How to Scrapy with Python?
How to Scrapy with Python?

Here is a comprehensive guide on how to scrape with Python:
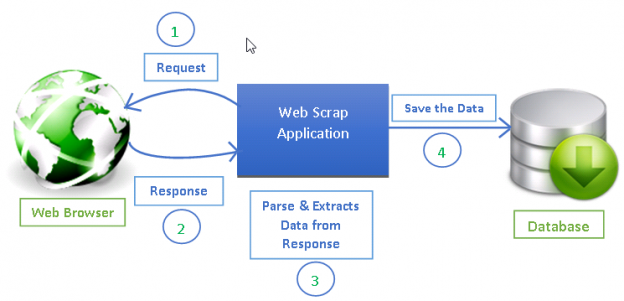
What is Web Scraping?
Web scraping, also known as web data extraction or web crawling, is the process of automatically extracting data from websites. This is done by sending HTTP requests to a website and parsing the HTML response to extract the desired data.
Why Use Python for Scraping?
Python is an excellent choice for web scraping due to its simplicity, flexibility, and extensive libraries. Some of the reasons why you should use Python for scraping include:
Easy to learn: Python has a syntax that's easy to understand, even for those without prior programming experience. Fast execution: Python is a high-level language, which means it can execute code quickly and efficiently. Extensive libraries: Python has a vast collection of libraries and modules that can help with tasks such as HTML parsing, data manipulation, and more.Tools Required
To get started with web scraping in Python, you'll need:
Python installed on your computer (you can download it from the official Python website if you don't have it already).
Basic Steps
Here are the basic steps involved in web scraping with Python:
Send an HTTP Request: Use a library likerequests to send an HTTP request to the website you want to scrape. Parse the HTML Response: Use a library like BeautifulSoup to parse the HTML response and extract the desired data. Extract the Data: Loop through the parsed HTML content and extract the data you need using techniques such as CSS selectors, regular expressions, or XPath expressions. Store the Data: Store the extracted data in a file, database, or other format for further analysis or use.
Scrapy Library
Scrapy is a popular Python library for web scraping that provides a high-level framework for building scrapers. Scrapy simplifies tasks like:
Sending HTTP requests and parsing HTML responses. Handling different types of content (e.g., text, images, JSON). Storing data in various formats (e.g., CSV, SQLite).Scrapy also provides features such as:
Handling common scraping challenges, like handling cookies, JavaScript-generated content, and CAPTCHAs. Supporting parallel processing for faster execution.Example Code
Here's an example of how you might use Scrapy to scrape a website:
import scrapy
class MySpider(scrapy.Spider):
name = "my_spider"
start_urls = ["https://www.example.com"]
def parse(self, response):
Extract data from the HTML content
title = response.css("title::text").get()
links = response.css("a::attr(href)").getall()
Store the extracted data
with open("data.txt", "w") as f:
f.write(f"Title: {title}nLinks: {links}")
This example spider sends an HTTP request to https://www.example.com, extracts the title and links from the HTML content, and stores the data in a file named data.txt.
Best Practices
When web scraping with Python (or any language), it's essential to follow best practices to avoid:
Overwhelming the website with requests. Violating website terms of service or copyright laws. Extracting sensitive or personal data without permission.Some tips for responsible web scraping include:
Start small and test your scraper on a small subset of data before scaling up. Use user agents that mimic common browsers to avoid detection. Handle errors and exceptions properly to prevent crashes and data loss. Store extracted data in a secure, organized manner for further analysis or use.Conclusion
Web scraping with Python is an exciting field that allows you to extract valuable data from websites. With Scrapy, you can build robust scrapers that handle common challenges and provide a foundation for more complex scraping projects. By following best practices and using libraries like BeautifulSoup or Scrapy, you'll be well on your way to becoming a proficient web scraper in Python.
Scrapy Python documentation
I'm happy to provide you with information about the Scrapy Python framework in English!
What is Scrapy?
Scrapy is a Python library used for building web scrapers, which extract data from websites. It's a powerful and flexible tool that simplifies the process of extracting and processing data from websites.
Why use Scrapy?
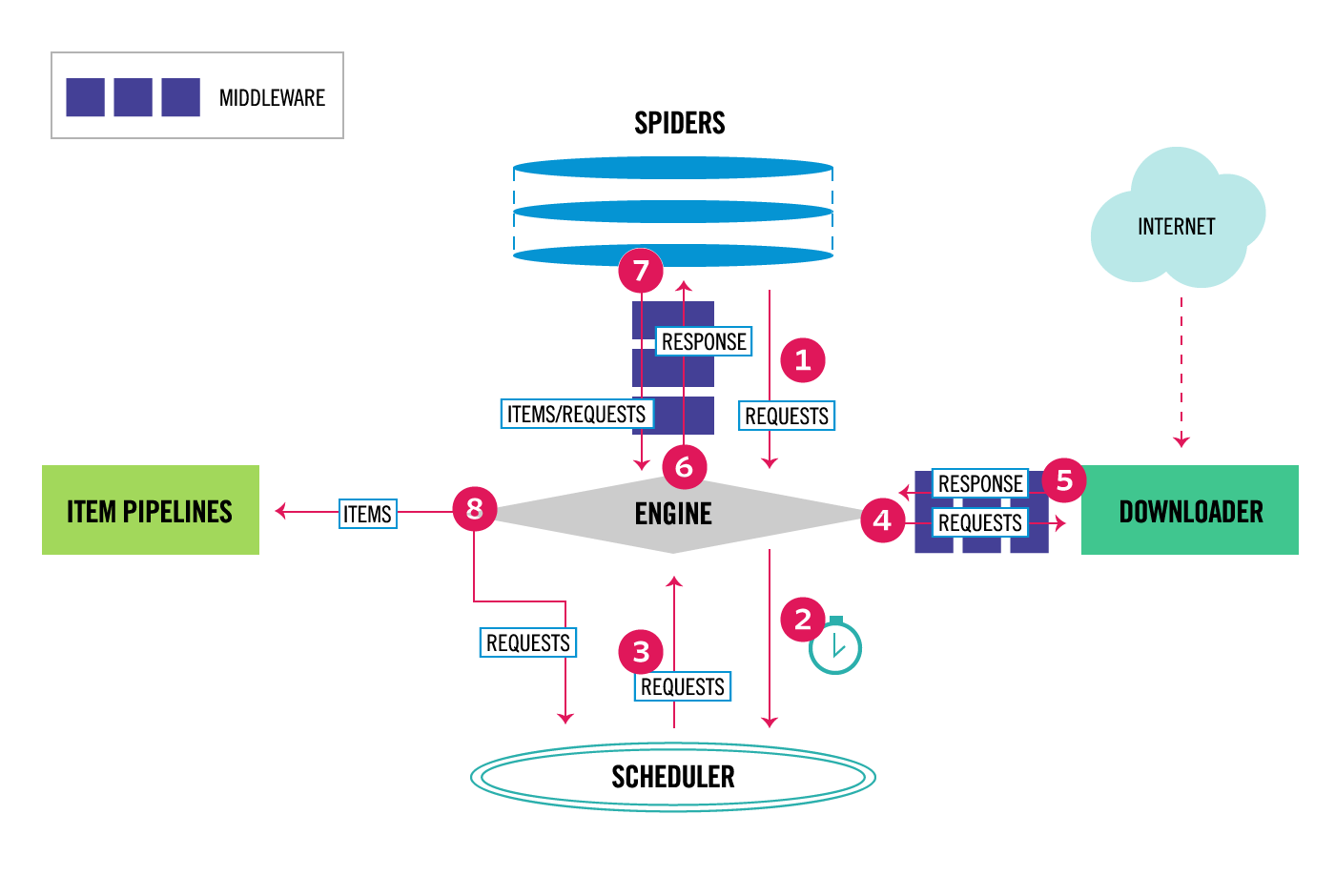
There are several reasons why you might want to use Scrapy:
Data extraction: Scrapy allows you to extract specific data from websites, such as prices, product information, or contact details. Web scraping: Scrapy is designed for web scraping, which involves extracting and processing data from websites in an automated manner. Flexibility: Scrapy provides a flexible framework that can be used for various types of web scraping projects.Getting started with Scrapy
To get started with Scrapy, follow these steps:
Install Scrapy: You can install Scrapy using pip:pip install scrapy Create a new project: Use the command scrapy startproject <project_name> to create a new Scrapy project. Write your spider: Write a Python script that defines how to extract data from a website.
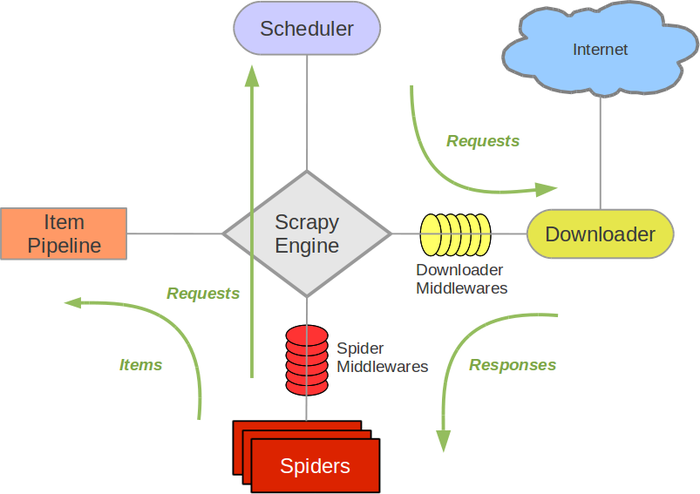
Scrapy's architecture
Scrapy's architecture is divided into several components:
Spiders: These are the actual Python scripts that define how to extract data from websites. Item pipelines: These determine what happens to the extracted data once it has been processed. Middleware: This refers to third-party code that can be used to extend Scrapy's functionality.Scrapy's features
Some of Scrapy's key features include:
Handling different formats: Scrapy supports multiple data formats, such as JSON and CSV. Error handling: Scrapy provides built-in support for error handling, making it easier to handle situations where the website is down or returns an error. Scheduling: You can use Scrapy's scheduling feature to run your scrapers at specific times or intervals.Scrapy's limitations
While Scrapy is a powerful tool, there are some limitations you should be aware of:
Website restrictions: Some websites may have terms and conditions that prohibit web scraping. Data quality issues: Web scraping can result in data quality issues if the website changes its structure or content. Scraping frequency limits: Some websites may limit how frequently you can scrape their data.Conclusion
In conclusion, Scrapy is a powerful Python library used for building web scrapers and extracting data from websites. With its flexible framework, built-in support for error handling, and scheduling feature, Scrapy is an excellent choice for anyone looking to automate data extraction tasks.