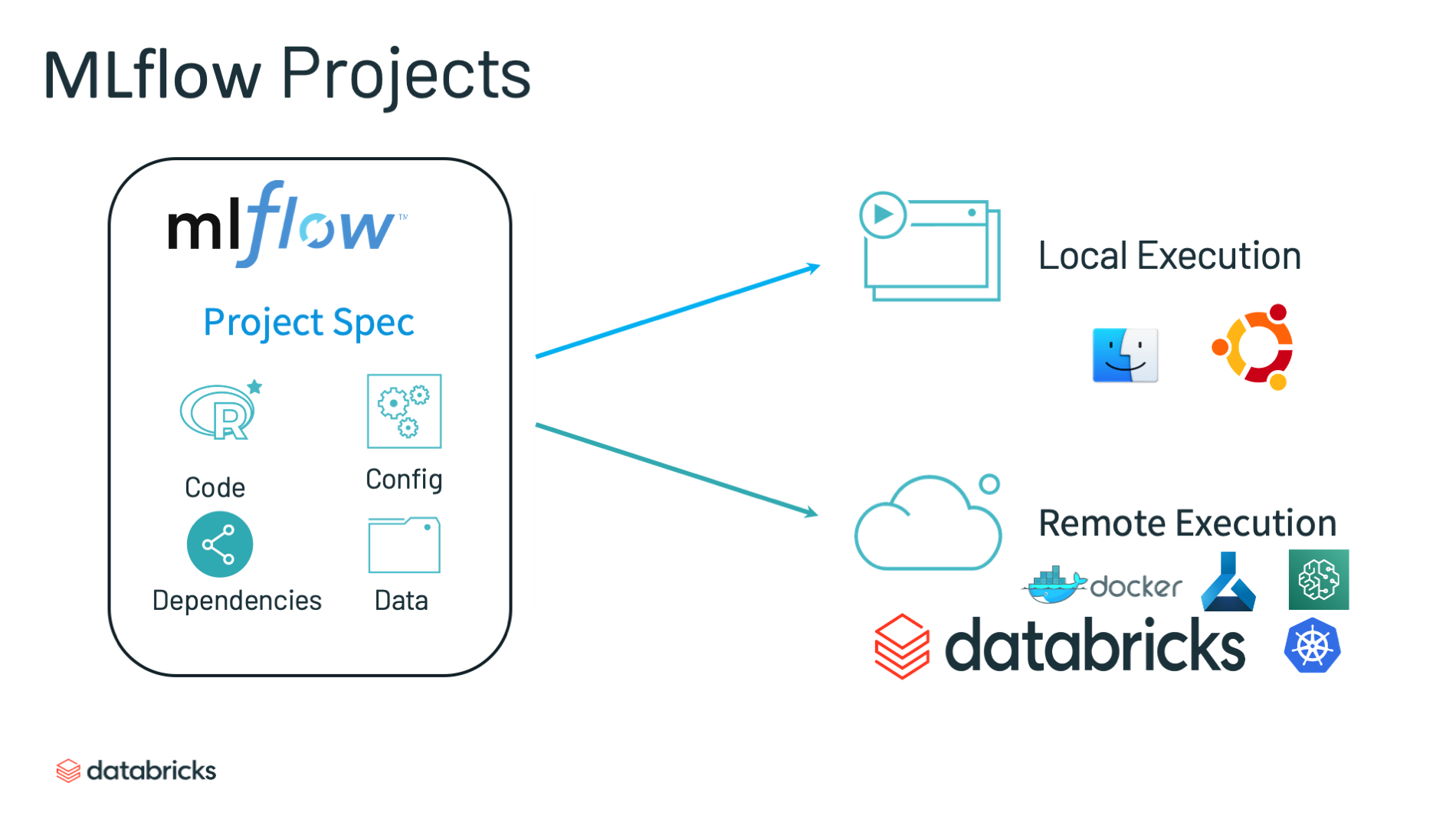
I'm happy to respond in English!
MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle, from experimentation and version control to deployment and monitoring. It was created by Databricks, a leading cloud-based data analytics platform, with the goal of making it easier for organizations to manage and deploy their ML models in production environments.
In Python, MLflow provides several key features that simplify the ML development process:
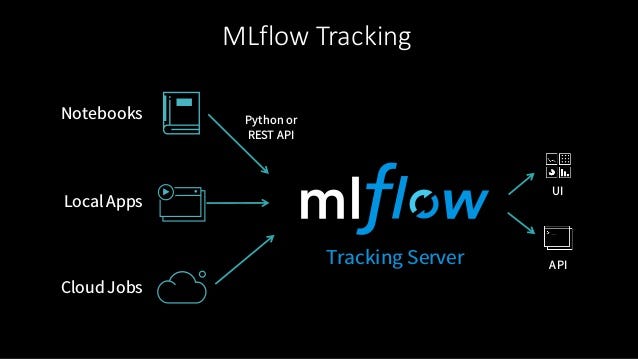
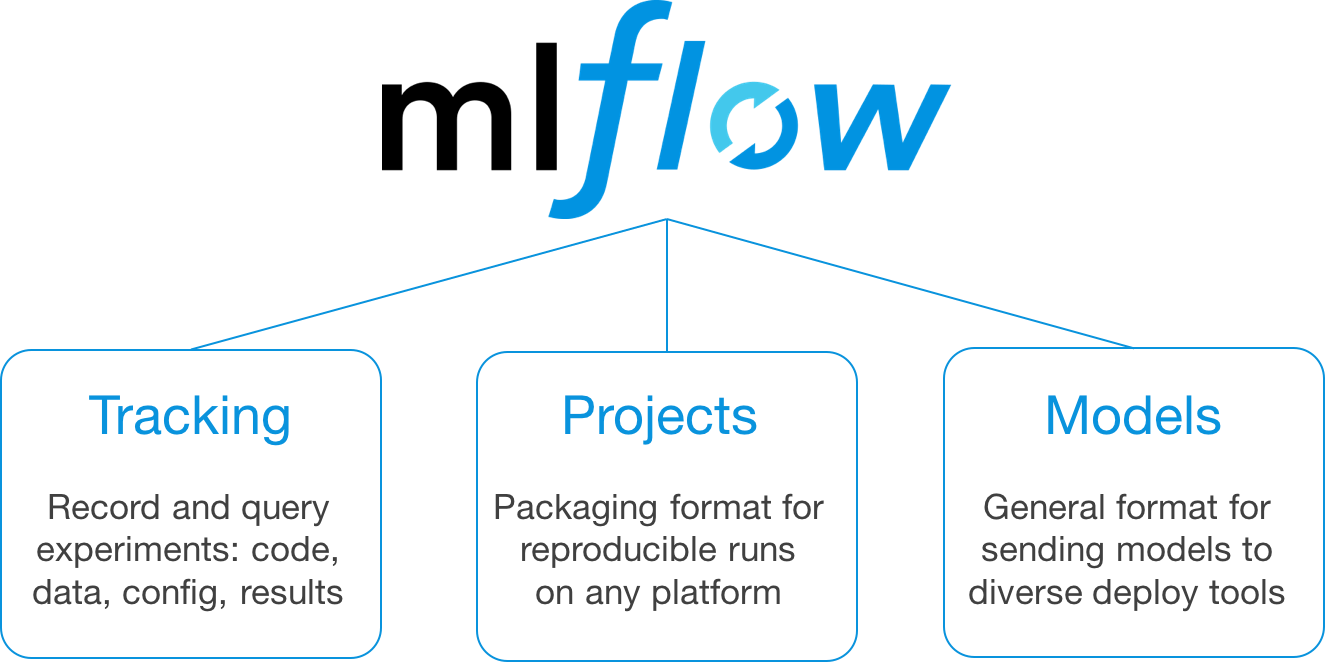
Some benefits of using MLflow include:
Reproducibility: By tracking experiments and storing metadata, you can easily reproduce and compare different runs. Collaboration: Version control enables multiple team members to work on the same project simultaneously. Efficient deployment: Deployments are streamlined with MLflow's built-in support for cloud services. Monitoring: Real-time monitoring helps detect issues early, reducing downtime and improving overall model performance.To get started with MLflow in Python, you can install it using pip:
pip install mlflow
Then, create an MLflow project by running the following command:
mlflow create-project my_project
This will generate a new directory containing basic templates for tracking, logging, and deploying models.
In your Python code, you can initialize an MLflow run using the MLflow.run function. For example:
import mlflowwith mlflow.start_run():
Run your machine learning experiment hereprint("Running my experiment...")
When you're finished with your experiment, you can log metrics and parameters to track its performance:
mlflow.log_metric("accuracy", 0.9)mlflow.log_param("learning_rate", 0.01)
This is just a brief introduction to MLflow in Python. If you're interested in learning more, I recommend checking out the official documentation or tutorials online. Happy machine learning!





























