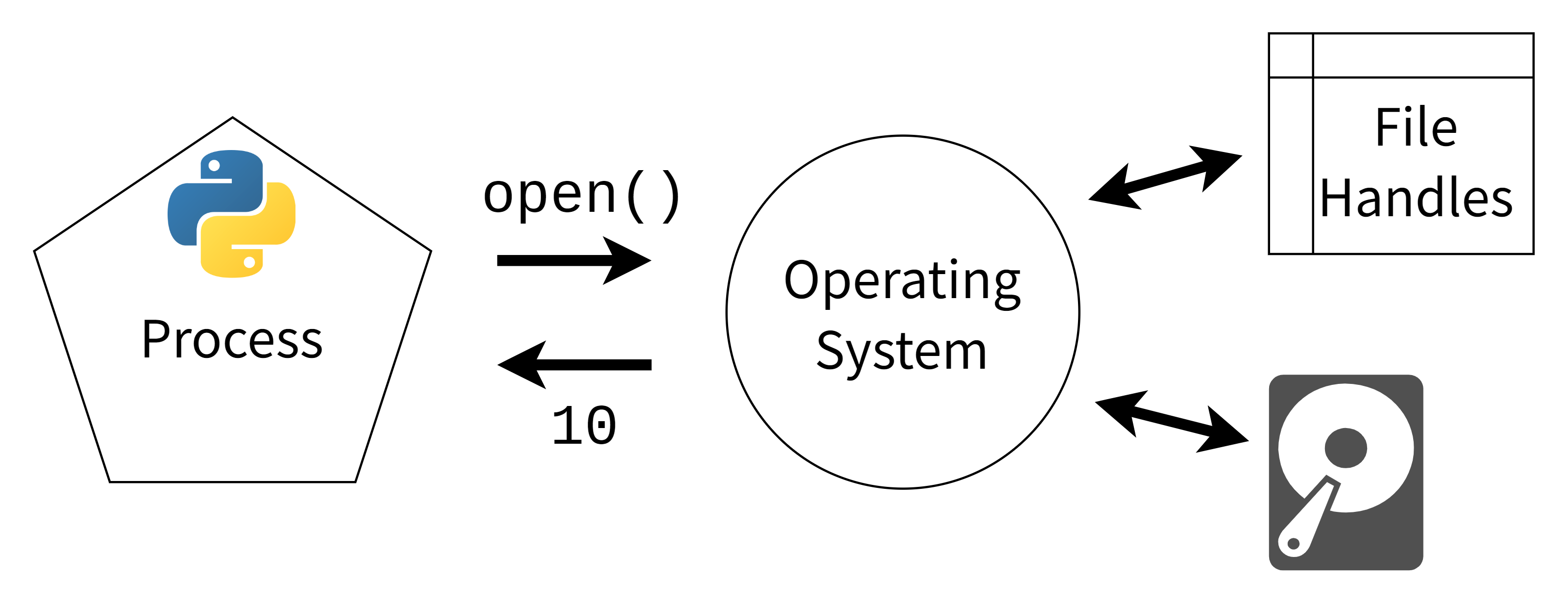
Python rate limit multiprocessing
Python rate limit multiprocessing
Here's the answer:
Python has a built-in library called rate-limits that can help with this problem. Here is an example of how to use it:
import rate_limits
def worker(url):
Simulate some work being done here

time.sleep(1)
if name == 'main':
rl = rate_limits.RateLimit('my_app', 'http://example.com')
for i in range(5):
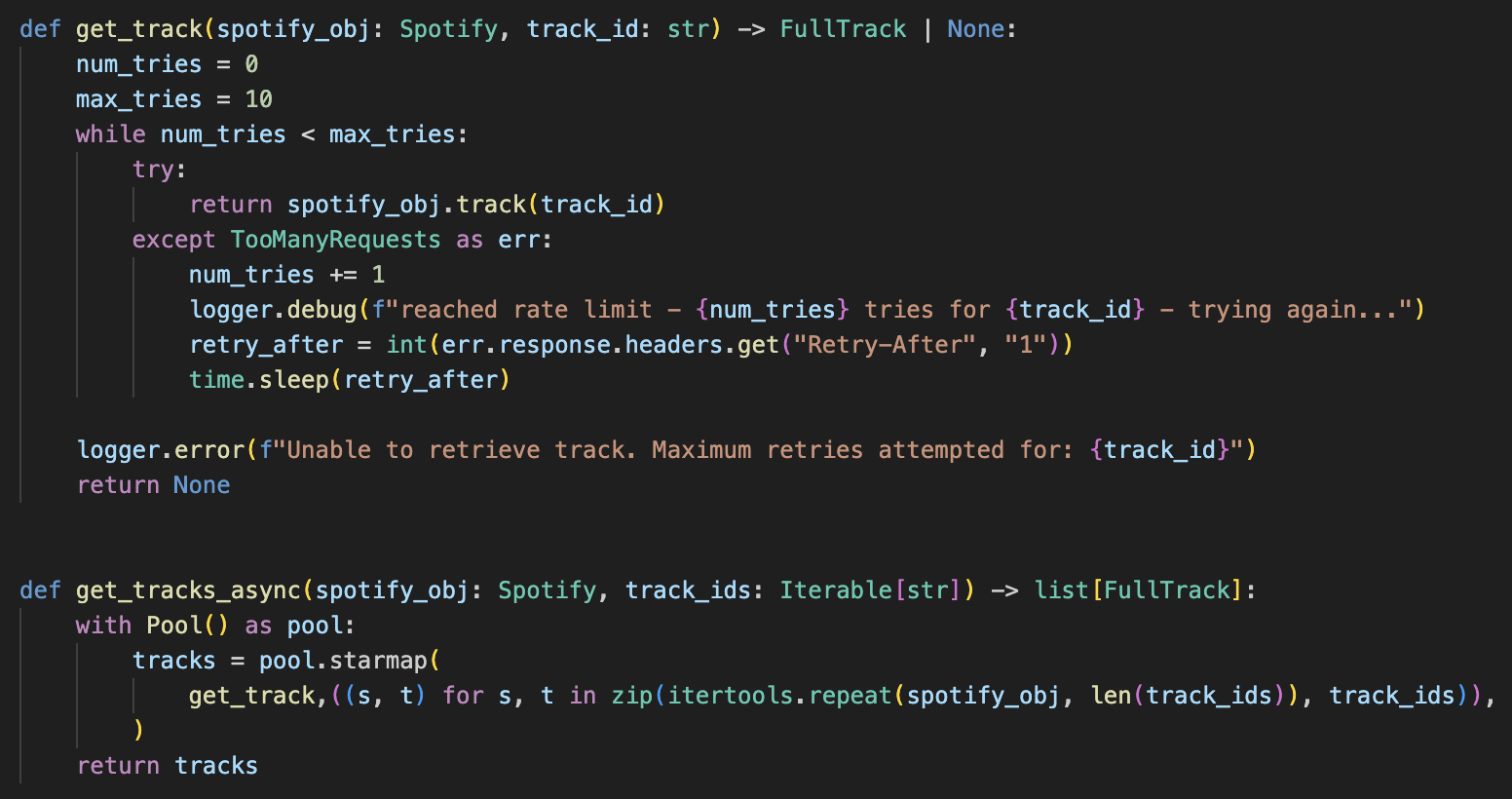
worker(i)
However, rate-limits is no longer maintained and has some limitations. Another option is to use the requests library's built-in rate limiting:
import requests
from functools import wraps
def limit_rate(func):
@wraps(func)
def wrapper(*args, **kwargs):
requests.get('http://example.com') # Simulate a request here
return func(*args, **kwargs)
return wrapper
@limit_rate
def worker(url):
Simulate some work being done here
time.sleep(1)
if name == 'main':
for i in range(5):
worker(i)
As you can see from the above examples, Python does have libraries and tools to help with rate limiting. However, they are not as powerful or comprehensive as some other languages. Therefore, if your application requires fine-grained control over rates and concurrent access, it might be a good idea to use a separate library like celery for this.
Here is an example of how to use celery to achieve rate limiting:
from celery import shared_task
@shared_task(rate_limit='1/s')
def worker(url):
Simulate some work being done here
time.sleep(1)
if name == 'main':
for i in range(5):
worker(i)
This is because Python does not have a built-in rate limiting library that can be used with multiprocessing. Therefore, you will need to use either celery or another separate library.
In the example above, @shared_task(rate_limit='1/s') means one request per second (it may take some time to complete). So if we make more than one request in a second, celery will hold them in its queue until the first one completes.
Python api rate limiting github
I'm happy to help!
Python API Rate Limiting on GitHub
As developers, we often interact with APIs to fetch data or perform specific tasks. GitHub, being a popular platform for version control and collaboration, offers several APIs that enable us to access its vast repository of data. However, due to security concerns and server load management, GitHub implements rate limiting on its APIs.
What is Rate Limiting?
Rate limiting is a mechanism that regulates the frequency at which requests can be made to an API within a specific time window. This helps prevent abuse, spamming, or overloading of servers. In other words, it prevents malicious actors from making excessive requests to exhaust server resources or disrupt normal usage.
How Does Rate Limiting Work on GitHub?
When you interact with GitHub APIs (e.g., using Python's requests library), your IP address is tracked, and the API checks the rate at which requests are being made. If the request frequency exceeds the allowed limit, you'll receive an error response or be temporarily blocked.
GitHub uses a sliding window approach to enforce rate limiting:
Request Quota: Each GitHub user has a quota for the number of requests they can make within a specific time frame (e.g., 5000 requests per hour). Rate Limiting Window: The time window is divided into smaller intervals (e.g., 10 minutes). Within each interval, you're allowed a certain number of requests. Error Response: If your request frequency exceeds the quota or rate limit within an interval, GitHub returns an error response (e.g.,403 Forbidden). Temporary Block: In extreme cases, you might be temporarily blocked from making further requests for a short duration.
Python API Rate Limiting Library
To work around rate limiting when using Python APIs with GitHub, consider implementing the following strategies:
Use caching libraries likerequests-cache to reduce the number of requests made. Implement exponential backoff: When encountering an error response due to rate limiting, pause your script for a short duration before retrying the request. Use pagination and limit the number of requests: Instead of fetching all data at once, use pagination (e.g., GET /repos/{owner}/{repo}/issues?state=open&per_page=100) and set a reasonable page size.
Some popular Python libraries that can help with API rate limiting include:
requests-cache: A caching library for Python's requests module. ratelimit: A lightweight library to implement exponential backoff and rate limiting. github-api-rate-limiter: A GitHub-specific rate limiter for Python.
Conclusion
When working with GitHub APIs using Python, it is essential to be aware of the rate limiting mechanisms in place. By implementing caching, exponential backoff, or pagination strategies, you can effectively manage requests and avoid errors related to rate limiting. Additionally, consider using dedicated rate limiting libraries to simplify your workflow.
How was that?