What does Gensim do in Python?
What does Gensim do in Python?
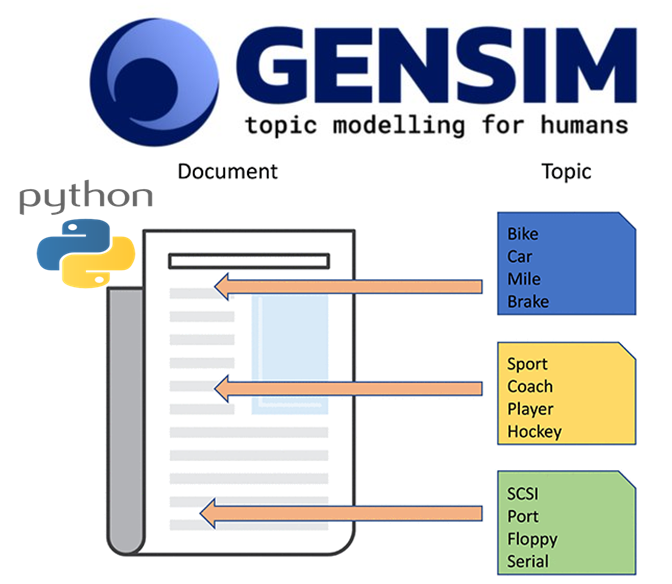
Gensim is a Python library for building topic models and performing document similarity analysis. It is designed to provide high performance, scalability, and flexibility when handling large volumes of text data.
At its core, Gensim provides a simple way to create topic models using Latent Dirichlet Allocation (LDA), Hierarchical Dirichlet Process (HDP), and Latent Semantic Analysis (LSA) techniques. Topic modeling is a popular technique in natural language processing that allows you to identify hidden themes or topics within a large corpus of text data.
Here are some key features of Gensim:
High-performance topic modeling: Gensim's algorithms are optimized for performance, allowing you to quickly process large datasets and generate topic models. Document similarity analysis: Gensim provides tools for analyzing the semantic similarity between documents, which can help with tasks such as clustering, classification, and recommendation systems.

Some common use cases for Gensim include:
Sentiment analysis: Use Gensim to analyze customer feedback or sentiment data from social media platforms, review websites, or other sources. Topic modeling: Apply topic modeling techniques to large datasets of text, such as news articles, blog posts, or social media updates. Document clustering: Group similar documents together based on their semantic similarity using Gensim's document similarity analysis tools. Information retrieval: Use Gensim's indexing and querying capabilities to search and retrieve relevant documents from a large corpus of text data.Gensim has many benefits, including:
Improved accuracy: Gensim's algorithms are designed for high-performance processing, which can lead to more accurate results when working with large datasets. Increased efficiency: With Gensim, you can quickly generate topic models and analyze document similarity, making it a valuable tool for data-driven decision-making. Flexibility: Gensim supports a range of data formats and allows customization of topic models, making it easy to adapt to changing requirements and datasets.Overall, Gensim is an excellent Python library for natural language processing tasks that require topic modeling and document similarity analysis. Its high-performance capabilities, flexibility, and customizability make it a powerful tool in the data science arsenal.
Python gensim tutorial

I'd be happy to provide a detailed tutorial on using Gensim for natural language processing (NLP) tasks in Python!
What is Gensim?

Gensim (Generative Syntax-based Information Model) is an open-source Python library for topic modeling and document similarity analysis. It allows you to perform various NLP tasks, such as:
Topic Modeling: Identify the underlying topics or themes in a large corpus of text data. Document Similarity Analysis: Measure the similarity between two documents based on their content.Prerequisites
Before we dive into the tutorial, make sure you have Python 3.x installed and familiar with basic Python concepts.
Step 1: Installing Gensim
To install Gensim, use pip:
pip install gensim
Step 2: Preparing the Data
For this tutorial, we'll use a sample corpus of text files (e.g., .txt or .md) stored in a directory. Create a new directory for your project and add your text files to it.
Next, create a Python script (e.g., gensim_tutorial.py) with the following code:
import osfrom gensim import corpora
Set the path to your corpus directorycorpus_dir = 'path/to/your/corpus/directory'
Create a list of file namesfile_names = [os.path.join(corpus_dir, f) for f in os.listdir(corpus_dir)]
print("Files found:", len(file_names))
Step 3: Preprocessing the Data
Modify the script to preprocess your text data. For example:
Tokenization: Split each text file into individual words (tokens). Stopword removal: Remove common stopwords like "the", "and", etc. Stemming or Lemmatizing: Reduce words to their base form.Here's an updated script:
import osfrom gensim import corpora, utils
from nltk.tokenize import word_tokenize
Set the path to your corpus directorycorpus_dir = 'path/to/your/corpus/directory'
Create a list of file namesfile_names = [os.path.join(corpus_dir, f) for f in os.listdir(corpus_dir)]
print("Files found:", len(file_names))
Initialize an empty list to store preprocessed documentsdocs = []
for filename in file_names:
with open(filename, 'r') as file:
text = file.read()
Tokenize the texttokens = word_tokenize(text.lower())
Remove stop words and punctuationtokens = [t for t in tokens if not utils.is_stop(t) and not t.isalpha()]
Add the preprocessed document to the listdocs.append(tokens)
print("Preprocessed documents:", len(docs))
Step 4: Creating a Corpus
Now that you have your preprocessed data, create a Gensim corpus object:
from gensim import corpora Create a dictionary from the preprocessed documentsdict = corpora.Dictionary(docs)
Convert the list of documents into a Gensim corpuscorpus = [dict.doc2bow(doc) for doc in docs]
Step 5: Training a Topic Model
Choose a topic modeling algorithm (e.g., Latent Dirichlet Allocation (LDA)) and train it on your corpus:
from gensim.models import TfidfModel, LdaModel Create a TF-IDF model to transform the datatfidf_model = TfidfModel(corpus)
Convert the corpus into TF-IDF representationcorpus_tfidf = [tfidf_model[doc] for doc in corpus]
Train an LDA topic model on the TF-IDF corpuslda_model = LdaModel(corpus_tfidf, id2word=dict, passes=15)
Step 6: Analyzing the Results
Use the trained topic model to:
Identify topics: Get a list of the top words for each topic. Compute document similarities: Calculate the similarity between two documents based on their topic distributions.Here's an example code snippet:
# Get the top words for each topictopic_words = [(topic_id, [word for word, score in topics[topic_id]] )
for topic_id in range(lda_model.num_topics)]
print("Topic words:", topic_words)
Compute document similaritiesdocument_similarities = []
for i in range(len(corpus)):
for j in range(i + 1, len(corpus)):
similarity = lda_model.doc_similarity(corpus[i], corpus[j])
document_similarities.append((i, j, similarity))
print("Document similarities:", document_similarities)
That's it! This tutorial has covered the basic steps of using Gensim for topic modeling and document similarity analysis. You can now explore more advanced topics (pun intended!), such as:
Topic evolution: Track changes in topic distributions over time. Document clustering: Group documents based on their topic similarities.Remember to keep your data well-preprocessed, and you'll be amazed at the insights Gensim can uncover!