How to install transformers in Python
How to install transformers in Python
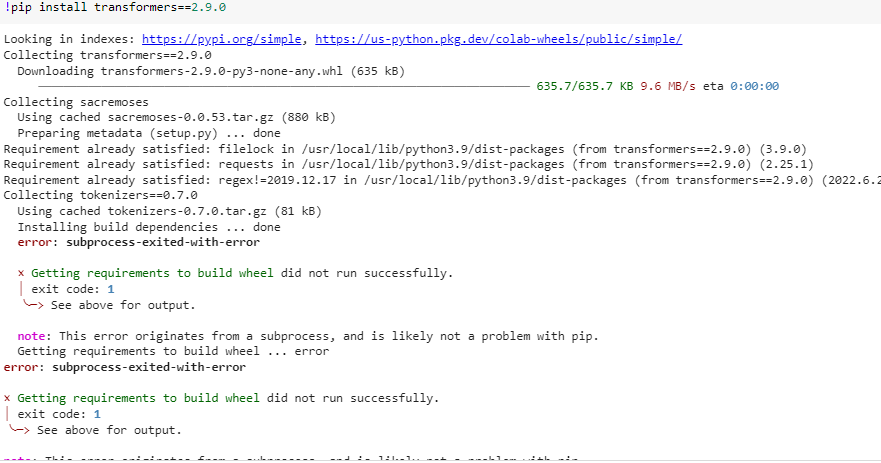
Here is a step-by-step guide on how to install the Transformers library in Python:
Step 1: Install the necessary packages
You'll need to have Python and pip (the package installer) installed on your system. Make sure you're running Python 3.8 or later, as that's when the transformers library became available.
Step 2: Install the transformers library using pip
Open a terminal or command prompt and run the following command:
pip install transformers
This will download and install the transformers library, which includes various pre-trained models like BERT, RoBERTa, XLNet, and more. The installation process should take only a few seconds.
Step 3: Verify the installation
To verify that the transformers library has been installed correctly, you can import it in a Python script or interpreter:
import transformersprint(transformers.version)
This will print the version number of the transformers library. If you see an error message instead, something went wrong during installation.
Step 4: Choose your pre-trained model
Transformers comes with many pre-trained models, each with its strengths and weaknesses. You can choose one that fits your needs based on various factors such as:
Language: English (e.g., BERT, RoBERTa), Spanish (e.g., Beto), French (e.g., CamemBERT) Task: Sentiment analysis (e.g., DistilBERT), Named Entity Recognition (e.g., ERNIE), Question Answering (e.g., Longformer) Computational resources: Larger models like BERT and RoBERTa require more powerful machinesSome popular pre-trained models include:
BERT (Base, Large, XLarge): A multi-task model for various NLP tasks RoBERTa (Base, Large, XLarge): Another popular multi-task model with impressive performance XLNet: A long-range dependence-based model for long-range dependenciesStep 5: Load your chosen pre-trained model
Use the transformers library to load your chosen pre-trained model. For example:
from transformers import BertTokenizer, BertModeltokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretracted('bert-base-uncased')
Step 6: Use the pre-trained model for a specific task
Now you can use the loaded pre-trained model to perform a specific NLP task, such as:
Sentiment analysis Named Entity Recognition (NER) Question Answering Text classificationYou'll need to write code to prepare your input data, run it through the pre-trained model, and then analyze the output. You can refer to various tutorials and examples provided by the transformers library for more information.
That's it! With these steps, you should have the transformers library installed and be ready to start experimenting with various pre-trained models and NLP tasks in Python.
Python transformers pipeline
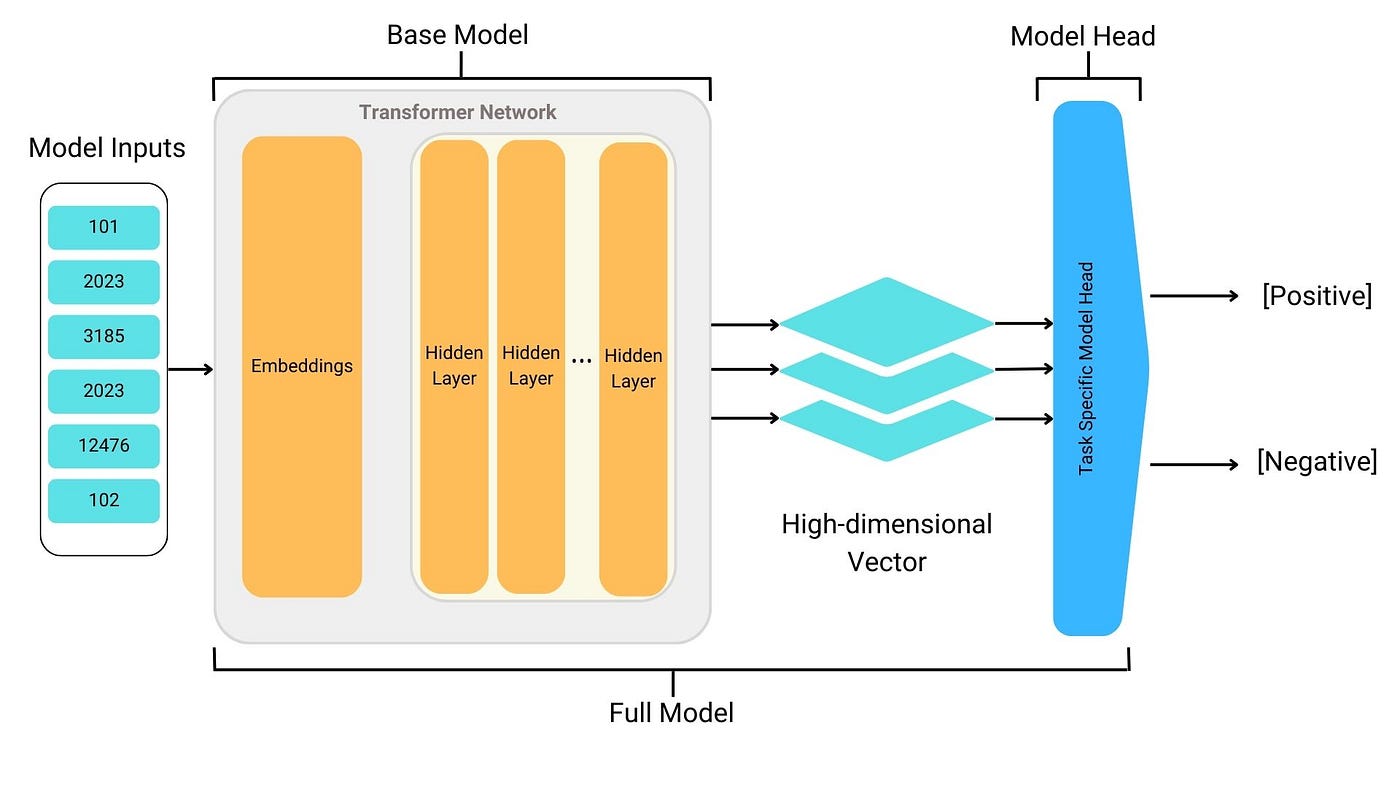
The power of Python and its impressive ability to process natural language with the help of the Transformers library! Let me dive into the details of how you can utilize this incredible tool.
Firstly, what is the Transformers library? The Transformers library, developed by Hugging Face Inc., is a groundbreaking Python library that simplifies and accelerates Natural Language Processing (NLP) research and development. It offers pre-trained language models such as BERT (Bidirectional Encoder Representations from Transformers), RoBERTa (Robustly Optimized BERT Pretraining Approach), and many more, allowing developers to leverage these powerful models for various NLP tasks.
Now, let's dive into the world of pipelines! A pipeline is essentially a sequence of processing stages that take input data as an argument, process it according to your specific needs, and return processed data. In the context of the Transformers library, you can create a custom pipeline by stacking together different components, such as tokenizers, encoders, and decoders.
Here's a basic example of how you might construct a simple pipeline in Python using the Transformers library:
from transformers import pipeline
Define your custom pipeline
nlp_pipeline = pipeline("sentiment-analysis", model="distilbert-base-uncased")
Test the pipeline with some sample text
text_input = "This is an amazing product!"
output = nlp_pipeline(text_input)
print(f"Sentiment analysis: {output[0]['label']}, Score: {output[0]['score']}")
In this example, we're creating a sentiment-analysis pipeline using the DistilBERT (distilled BERT) model. The pipeline function takes in two main arguments: the task name (sentiment-analysis) and the model name (distilbert-base-uncased). The resulting nlp_pipeline object is now ready to process input text and return its sentiment analysis.
Of course, this is just a simple example of what you can do with the Transformers library. Depending on your specific NLP needs, you might want to create more complex pipelines that incorporate additional components like:
Tokenizers: These are used to break down input text into individual tokens (words or characters). Encoders: These take in tokenized data and convert it into a numerical representation that the model can understand. Decoders: These take in encoded data and generate text based on the input. Transformers models: You can choose from various pre-trained transformer-based language models like BERT, RoBERTa, or even your own custom models.The possibilities are endless! With the Transformers library and its pipeline architecture, you can tackle a wide range of NLP tasks, such as text classification, named entity recognition, question answering, and more. So, don't be afraid to experiment, explore, and push the boundaries of what's possible with this powerful tool!