Iter() function Python
Iter() function Python
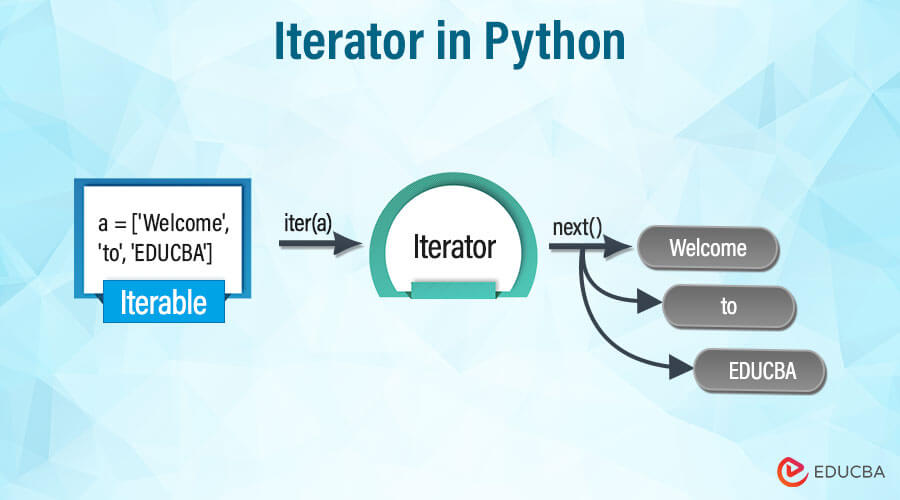
The iter() function in Python! This is a fundamental concept in Python programming that can be quite powerful once you grasp its functionality.
So, what does the iter() function do?
In simple terms, iter() returns an iterator object from any iterable (like a list, tuple, dictionary, set, etc.). An iterator allows you to iterate over a sequence of elements without having to worry about indexing or manually looping through each element. This is particularly useful when dealing with large datasets or complex data structures.
Here's a quick example:
my_list = [1, 2, 3, 4, 5]

my_iter = iter(my_list)
print(next(my_iter)) # Output: 1
print(next(my_iter)) # Output: 2
print(next(my_iter)) # Output: 3
And so on...
As you can see, the iter() function takes an iterable as its argument and returns an iterator object. This iterator object allows us to access each element in the original sequence one at a time using the next() function (or the for loop syntax).
Now, let's talk about how iter() is different from other Python functions.
When you call list() or tuple() on an iterable, you create a new copy of the entire iterable. With iter(), however, you're not creating a copy; you're simply getting an iterator that points to the original sequence.
Here's another example:
my_dict = {'a': 1, 'b': 2, 'c': 3}
my_iter = iter(my_dict.items())
print(next(my_iter)) # Output: ('a', 1)
print(next(my_iter)) # Output: ('b', 2)
And so on...
In this case, the iter() function is used to create an iterator over the items of a dictionary. This allows us to access each key-value pair in the dictionary one at a time.
Lastly, let's touch upon some use cases where iter() can be particularly useful:
iter() lets you iterate over the dataset without having to worry about loading the entire thing. Efficient data processing: By using iterators instead of indexing or looping through each element manually, you can often write more efficient code that's easier to maintain. Generators and coroutines: iter() is essential for building generators and coroutines in Python, which are used extensively in asynchronous programming.
In conclusion, the iter() function is a powerful tool in your Python toolbox. By creating iterators from iterables, you can write more efficient, flexible, and readable code that handles large datasets with ease. So, go ahead and give it a try!
Iter python example w3schools
I'm happy to respond in English! Here's an example of Python code using W3Schools as a reference:
Example: Using the w3lib library to scrape website data
In this example, we'll use the w3lib library to scrape some basic information from the W3Schools website (https://www.w3schools.com/).
First, install the w3lib library:
pip install w3lib
Now, let's create a Python script that uses this library:
import requests
from bs4 import BeautifulSoup
import w3lib
Send a GET request to W3Schools
url = "https://www.w3schools.com/"
response = requests.get(url)
If the GET request is successful, the status code will be 200
if response.status_code == 200:
Get the content of the response
page_content = response.content
Use BeautifulSoup to parse the HTML content
soup = BeautifulSoup(page_content, 'html.parser')
Find all the tags on the page
anchors = soup.find_all('a')
Loop through each anchor tag and print its text
for anchor in anchors:
print(anchor.text)
else:
print("Failed to retrieve webpage")
Explanation:
In this example, we're using the requests library to send a GET request to W3Schools. We then check if the request was successful by checking the status code of the response. If it's 200 (OK), we proceed with parsing the HTML content using BeautifulSoup.
We then find all the <a> tags on the page and loop through them, printing out their text (i.e., the link text). This gives us a list of links that are present on the W3Schools homepage.
Benefits:
Scraping website data: By using libraries likew3lib, we can extract specific data from websites, such as text, images, or even structured data. Handling HTML content: BeautifulSoup allows us to parse and manipulate HTML content in a Python-friendly way. Request handling: The requests library enables us to send requests to websites and handle responses, allowing for more complex web scraping tasks.
Future improvements:
Error handling: Add more robust error handling to handle cases where the request fails or the parsing fails. More specific data extraction: Use more advanced techniques (e.g., regular expressions) to extract specific data from the HTML content, such as specific link URLs or text phrases.Conclusion:
By using libraries like w3lib and manipulating HTML content with BeautifulSoup, we can effectively scrape website data and handle requests. With this foundation, you can build more complex web scraping projects!





























