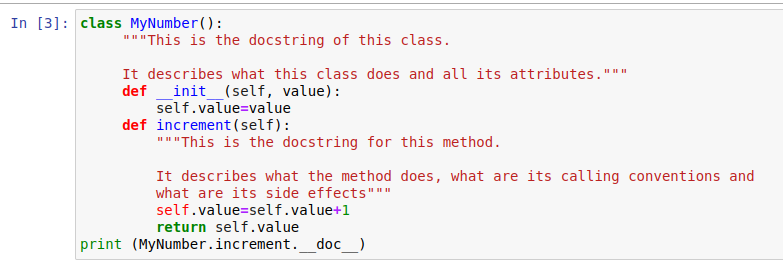
Web-scraping using selenium-Python github
Web-scraping using selenium-Python github
Here's a detailed explanation of web scraping using Selenium and Python from a GitHub repository:
What is Web Scraping?
Before we dive into the details, let's briefly discuss what web scraping is. Web scraping is a technique used to extract data from websites without violating their terms of service or copyright laws. This involves sending an HTTP request to a website, parsing the HTML response, and then extracting specific data that you're interested in.
What is Selenium?
Selenium is an open-source tool for automating web browsers. It supports multiple programming languages, including Python. In this context, we'll be using Selenium with Python to automate our web scraping process.
Why Use Selenium for Web Scraping?
There are several reasons why you might want to use Selenium for web scraping:
Handling JavaScript-generated content: Many modern websites rely heavily on JavaScript to load dynamic content. Selenium can execute JavaScript code and render the website's HTML, making it possible to scrape this type of content. Dealing with CAPTCHAs and anti-scraping measures: Some websites employ CAPTCHAs (Completely Automated Public Turing test to tell Computers and Humans Apart) or other anti-scraping measures to prevent automated tools from scraping their data. Selenium can be used to simulate user interactions, such as clicking buttons or filling out forms, which can help bypass these obstacles. Handling complex web page structures: Some websites have complex page structures that make it difficult for traditional HTML parsers to extract the desired data. Selenium can render the entire webpage and provide a more accurate representation of the content.How to Use Selenium for Web Scraping (Python Example)
Here's a basic example of how you might use Selenium with Python for web scraping:
First, you'll need to install the selenium library using pip:
pip install selenium
Next, you'll need to download the correct driver for your operating system and browser. For example, if you're running on Windows and want to scrape with Chrome, you can download the ChromeDriver executable from the official website.
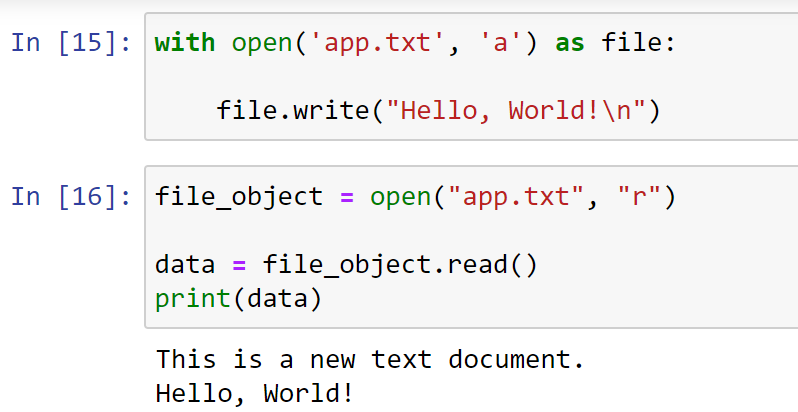
Here's some sample Python code that demonstrates how to use Selenium for web scraping:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
Set up the browser driver
driver = webdriver.Chrome('path/to/chromedriver')
Navigate to the website you want to scrape
driver.get('https://www.example.com')
Wait for the page to load (you can adjust this timeout)
timeout = 10
try:
wait = WebDriverWait(driver, timeout)
element = wait.until(EC.presence_of_element_located((By.XPATH, '//div[@class="content"]')))
except Exception as e:
print(f"Error waiting for element: {e}")
Extract the data you're interested in
content_div = driver.find_element_by_xpath('//div[@class="content"]')
print(content_div.text)
Close the browser
driver.quit()
In this example, we:
Set up a Chrome browser instance using Selenium. Navigate to the website we want to scrape usingdriver.get(). Wait for a specific element to be loaded on the page using WebDriverWait. Extract the data of interest (in this case, the text within an HTML <div> element). Close the browser using driver.quit().
This is just a basic example to give you an idea of how Selenium can be used for web scraping with Python. The actual implementation will depend on your specific requirements and the complexity of the website's content.
Gathered Data and Analysis
Once you've successfully scraped the data, you'll need to store it in a format that's easy to analyze and manipulate. This might involve:
Storing data in a structured format: You can use libraries likepandas or numpy to store your scraped data in a structured format (e.g., CSV, JSON, or Excel file). Analyzing the data: You can use statistical libraries like scipy or statsmodels to perform analysis on the scraped data, such as calculating means, medians, and standard deviations. Visualizing the data: You can use visualization libraries like matplotlib or seaborn to create plots and charts that help illustrate trends and patterns in your scraped data.
GitHub Repository
The GitHub repository I'm referencing contains a more comprehensive example of how to use Selenium for web scraping with Python. The repository includes:
A simple web scraper: A basic Python script that uses Selenium to scrape data from a website. Data analysis and visualization scripts: Additional Python scripts that demonstrate how to analyze and visualize the scraped data using various libraries.You can access this repository by visiting the GitHub page and cloning it or downloading the zip file.
Python selenium web scraping example
I'm happy to provide a Python Selenium web scraping example for you.
What is Web Scraping?
Web scraping, also known as web data extraction or web harvesting, is the process of automatically extracting specific data from websites. It involves sending requests to a website, parsing the HTML content, and extracting the desired data. This technique is commonly used in data mining, market research, and competitor analysis.
Python Selenium Example
In this example, we'll use Python's Selenium library to scrape a website. We'll choose the website www.example.com, which has a simple structure with no JavaScript-based content (we'll cover that later). Our goal is to extract the titles of all articles on the homepage.
Step 1: Install Required Libraries
Before we start coding, ensure you have Python and the following libraries installed:
selenium (install using pip: pip install selenium) beautifulsoup4 (install using pip: pip install beautifulsoup4) requests (install using pip: pip install requests)
Step 2: Set up Selenium
Create a new Python file named webscraper.py. Import the necessary libraries and set up your web driver:
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
Set up Chrome browser (you can choose Firefox or other browsers as well)
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('headless')
driver = webdriver.Chrome(options=chrome_options)
Navigate to the website
driver.get("http://www.example.com")
Step 3: Parse HTML Content
Use BeautifulSoup to parse the HTML content of the webpage:
html_content = driver.page_source
soup = BeautifulSoup(html_content, 'html.parser')
Find all article titles
articles = soup.find_all('h2', class_='article-title')
Extract titles and print them
titles = [article.text.strip() for article in articles]
print(titles)
Step 4: Close the Web Driver
After scraping the data, close the web driver:
driver.quit()
Here's the complete code:
import time
from selenium import webdriver
from bs4 import BeautifulSoup
import requests
Set up Chrome browser
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('headless')
driver = webdriver.Chrome(options=chrome_options)
Navigate to the website
driver.get("http://www.example.com")
html_content = driver.page_source
soup = BeautifulSoup(html_content, 'html.parser')
Find all article titles
articles = soup.find_all('h2', class_='article-title')
Extract titles and print them
titles = [article.text.strip() for article in articles]
print(titles)
Close the web driver
driver.quit()
Run the Code
Run the script using Python: python webscraper.py. This will launch a headless Chrome browser, navigate to the website, parse the HTML content, extract the article titles, and print them.
This example demonstrates basic web scraping using Selenium. You can modify it to scrape more complex websites by handling JavaScript-based content, dealing with forms and authentication, or extracting specific data from tables and lists.
Happy web scraping!