What is bs4 and BeautifulSoup in Python?
What is bs4 and BeautifulSoup in Python?
I'm happy to help!
What is BS4?
BS4 stands for Beautiful Soup 4, which is a Python library used for parsing HTML and XML documents. It creates a parse tree from the document, allowing you to traverse it and find all the data you want. In other words, BeautifulSoup simplifies the process of working with web scraping in Python by providing an easy-to-use interface for navigating and searching through HTML and XML documents.
What is BeautifulSoup?
BeautifulSoup is a Python package that allows you to parse HTML and XML documents and extract information from them. It's particularly useful when dealing with web scraping, where you need to extract specific data from websites without having to write complex code or manually navigate the website. BeautifulSoup works by creating a parse tree of the document, allowing you to traverse it and find all the data you want.
Key Features of BeautifulSoup:
Parser: BS4 provides several parsers that allow you to parse HTML and XML documents. The most common parser is thelxml parser, which is very fast and efficient. Navigation: Once you've parsed a document, you can navigate it using methods like find, find_all, and select. These methods allow you to search for specific elements in the document. Manipulation: BS4 allows you to manipulate the contents of an HTML or XML document. You can add or remove elements, change their attributes, and modify their text content. Searching: BS4 provides several searching methods that allow you to find specific elements in a document based on their attributes, tags, and other criteria.
Advantages of Using BeautifulSoup:
Easy to use: BS4 is designed to be easy to use, even for developers who are new to web scraping. Fast and efficient: Thelxml parser used by BS4 is very fast and efficient, making it suitable for large-scale web scraping projects. Flexible: BS4 allows you to work with both HTML and XML documents, making it a versatile tool for web scraping.
Example Usage:
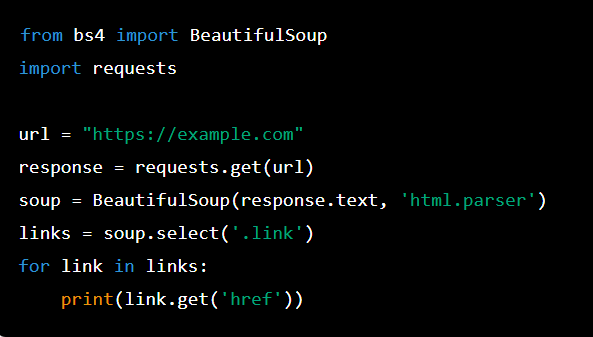
Here's an example of how you might use BeautifulSoup to extract the title of a webpage:
from bs4 import BeautifulSoup Load the HTML document into BeautifulSoupsoup = BeautifulSoup(html_doc, 'html.parser')
Find the title element in the documenttitle = soup.find('title').text
print(title)
In this example, we load an HTML document into BeautifulSoup and then use the find method to locate the <title> element. Finally, we extract the text content of the element using the .text attribute.
Conclusion:
BeautifulSoup (BS4) is a powerful Python library for parsing HTML and XML documents. Its ease of use, flexibility, and speed make it an ideal tool for web scraping projects. Whether you're a seasoned developer or just starting out with web scraping, BS4 is definitely worth checking out!
What does BeautifulSoup do in Python?
BeautifulSoup! It's a fantastic library in Python that helps you scrape and parse HTML and XML documents with ease. Let me tell you more about it.
What is BeautifulSoup?
BeautifulSoup is a Python library that creates a parse tree from an HTML/XML document, allowing you to easily navigate, search, and modify the contents of web pages. It's built on top of the Python standard library for XML parsing (xml.etree.ElementTree) and the lxml library, which provides a Pythonic way of accessing and manipulating XML documents.
How does BeautifulSoup work?
When you create a BeautifulSoup object from an HTML/XML document, it creates a parse tree, which is essentially a hierarchical representation of the document's structure. You can then navigate this tree using various methods, such as:
Tags: Find specific tags (e.g., , ) or attributes (e.g., class, id) within the HTML/XML document. Attributes: Access and modify attribute values (e.g., href, src, alt). Text: Extract text content from a tag or navigate to a sibling or child node.Why use BeautifulSoup?
Ease of use: BeautifulSoup provides an intuitive way to work with HTML/XML documents, making it perfect for beginners and experts alike. Flexibility: You can parse both HTML and XML documents using the same library. Efficiency: BeautifulSoup is highly optimized for speed and memory efficiency. Robustness: It handles malformed or missing tags, attributes, and content with ease.Some use cases:
Web scraping: Extract data from web pages, such as product information, prices, reviews, and more. Data integration: Combine data from multiple sources by parsing and transforming HTML/XML documents. Automation: Use BeautifulSoup to automate tasks that involve working with HTML/XML documents, such as creating reports or sending notifications.Getting started:
To use BeautifulSoup in your Python projects, you'll need to:
Install the library using pip (pip install beautifulsoup4). Import the library (from bs4 import BeautifulSoup). Create a BeautifulSoup object from an HTML/XML document (e.g., bs = BeautifulSoup(html, 'html.parser')).
BeautifulSoup is an incredibly powerful tool for working with web documents in Python. With its ease of use and flexibility, it's no wonder why it's one of the most popular libraries among web developers, data scientists, and automation experts.
Hope this helps!