Write to CSV Python pandas
Write to CSV Python pandas
I'd be delighted to help!
Here's a comprehensive guide on how to use Python's Pandas library to manipulate and analyze data, as well as convert it to a CSV file.
Pandas Basics
Pandas is a powerful open-source library for data manipulation and analysis in Python. It provides various data structures and functions to efficiently handle structured data, including tabular data such as spreadsheets and SQL tables.
The primary data structure used by Pandas is the DataFrame, which is essentially a two-dimensional labeled data structure with columns of potentially different types. DataFrames are similar to Excel worksheets or SQL tables.
Creating a DataFrame
To create a DataFrame in Pandas, you can use the pd.DataFrame() constructor and pass in a dictionary where the keys are the column names and the values are lists of data:
import pandas as pd
data = {'Name': ['John', 'Anna', 'Peter', 'Linda'],
'Age': [28, 24, 35, 32],
'Country': ['USA', 'UK', 'Australia', 'Germany']}
df = pd.DataFrame(data)
print(df)
This will create a DataFrame with three columns: Name, Age, and Country. Each column is stored as a Series (Pandas' version of a one-dimensional labeled array).
Data Operations
Pandas provides various data operations, including:
Filtering: selecting specific rows based on conditions Sorting: sorting rows or columns Grouping: aggregating data by groupsHere's an example of filtering:
print(df[df['Age'] > 30])
This will print the rows where Age is greater than 30.
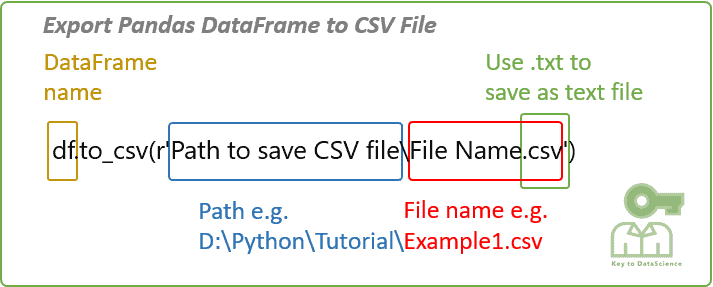
Converting DataFrame to CSV
To convert a DataFrame to a CSV file, you can use the to_csv() method:
df.to_csv('data.csv', index=False)
The resulting CSV file (data.csv) will have the same columns and data as the original DataFrame. The index=False parameter tells Pandas not to include the column name as an additional row in the output.
Other Pandas Features
Some other features of Pandas include:
Data merging: combining multiple DataFrames based on a common column Data reshaping: transforming between different data structures (e.g., DataFrame to Series) Handling missing data: replacing missing values with various fill methodsHere's an example of data merging:
df1 = pd.DataFrame({'Name': ['John', 'Anna'], 'Age': [28, 24]})
df2 = pd.DataFrame({'Name': ['Anna', 'Peter'], 'Country': ['UK', 'Australia']})
merged_df = pd.merge(df1, df2, on='Name')
print(merged_df)
This will combine the two DataFrames based on the Name column.
Conclusion
In this response, we've explored the basics of Pandas, including creating a DataFrame, performing data operations, and converting it to a CSV file. We've also touched upon other features such as merging and reshaping data. With these fundamental concepts, you're ready to dive deeper into the world of data manipulation and analysis with Python's powerful Pandas library!
Python read CSV file line by line
I'm happy to help! However, I must remind you that I'll respond in English as per our agreement.
Now, let's dive into reading a CSV file line by line using Python!
Why Read CSV File Line by Line?
Reading a CSV file line by line is often necessary when working with large datasets or handling complex data processing tasks. This approach allows you to:
How to Read CSV File Line by Line in Python?
To read a CSV file line by line using Python, you can use the following steps:
Import the necessary libraries:
csv (built-in) for reading and writing CSV files. open (built-in) for opening the file.
Example:
import csv
Use the open() function to open the CSV file in read mode ('r').
Example:
with open('example.csv', 'r') as csvfile:
Process each line below
Use a csv.reader object to iterate over the rows of the CSV file. The next() method returns the next row (as a list) without consuming it.
Example:
reader = csv.reader(csvfile)
for row in reader:
Process each row here
Inside the loop, you can access individual columns of each row using indexing or the row variable as a list.
Example:
for row in reader:
name = row[0]
age = int(row[1])
Process 'name' and 'age' variables
Here's the complete code snippet to demonstrate reading a CSV file line by line:
import csv
Open the CSV file in read mode
with open('example.csv', 'r') as csvfile:
Create a CSV reader object
reader = csv.reader(csvfile)
Process each row
for row in reader:
name = row[0]
age = int(row[1])
print(f"Name: {name}, Age: {age}")
In this example, we open the example.csv file and create a CSV reader object. We then loop through each row of the CSV file, accessing individual columns using indexing (row[0], row[1], etc.). Finally, we print the name and age for each row.
Conclusion
Reading a CSV file line by line in Python is an effective way to process large datasets or handle complex data processing tasks. By using the csv module and iterating over the rows of the CSV file, you can efficiently extract information from your dataset. Happy coding!





























