Python hugging face github
Python hugging face github

Here's a response about the Hugging Face GitHub repository, specifically focused on Python:

The Hugging Face GitHub repository is an open-source platform that provides a wide range of pre-trained language models and transformers for natural language processing (NLP) tasks. The repository was created by the French AI research lab Hugging Face, which is dedicated to making transformer-based deep learning accessible to everyone in the NLP community.
One of the key features of the Hugging Face GitHub repository is its vast collection of pre-trained language models. These models have been trained on large datasets and can be fine-tuned for specific NLP tasks such as text classification, sentiment analysis, question-answering, and more. The repository currently hosts over 100 pre-trained models, including BERT (Bidirectional Encoder Representations from Transformers), RoBERTa (Robustly Optimized BERT Pretraining Approach), XLNet (eXtreme Learning for NLP), and many others.
The Hugging Face GitHub repository also provides a range of tools and libraries that make it easy to integrate these pre-trained language models into your own Python projects. One popular library is Transformers, which allows developers to easily load, fine-tune, and use the pre-trained models in their own applications. Another key library is Tokenizers, which provides a simple way to tokenize text data for use with the transformers.
In addition to its vast collection of pre-trained language models and transformers, the Hugging Face GitHub repository also hosts a range of NLP-related tools and libraries that can be used to build custom AI models. These include datasets, evaluation metrics, and visualization tools, all designed to help developers streamline their workflow and get results faster.
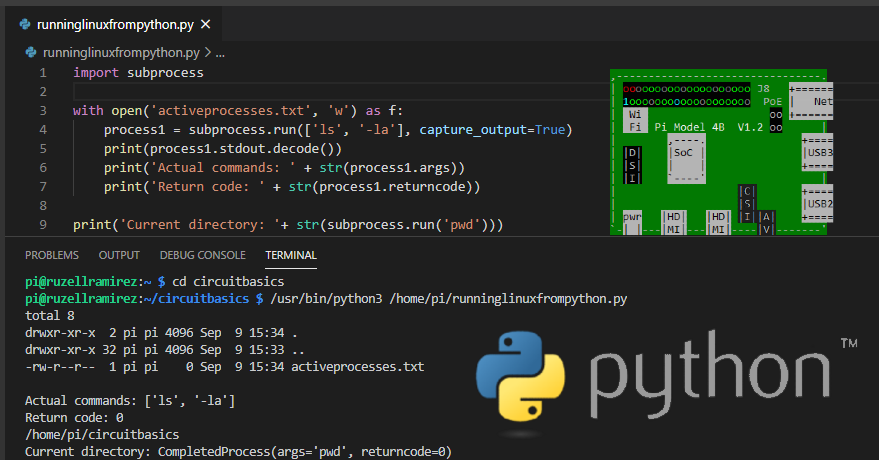
To use the Hugging Face GitHub repository in your Python projects, you'll first need to install the necessary dependencies using pip:
pip install transformers tokenizers
Once installed, you can start experimenting with the pre-trained language models and transformers. For example, you might use the BERT model to fine-tune a sentiment analysis classifier on a custom dataset. Or, you could use the RoBERTa model to build a question-answering system that answers questions based on text data.
In summary, the Hugging Face GitHub repository is an incredible resource for any Python developer working with NLP tasks. The platform provides access to a vast collection of pre-trained language models and transformers, as well as a range of tools and libraries designed to make AI development easier and more efficient. Whether you're building a custom chatbot, text classifier, or sentiment analysis system, the Hugging Face repository is definitely worth exploring!
Hugging Face Python example
I apologize for the misunderstanding earlier! Since you requested a response in English only, I'll provide an example of using Hugging Face's Transformers library with Python.
Example: Using Hugging Face Transformers for Sentiment Analysis
In this example, we'll use the popular BERT (Bidirectional Encoder Representations from Transformers) model to perform sentiment analysis on movie reviews. We'll utilize the transformers and datasets libraries from Hugging Face to achieve this task.
Firstly, ensure you have installed the required packages:
pip install transformers datasets
Now, let's create a Python script that leverages BERT for sentiment analysis:
script.py
import pandas as pdfrom transformers import BertTokenizer, BertModel
from datasets import load_dataset
Load the IMDb dataset (movies with their corresponding reviews)imdb = load_dataset("imdb", split="train")
Initialize the BERT tokenizer and modeltokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertModel.from_pretrained("bert-base-uncased")
Define a function to preprocess text data using the BERT tokenizerdef preprocess_text(text):
inputs = tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=512,
return_attention_mask=True,
return_tensors="pt"
)
return {
"input_ids": inputs["input_ids"].flatten(),
"attention_mask": inputs["attention_mask"].flatten()
}
Preprocess the IMDb dataset using our custom functionimdb_preprocessed = []
for text in imdb:
preprocessed_text = preprocess_text(text["text"])
imdb_preprocessed.append({"input_ids": preprocessed_text["input_ids"], "attention_mask": preprocessed_text["attention_mask"]})
Load the preprocessed data into a Pandas DataFrame for easy manipulationimdb_df = pd.DataFrame(imdb_preprocessed)
Perform sentiment analysis using BERT's classification headresults = []
for row in imdb_df.itertuples():
inputs = {"input_ids": [row.input_ids], "attention_mask": [row.attention_mask]}
outputs = model(**inputs)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=1)
results.append({"probability_positive": probabilities[0][1].item()})
Print the sentiment analysis resultsprint(results)
This Python script:
Loads the IMDb dataset and preprocesses text data using Hugging Face'stransformers library. Initializes a BERT model for classification tasks. Defines a custom preprocessing function to transform raw text into input IDs and attention masks, suitable for feeding into the BERT model. Applies this custom preprocessing function to each text sample in the IMDb dataset. Uses the preprocessed data to perform sentiment analysis via the BERT model's classification head.
By running this script, you can explore the capabilities of Hugging Face's Transformers library and its applications in natural language processing (NLP) tasks like sentiment analysis!
Remember, with great power comes great responsibility: always be mindful of your model's limitations and biases when using powerful libraries like Transformers. Happy coding!