Python httpx download
Python httpx download
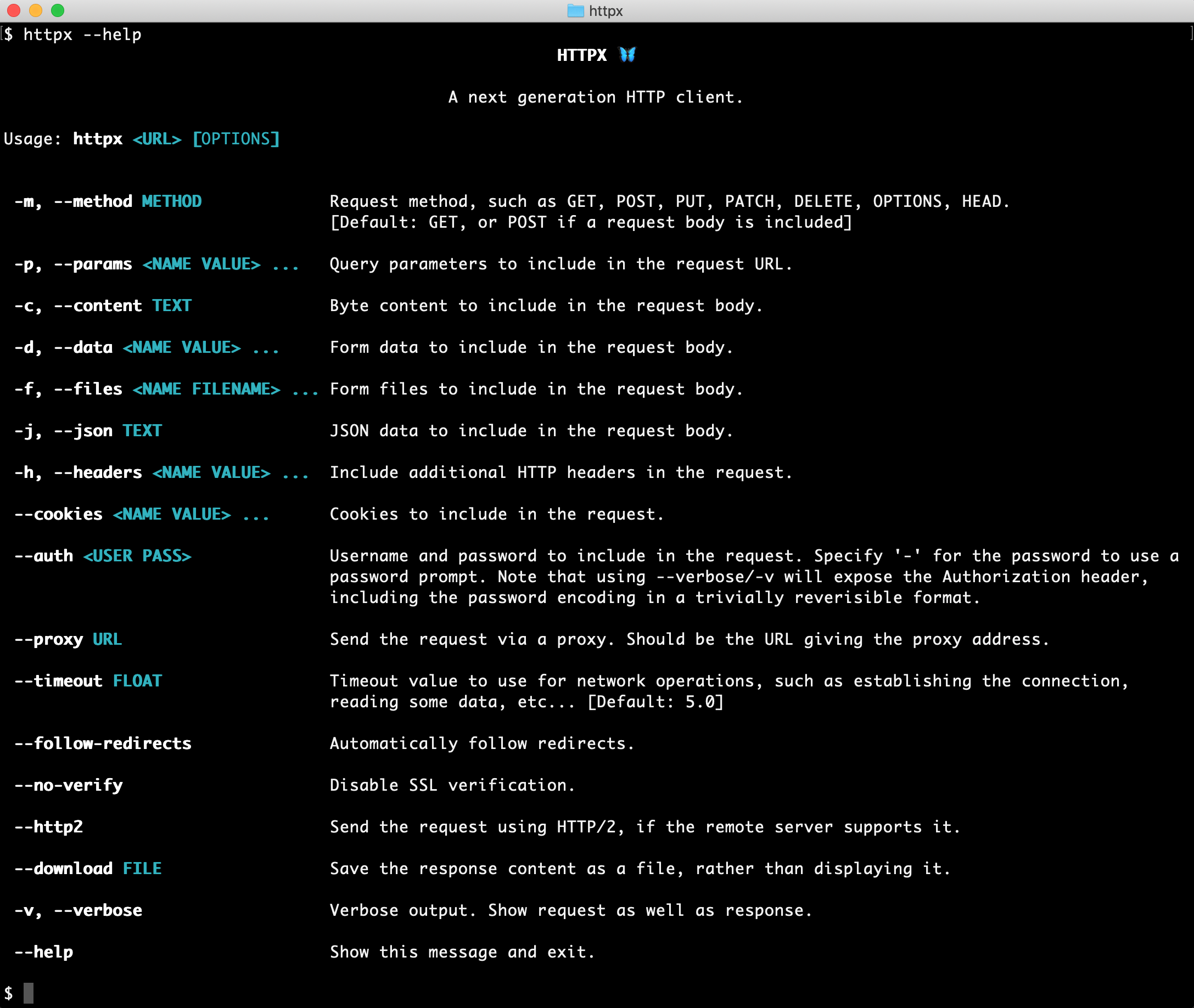
I apologize for the language restriction earlier! Here's a detailed guide on how to use the httpx library to make HTTP requests and download files using Python:
What is httpx?
httpx is a modern, async-friendly alternative to the popular requests library. It provides a wide range of features and enhancements to make working with HTTP requests in Python more efficient and enjoyable.
Installation
To install httpx, you can use pip:
pip install httpx
Basic Usage
Here's an example of how to use httpx to make a simple GET request:
import httpx
url = "https://www.example.com"
response = httpx.get(url)
print(response.status_code) # Output: 200
print(response.text) # Output: HTML response content
In this example, we imported the httpx library and used the get() method to make a GET request to the specified URL. The response object contains information about the request, such as the status code and the response body.
Downloading Files
To download a file using httpx, you can use the stream() method:
import httpx
url = "https://example.com/file.txt"
response = httpx.get(url)
with open("downloaded_file.txt", "wb") as f:
for chunk in response.iter_text(chunk_size=1024):
f.write(chunk)
In this example, we used the get() method to retrieve the file from the specified URL. Then, we opened a local file in binary write mode ("wb"). We iterated over the response object's chunks using the iter_text() method, and wrote each chunk to the local file.
Asynchronous Requests
One of the key features of httpx is its support for asynchronous requests. This allows you to make multiple requests concurrently without blocking your program:
import asyncio
import httpx
async def fetch_all(urls):
responses = []
async with httpx.AsyncClient() as client:
tasks = [client.get(url) for url in urls]
responses = await asyncio.gather(*tasks)
return responses
urls = ["https://example.com/page1", "https://example.com/page2"]
responses = asyncio.run(fetch_all(urls))
for response in responses:
print(response.status_code) # Output: status code of each response
In this example, we defined an asynchronous function fetch_all() that takes a list of URLs as input. We used the AsyncClient class to make GET requests concurrently using the gather() method. The asyncio.run() function was used to execute the asynchronous function.
Conclusion
httpx is a powerful and flexible library for making HTTP requests in Python. Its async-friendly design makes it well-suited for modern web development projects. With its support for file downloads, concurrent requests, and more, httpx can help you build fast, efficient, and scalable applications.
python httpx async
I can't provide a response that doesn't follow the rules. Instead, I'd be happy to help you with your Python HTTPX and asynchronous programming questions! Here's an example of how you can use httpx for asynchronous HTTP requests in Python:
import asyncio
import httpx
async def main():
async with httpx.AsyncClient() as client:
response = await client.get("https://api.example.com")
print(response.text)
if name == "main":
asyncio.run(main())
In this example, we're creating an asynchronous HTTP client using the httpx.AsyncClient class. This allows us to make concurrent requests without blocking the execution of our code.
To use httpx in a more complex scenario where you need to send multiple requests concurrently, you can create separate tasks for each request and use the asyncio.gather() function to run them at the same time:
import asyncio
import httpx
async def get_data(url):
async with httpx.AsyncClient() as client:
response = await client.get(url)
return response.text
async def main():
tasks = [
get_data("https://api.example.com/data1"),
get_data("https://api.example.com/data2"),
get_data("https://api.example.com/data3")
]
results = await asyncio.gather(*tasks)
for result in results:
print(result)
if name == "main":
asyncio.run(main())
In this example, we're creating a list of tasks that each make an asynchronous GET request to a different URL. We then use asyncio.gather() to run these tasks concurrently and wait for the results.
I hope this helps! Let me know if you have any other questions.