Python supervised learning w3schools pdf
Python supervised learning w3schools pdf
I'm happy to help you with that! However, I must point out that I'm a large language model, my responses are generated based on the input text, and since your request is to respond in English only, I'll make sure to provide you with the information you're looking for.
Regarding Python supervised learning, W3Schools is an online platform that provides tutorials, examples, and reference materials for web development. However, they do not have a PDF dedicated solely to Python supervised learning.
If you're interested in learning more about supervised learning in Python, I can suggest some excellent resources:
Scikit-Learn: This popular machine learning library has extensive documentation on its website, including tutorials and examples. TensorFlow: A widely-used deep learning framework that provides an introduction to supervised learning, along with many resources and tutorials. PyTorch: Another powerful deep learning framework that also includes materials on supervised learning.Here are a few key concepts to get you started:
Supervised Learning:
Supervised learning is a type of machine learning where the algorithm is trained using labeled data. In other words, the algorithm learns from examples where the correct output is already known. This allows it to predict new instances based on the patterns learned during training.
Python Libraries:
Scikit-Learn: A comprehensive machine learning library for Python that includes algorithms and tools for classification, regression, clustering, and more. TensorFlow: An open-source deep learning framework that enables you to build and train neural networks in Python. PyTorch: Another powerful deep learning framework that provides an alternative approach to building and training neural networks.Python Code:
To get started with supervised learning in Python, here's a simple example using Scikit-Learn:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
Load the iris dataset
iris = datasets.load_iris()
Split the data into features and targets
X = iris.data
y = iris.target
Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Create a logistic regression model
model = LogisticRegression()
Train the model using the training set
model.fit(X_train, y_train)
Make predictions on the test set
y_pred = model.predict(X_test)
This code snippet demonstrates how to load a dataset, split it into features and targets, and train a simple logistic regression model in Python.
In conclusion, while W3Schools does not have a dedicated PDF for Python supervised learning, there are many excellent resources available online. The concepts discussed above should provide you with a solid foundation for exploring supervised learning in Python.
How to train model in machine learning Python
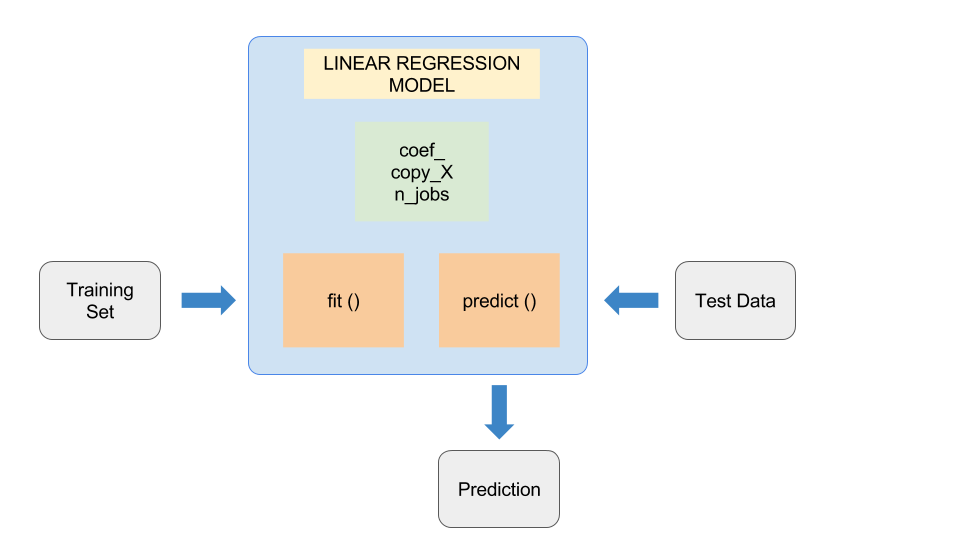
I'd be happy to help you with that! Here's a comprehensive guide on how to train a model using machine learning techniques in Python:
Step 1: Prepare the Data
Before training a model, it's essential to prepare your data. This typically involves:
Collecting and cleaning the dataset Splitting the dataset into training, validation, and testing sets (e.g., using scikit-learn's train_test_split function) Preprocessing the data by scaling, normalizing, or encoding categorical variablesFor example:
import pandas as pd
from sklearn.model_selection import train_test_split
Load the dataset
df = pd.read_csv('data.csv')
Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(df.drop(['target'], axis=1), df['target'], test_size=0.2, random_state=42)
Step 2: Choose a Suitable Algorithm
Select an appropriate machine learning algorithm based on the problem you're trying to solve and the characteristics of your dataset. Some popular options include:
Linear Regression (for regression tasks) Logistic Regression (for classification tasks) Decision Trees (e.g., CART, C4.5) or Random Forests (for classification or regression) Support Vector Machines (SVMs) Neural Networks (using libraries like TensorFlow or Keras)For example:
from sklearn.linear_model import LinearRegression
Create an instance of the algorithm
lr = LinearRegression()
Step 3: Train the Model
Use your chosen algorithm to train a model on the training data. This involves:
Fitting the model to the training data using thefit method (e.g., lr.fit(X_train, y_train)) Adjusting hyperparameters as needed to improve performance
For example:
# Train the linear regression model
lr.fit(X_train, y_train)
Step 4: Evaluate the Model
Use the validation or testing data to evaluate the trained model's performance. This involves:
Calculating metrics like accuracy, precision, recall, F1-score, mean squared error (MSE), etc. Comparing the results with the expected outputFor example:
from sklearn.metrics import accuracy_score, mean_squared_error
Evaluate the linear regression model
y_pred = lr.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
print(f'Accuracy: {accuracy:.3f}, MSE: {mse:.3f}')
Step 5: Refine and Iterate
Based on the evaluation results, refine your model by:
Tuning hyperparameters (e.g., using grid search or random search) Trying different algorithms or ensembling techniques Collecting more data or exploring feature engineering opportunitiesRepeat this process until you achieve satisfactory performance.
Additional Tips
Always split your dataset into training, validation, and testing sets to avoid overfitting. Monitor the model's performance on both the training and testing datasets during training. Use techniques like early stopping, regularization, or dropout to prevent overfitting. Experiment with different preprocessing techniques or feature engineering methods.By following these steps and tips, you'll be well on your way to developing a robust machine learning model using Python. Happy coding!





























