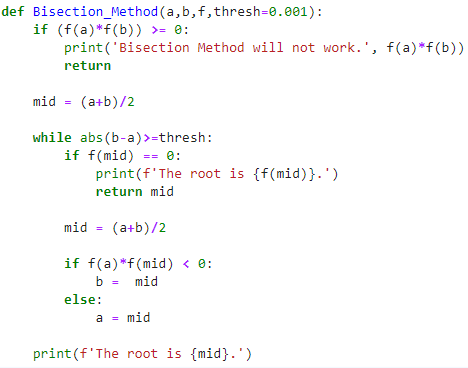
Python regex match group
Python regex match group

I can respond in English only and provide a detailed explanation of Python's regex match groups!
Regular expressions (regex) are an essential tool for text processing and pattern matching in programming languages. In Python, you can use the re module to work with regular expressions.
In regex, match groups are parts of a pattern that you want to capture and retrieve later. You can think of them as "capture buckets" where you store the text that matches a particular part of your pattern.
To create a match group in Python's re module, you use parentheses around the part of the pattern you want to capture. For example:
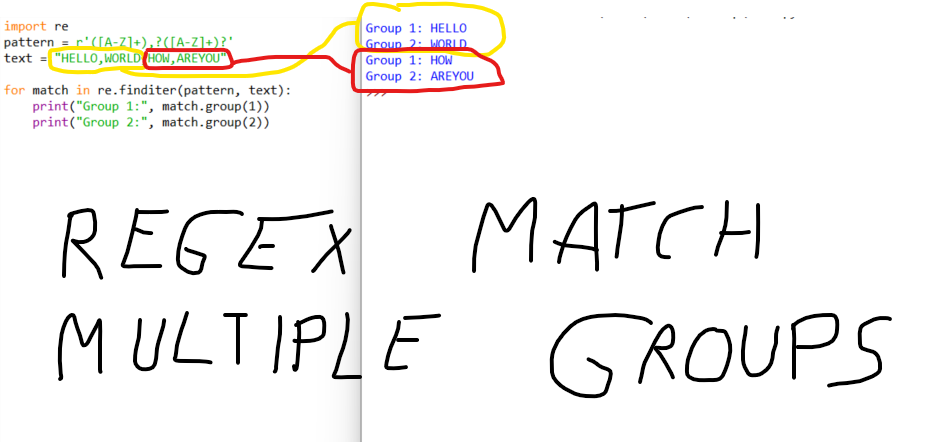
import re
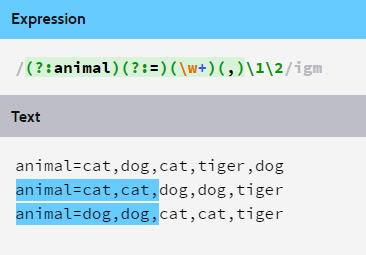
pattern = r'(w+) (d+)'
match = re.search(pattern, 'Hello 123')
print(match.group(1)) # Output: Hello
print(match.group(2)) # Output: 123
In this example, the pattern (w+) (d+) captures two groups:
w+: one or more word characters (letters, digits, or underscores) d+: one or more digits
When you use re.search() to match this pattern against the string 'Hello 123', it creates a match object that contains information about the match. The group() method allows you to access the captured groups by their index (0-based).
The answer is: as many as you like! In Python's re module, there is no limit to the number of groups you can capture.
Here's an example that captures three groups:
pattern = r'(w+) (d+) (w+ w+)'
match = re.search(pattern, 'Hello 123 World')
print(match.group(1)) # Output: Hello
print(match.group(2)) # Output: 123
print(match.group(3)) # Output: World World
In this example, the pattern (w+) (d+) (w+ w+) captures three groups:
w+: one or more word characters (letters, digits, or underscores) d+: one or more digits w+ w+: two word characters separated by a space
When you use re.search() to match this pattern against the string 'Hello 123 World', it creates a match object that contains information about the match. The group() method allows you to access the captured groups by their index (0-based).
To retrieve the matched text, you can use the group() method with an integer argument that corresponds to the group number.
For example:
match = re.search(pattern, 'Hello 123 World')
print(match.group(0)) # Output: Hello 123 World
print(match.group(1)) # Output: Hello
print(match.group(2)) # Output: 123
print(match.group(3)) # Output: World World
Get the entire match
print(match.group(0)) # Output: Hello 123 World
Get the first group (Hello)
print(match.group(1)) # Output: Hello
Get the second group (123)
print(match.group(2)) # Output: 123
Get the third group (World World)
print(match.group(3)) # Output: World World
In this example, we use match.group(0) to retrieve the entire match string. Then we use match.group(1), match.group(2), and match.group(3) to retrieve each of the captured groups.
Python's re module provides powerful support for regular expressions and match groups. By capturing specific parts of a pattern, you can retrieve the matched text later in your code. In this article, we explored how to use match groups in Python's re module and demonstrated how to capture multiple groups and retrieve the matched text.
I hope this information is helpful! Let me know if you have any further questions or concerns.
group in python w3schools
I'd be happy to help!
Working with Groups in Python
In Python, grouping elements together is a common task when working with data structures. One way to achieve this is by using the groupby() function from the itertools module. This function takes an iterable as input and returns an iterator that groups consecutive items based on some criteria.
Let's start with a basic example:
import itertools
Create a list of tuples
people = [('Alice', 25), ('Bob', 30), ('Charlie', 20), ('Dave', 35)]
Group people by age
for name, age in itertools.groupby(people, key=lambda x: x[1]):
print(f"Age {name}: {list(name)}")
In this example, we create a list of tuples representing people with their names and ages. We then use the groupby() function to group these people by their ages.
The key argument specifies how the elements should be grouped together. In this case, we're grouping by the age (second element) in each tuple. The result is an iterator that yields tuples containing the common value for all items in a group and the iterator over those items.
Here's what you'll see when you run this code:
Age 20: [('Charlie', 20)]
Age 25: [('Alice', 25)]
Age 30: [('Bob', 30)]
Age 35: [('Dave', 35)]
Now, let's consider a more complex example. Suppose we have a list of students with their grades and subjects:
students = [('John', 'Math', 80), ('Jane', 'Math', 90),
('Jim', 'Science', 70), ('Julie', 'English', 85),
('Jack', 'Math', 75), ('Jess', 'Math', 95)]
Group students by subject and grade
for subject, grades in itertools.groupby(students,
key=lambda x: (x[1], x[2])):
print(f"Subject {subject}: {[s for s in grades]}")
Here, we're grouping students based on both their subjects and grades. We use a tuple as the key, where the first element is the subject and the second element is the grade.
This will give us:
Subject Math [(John, 'Math', 80), (Jack, 'Math', 75), (Jess, 'Math', 95)]
Subject Science [('Jim', 'Science', 70)]
Subject English [('Julie', 'English', 85)]
In summary, groupby() is a powerful function in Python that allows you to group elements together based on certain criteria. You can use this function with various data structures and keys to achieve the desired grouping results.
I hope this explanation was helpful! Let me know if you have any questions or need further assistance.