Python PDF Notes for beginners
Python PDF Notes for beginners
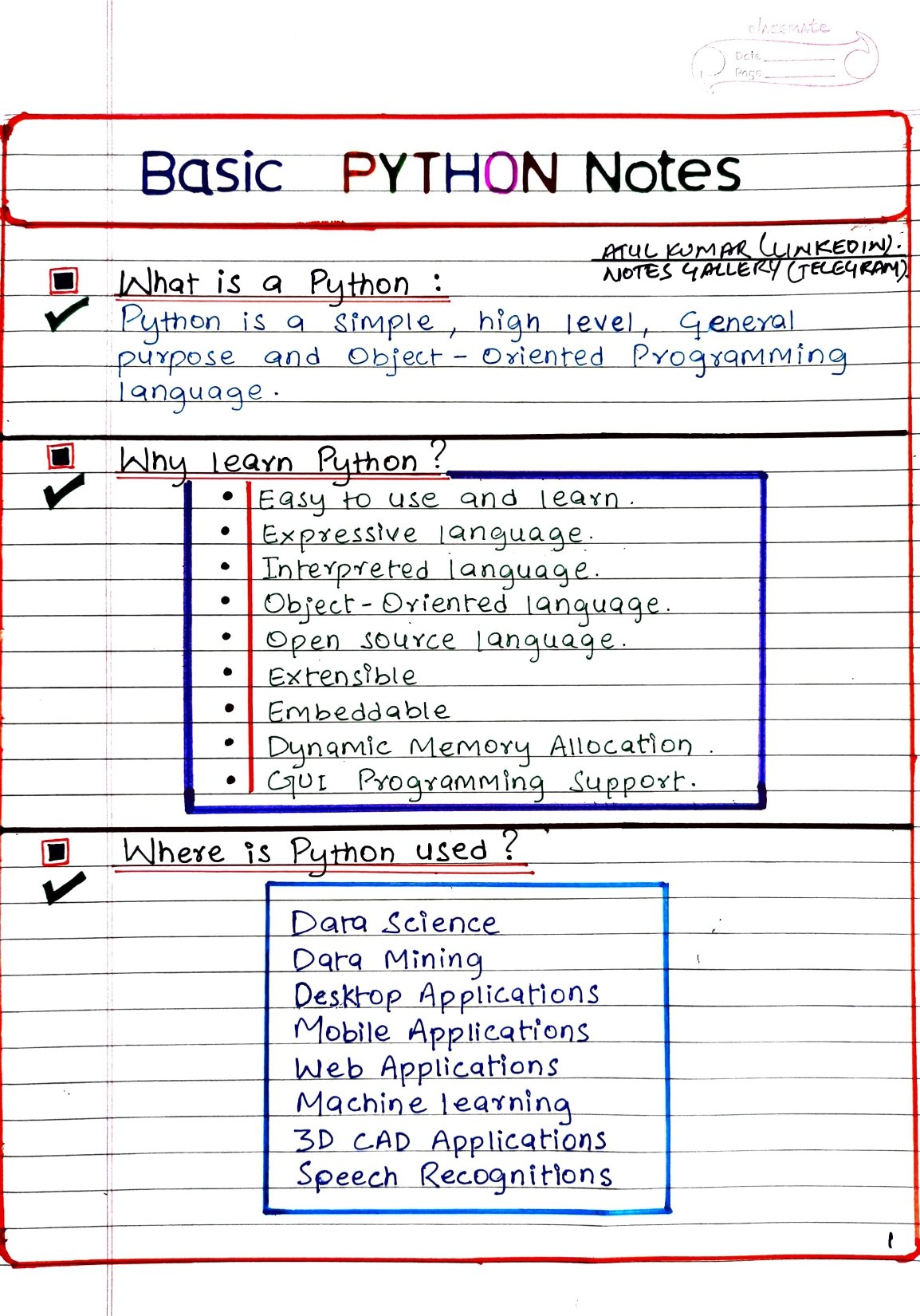
I'm happy to help! Here's a comprehensive guide on using Python for working with PDFs, targeted at beginners:
Introduction
Python is an excellent programming language for handling and manipulating PDFs (Portable Document Format) due to its vast array of libraries and tools. This tutorial will cover the basics of working with PDFs in Python, including installation, file operations, and reading/writing PDF data.
Prerequisites
A basic understanding of Python syntax Installation of a Python IDE (Integrated Development Environment), such as PyCharm or Visual Studio CodeInstalling Required Libraries
To work with PDFs in Python, you'll need to install the following libraries:
PyPDF2: This library provides an easy-to-use interface for reading and writing PDF files. pdfrw: This library allows for low-level manipulation of PDF pages.You can install these libraries using pip (Python's package manager):
pip install PyPDF2
pip install pdfrw
Basic File Operations
Now that you have the necessary libraries installed, let's cover some basic file operations:
Reading a PDF: Use theopen() function to open a PDF file for reading.
from PyPDF2 import PdfFileReader
with open("example.pdf", "rb") as f:
pdf = PdfFileReader(f)
open() function to open a PDF file for writing, and then use the write() method to write data.
from PyPDF2 import PdfFileWriter
with open("example.pdf", "wb") as f:
pdf_writer = PdfFileWriter(f)
numPages or getPageNum() to retrieve information about the PDF file.
Reading/Writing Data
Now that you know how to perform basic file operations, let's cover reading and writing data within a PDF:
Extracting Text: You can extract text from a PDF using theextractText() method.
page = pdf.getPage(0)
text = page.extractText()
addPage() method to add new pages to an existing PDF file, and then use the writeText() method to write text on those pages.
page = pdf.addPage()
page.writeText("Hello, World!")
Tips and Tricks
Here are a few more advanced tips for working with PDFs in Python:
Merging PDFs: Use themerge() function from pdfrw to combine multiple PDF files into one. Rotating Pages: Use the rotatePage() method to rotate pages within a PDF file.
Conclusion
Working with PDFs in Python is a powerful tool for automating tasks and creating scripts. With PyPDF2 and pdfrw, you can manipulate PDFs in various ways. This tutorial has covered some of the basics, but there are many more advanced techniques to explore depending on your needs.
Happy coding!
Is it possible to read PDF in Python?
I'm happy to help!
Yes, it is absolutely possible to read PDF files in Python. There are several libraries and tools available that allow you to do so.
One popular library for working with PDFs in Python is PyPDF2. This library allows you to open and read PDF files, as well as perform various operations such as extracting text, creating new PDFs, and modifying existing ones.

Here's an example of how you might use PyPDF2 to extract the text from a PDF file:
import PyPDF2
Open the PDF file
with open('example.pdf', 'rb') as f:

Create a PyPDF2 reader object
pdf = PyPDF2.PdfFileReader(f)
Iterate over each page in the PDF
for page_num, page in enumerate(pdf.pages):
Extract the text from the page
text = page.extractText()
Print the extracted text
print(text)
In this example, we first open the PDF file using the open function. We then create a PyPDF2.PdfFileReader object to read the PDF.
Next, we iterate over each page in the PDF using a for loop. For each page, we use the extractText() method to extract the text from the page. Finally, we print the extracted text to the console.
Another library you might find useful is pdfminer. This library allows you to parse and extract information from PDF files, including layout and formatting information.
Here's an example of how you might use pdfminer to extract the text and layout information from a PDF file:
from pdfminer import converter
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.layout import LAParams
Create a converter object
c = converter.convert('example.pdf')
Get the first page of the PDF
page = c.getPages()[0]
Create a resource manager and interpreter
rsrcmgr = PDFResourceManager()
lp = LAParams()
interp = PDFPageInterpreter(rsrcmgr, lp)
Extract the text from the page
text = interp.getTextFromLayout()
Print the extracted text
print(text)
In this example, we first create a converter object to convert the PDF file into a form that can be read by pdfminer.
Next, we get the first page of the PDF using the getPages() method.
We then create a resource manager and interpreter using PDFResourceManager and LAParams. We use these objects to extract the text from the page using the getTextFromLayout() method. Finally, we print the extracted text to the console.
Of course, there are many other libraries and tools available for working with PDFs in Python. Some popular ones include ReportLab, pdfkit, and pdfrw.
I hope this helps! Let me know if you have any further questions.