How do you read in python w3schools
How do you read in python w3schools
I'd be happy to help with that!
W3Schools is an online platform providing tutorials and reference materials for web development, including Python programming. To read data from W3Schools using Python, you can employ various methods based on the type of content you want to extract. Here's a step-by-step guide on how to do it:
Method 1: Using BeautifulSoup and Requests libraries
First, install the beautifulsoup4 and requests libraries if you haven't already:
pip install beautifulsoup4 requests
Now, let's use these libraries to read HTML content from W3Schools. For example, we can fetch the Python tutorial page:
import requestsfrom bs4 import BeautifulSoup
url = "https://www.w3schools.com/python/"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
Find all headings on the pageheadings = soup.find_all('h2')
print(headings)
Method 2: Using Selenium library (for web scraping)
Another approach is to use selenium to simulate a browser and extract data. First, install selenium:
pip install selenium
Now, we can create a Python script that opens the W3Schools website, navigates to the desired page, and extracts data:
from selenium import webdriver Set up the ChromeDriverdriver = webdriver.Chrome()
Navigate to the pagedriver.get("https://www.w3schools.com/python/")
Find all headings on the pageheadings = driver.find_elements_by_tag_name('h2')
print(headings)
Close the browser windowdriver.quit()
Method 3: Using Scrapy library (for web scraping)
If you're looking for a more advanced and scalable solution, consider using scrapy. It's a full-fledged web scraping framework that can handle complex tasks:
import scrapyclass W3SchoolsSpider(scrapy.Spider):
name = "w3schools"
start_urls = ['https://www.w3schools.com/python/']
def parse(self, response):
Find all headings on the pageheadings = response.css('h2::text').getall()
for heading in headings:
yield {
'heading': heading.strip()
}
Common considerations
When scraping data from W3Schools or any other website, please keep the following points in mind:
Respect their terms of service: Be sure to check W3Schools' terms and conditions for web scraping. Avoid overloading the server: Don't scrape excessively, as it can negatively impact their server performance. Use correct handling of exceptions: Implement proper error handling mechanisms in your code.By following these guidelines and utilizing Python libraries like BeautifulSoup, Requests, Selenium, or Scrapy, you'll be well-equipped to extract data from W3Schools' website efficiently and effectively!
python read text file
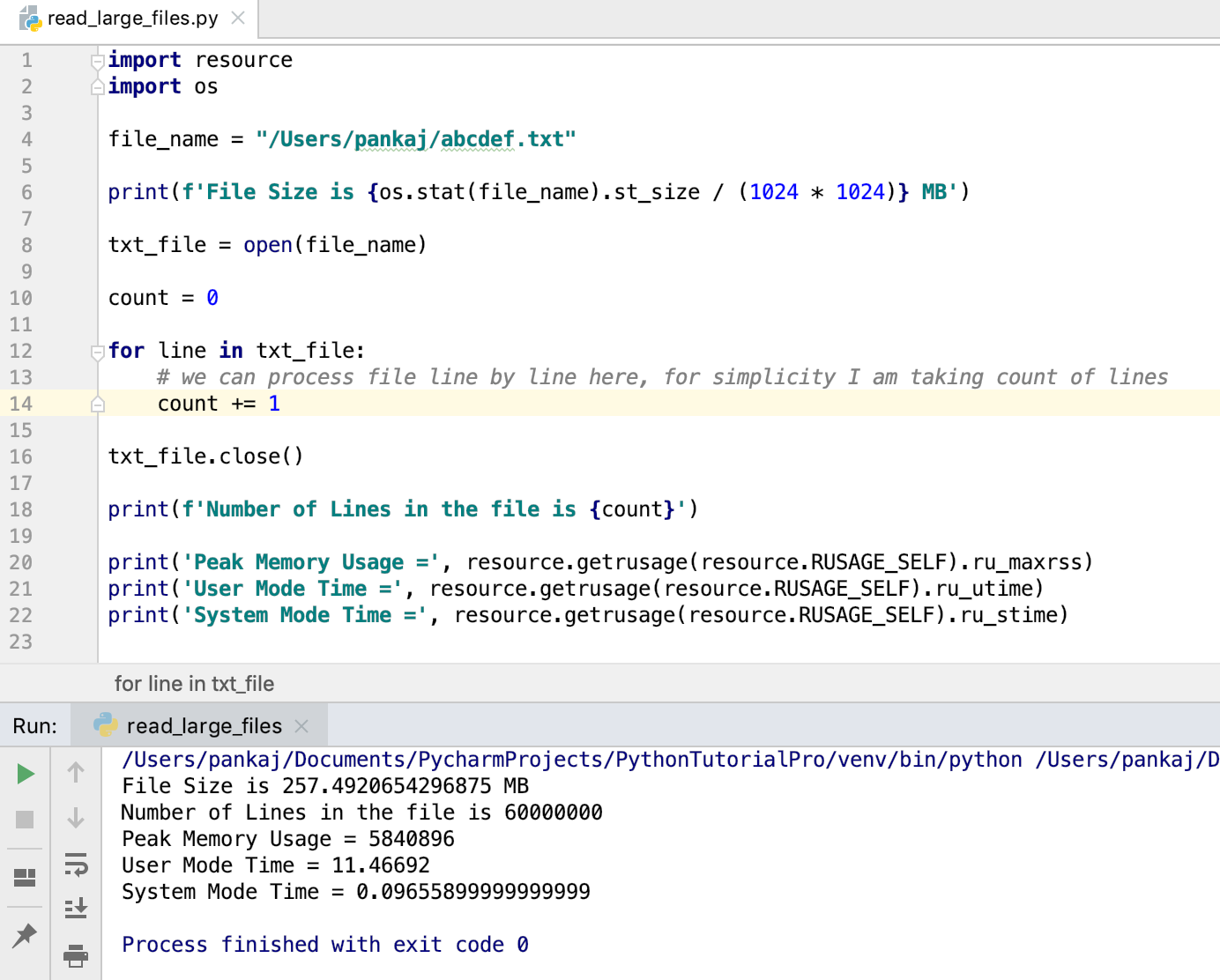
Python provides several ways to read a text file, including the built-in open() function and the readfile() method provided by libraries like NumPy or Pandas.
Here's an example of how you can use the open() function to read a text file:
with open('example.txt', 'r') as f:
contents = f.read()
print(contents)
In this code, 'example.txt' is the name of the text file you want to read. The 'r' argument tells Python to open the file in read-only mode.
The with statement ensures that the file is properly closed after we're done with it, regardless of whether an exception is thrown or not. This is a good practice to follow, as it helps prevent file descriptor leaks and makes your code more robust.
If you want to read the file line by line, rather than all at once, you can use a for loop:
with open('example.txt', 'r') as f:
for line in f:
print(line.strip())
In this code, line.strip() removes any trailing newline characters from each line.
Alternatively, you can use the readlines() method to read the file into a list of lines:
with open('example.txt', 'r') as f:
lines = f.readlines()
print(lines)
This can be useful if you want to process the contents of the file in some way, such as counting the number of lines or words.
Python also provides several libraries for working with text files, including numpy and pandas.
Here's an example of how you might use these libraries to read a text file:
import pandas as pd
df = pd.read_csv('example.txt', header=None)
print(df)
In this code, 'example.txt' is the name of the text file. The header=None argument tells pandas to assume that there is no header row in the file.
If you want to read the file line by line using a library like pandas, you can use the read_csv() method:
import pandas as pd
for line in pd.read_csv('example.txt', header=None, chunksize=1):
print(line)
In this code, chunksize=1 tells pandas to return each line of the file as a separate DataFrame. The for loop then prints each line.
Overall, Python provides several ways to read text files, including using built-in functions like open() and libraries like NumPy and Pandas. The method you choose will depend on your specific needs and the structure of your data.
Here are some benefits of reading a text file in Python:
Flexibility: Python allows you to process text files in a variety of ways, from simple string manipulation to complex data analysis. Ease of use: Python's built-inopen() function makes it easy to read text files, even for users with little programming experience. Speed: Reading text files can be faster than reading other types of files, such as binary files or CSV files. Portability: Python programs that read text files are portable across different platforms and systems.
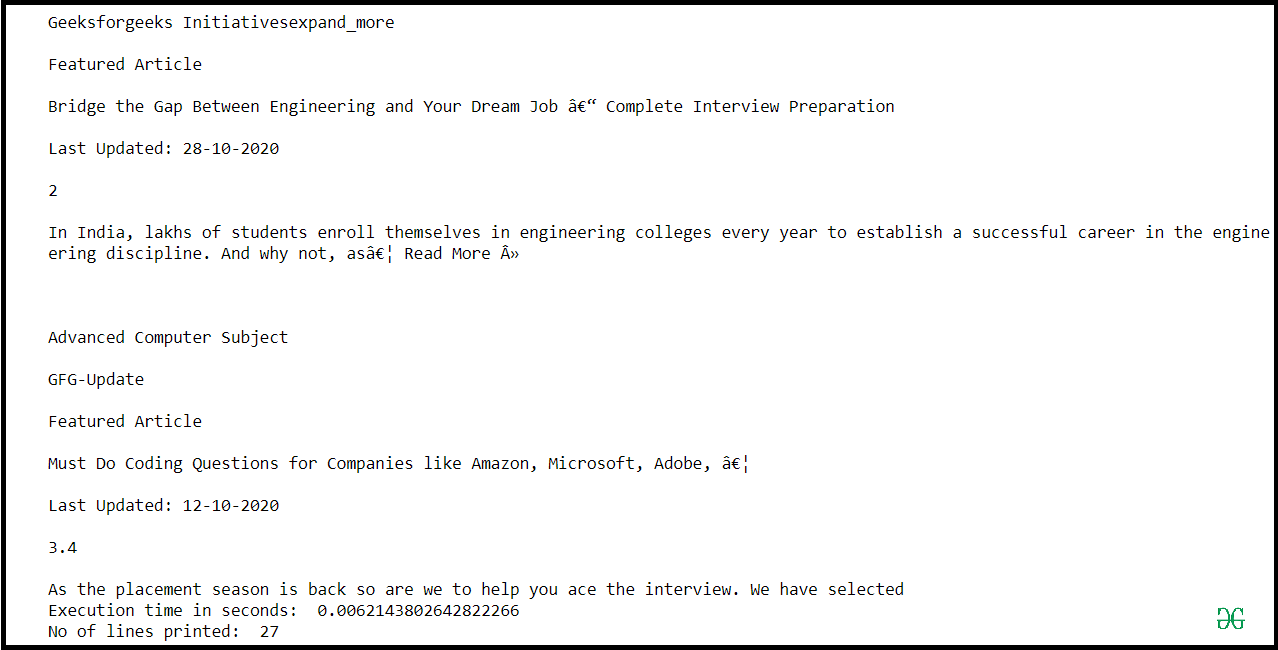
Here are some common use cases for reading a text file in Python:
Processing log files: You might use Python to read log files from a web server or an application, then process the logs to identify trends or patterns. Parsing configuration files: You could write Python code to read configuration files and extract specific settings or values. Analyzing text data: Python's natural language processing libraries, such as NLTK or spaCy, allow you to analyze text data in a variety of ways, from sentiment analysis to topic modeling.Overall, reading a text file is a fundamental operation in any programming language. Python provides several ways to do this, and its flexibility, ease of use, speed, and portability make it a popular choice for many applications.





























