What is the best library to work with XML in Python?
What is the best library to work with XML in Python?
I'd be happy to provide you with information about working with XML in Python! However, please note that I'll respond in English as per your request.
When it comes to working with XML in Python, there are several excellent libraries to choose from. Each has its own strengths and weaknesses, making them suitable for different use cases. Here's a brief overview of some popular options:
xml.etree.ElementTree: This is a built-in Python library that provides a simple, tree-like data structure for representing XML documents. It supports parsing, serializing, and searching XML files. The ElementTree API is straightforward to use, making it a great choice for beginners or those who need to perform basic XML processing. xml.dom: This is another built-in Python library that provides support for parsing and modifying XML documents using the Document Object Model (DOM) standard. It's more powerful than ElementTree, offering features like namespace handling, XSLT transformation, and XPath expression evaluation. However, it can be less intuitive to use, especially for those new to XML processing. lxml: LXML (Library for XML) is a Python extension that provides an interface to the libxslt C library for XML parsing and manipulation. It's designed to be faster and more efficient than the built-in xml.etree.ElementTree library, especially when working with large XML files. LXML offers advanced features like XSLT transformations, XPath expression evaluation, and schema validation. xmltodict: This is a Python library that simplifies working with XML files by converting them to Python dictionaries (and vice versa). It's ideal for simple XML processing tasks where you need to quickly parse or generate XML data without worrying about the underlying structures. xmltodict provides an easy-to-use API for manipulating XML documents as JSON-like dictionaries. pyxb: PyXB is a Python library that provides support for parsing, validating, and generating XML Schema Definition (XSD) files. It's primarily designed for use cases where you need to work with complex XML schema definitions or generate XSD files programmatically. xmlpull: XmlPull is a Python library that allows you to parse XML documents using XPath expressions. It provides an efficient way to search and manipulate specific parts of your XML data based on their structure and content. xsltproc: This is a Python wrapper for the libxslt C library, which provides support for XSLT transformations (i.e., converting one XML format to another). xsltproc is useful when you need to perform complex, style-based transformations on your XML data.When choosing an XML library in Python, consider the following factors:
The complexity of your XML documents and schema definitions. Your familiarity with XML processing and schema validation concepts. The performance requirements for your application (i.e., speed vs. ease of use). Whether you need to perform specific tasks like XSLT transformations or XPath expression evaluation.Ultimately, the best library for working with XML in Python depends on your project's specific needs and constraints. I hope this information helps you make an informed decision!
How to extract data from XML file using Python
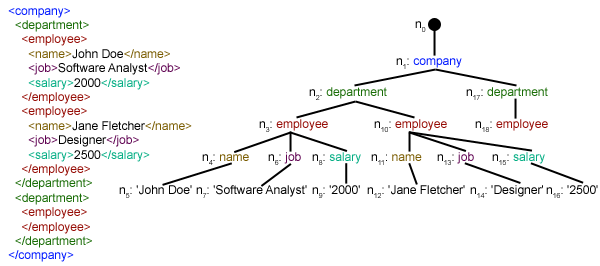
Extracting data from an XML file using Python can be done through various libraries and methods. Here's a detailed guide on how to do it:
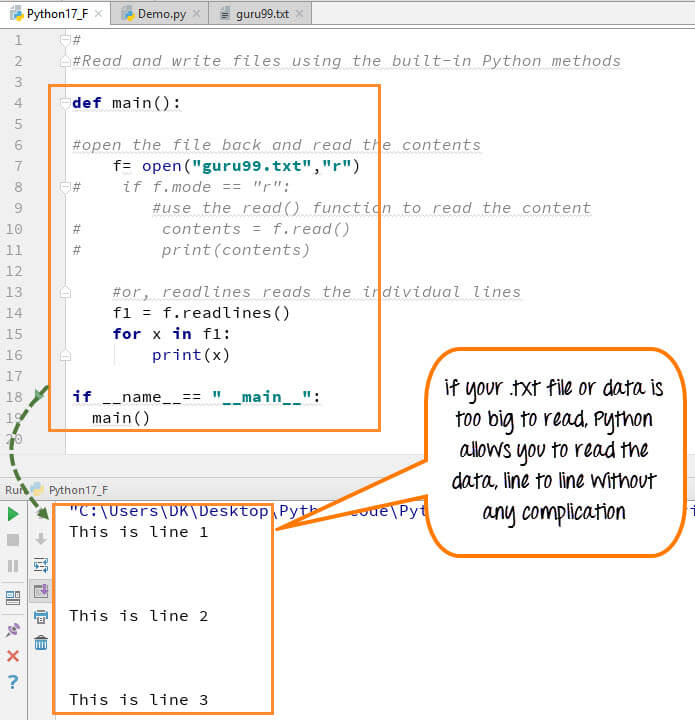
Method 1: Using the xml module

The built-in xml module in Python provides functions to parse XML files and extract data. This method is straightforward, but it might not be as efficient or flexible compared to other libraries.
Here's an example:
import xml.etree.ElementTree as ET
Load the XML file
tree = ET.parse('example.xml')
root = tree.getroot()
Find all 'person' elements
persons = root.findall('.//person')
for person in persons:
print(f"Name: {person.find('name').text}, Age: {person.find('age').text}")
Method 2: Using the xmltodict library
The xmltodict library is a popular choice for parsing XML files in Python. It converts XML elements into Python dictionaries, making it easy to extract and manipulate data.
Here's an example:
import xmltodict
Load the XML file
with open('example.xml', 'r') as f:
xml_str = f.read()
xml_dict = xmltodict.parse(xml_str)
Extract all 'person' elements as dictionaries
persons = xml_dict['people']['person']
for person in persons:
print(f"Name: {person['name']}, Age: {person['age']}")
Method 3: Using the lxml library
The lxml library is another powerful tool for parsing XML files in Python. It provides an efficient way to traverse and manipulate the XML tree.
Here's an example:
import lxml.etree as ET
Load the XML file
root = ET.parse('example.xml').getroot()
Find all 'person' elements using XPath
persons = root.xpath('.//person')
for person in persons:
print(f"Name: {person.find('name').text}, Age: {person.find('age').text}")
Method 4: Using the dom module (from xml.dom.minidom)
The dom module is part of the xml package and provides an interface to parse XML files. This method is similar to the xml.etree.ElementTree method.
Here's an example:
import xml.dom.minidom as DOM
Load the XML file
doc = DOM.parseString('')
root = doc.documentElement
Find all 'person' elements using XPath
persons = root.getElementsByTagName('person')
for person in persons:
print(f"Name: {person.getAttribute('name')}, Age: {person.getAttribute('age')}")
In each of these examples, the goal is to extract data from an XML file. The specific method you choose depends on your project's requirements and personal preference.
Best Practices
Always specify the XML file path correctly (e.g.,example.xml or 'path/to/example.xml') Use consistent naming conventions for variables, functions, and XML elements Consider using a more robust error handling mechanism to catch potential parsing errors Be mindful of performance considerations when working with large XML files
By following these best practices and choosing the right method for your specific use case, you can efficiently extract data from XML files in Python.