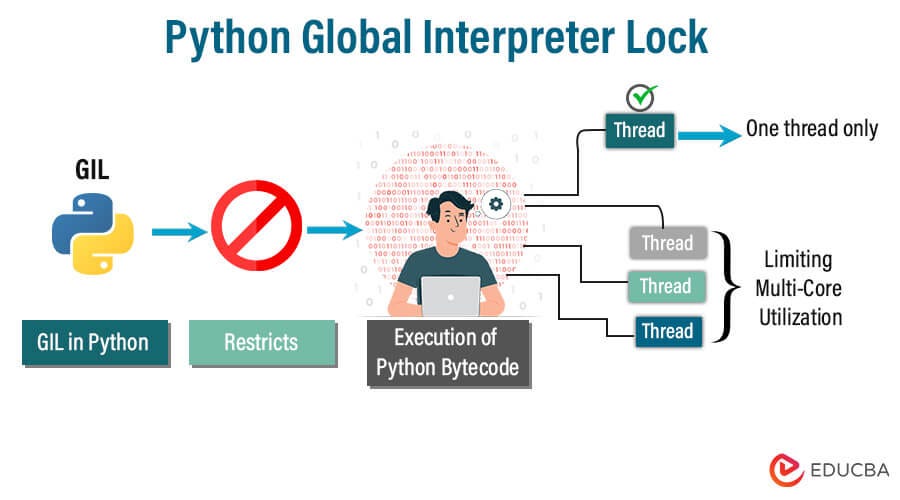
Python data cleaning libraries
Python data cleaning libraries
I'm happy to help!
Python has numerous libraries that can help with data cleaning, which is a crucial step in the data analysis process. Here are some of the most popular and widely used libraries for data cleaning in Python:
Pandas: Pandas is one of the most popular libraries for data manipulation and analysis in Python. It provides efficient data structures and operations for working with structured data (e.g., tabular data such as spreadsheets or relational databases). Pandas has various functions and methods that can help with cleaning, transforming, and analyzing datasets. NumPy: NumPy is the foundation of most scientific computing and numerical analysis in Python. It provides support for large, multi-dimensional arrays and matrices, along with a wide range of high-level mathematical functions to operate on these arrays. This library is often used alongside Pandas for data cleaning tasks that require numerical computations. OpenRefine: OpenRefine is an open-source data refining tool that can be integrated with Python. It provides a powerful set of tools for data cleaning, including data normalization, deduplication, and reconciliation. OpenRefine also has built-in support for various data formats, such as CSV, JSON, and Excel. Dask: Dask is a flexible parallel computing library that can be used to speed up data cleaning tasks in Python. It allows you to process larger-than-memory datasets by breaking them into smaller chunks, processing each chunk independently, and then combining the results. Scikit-learn: Scikit-learn is a machine learning library for Python that includes various algorithms for classification, regression, clustering, and more. While not primarily designed for data cleaning, scikit-learn provides some useful tools for preprocessing and feature engineering, which can be applied to data cleaning tasks.Some of the common data cleaning operations that these libraries can help with include:
Handling missing or null values Removing duplicates or irrelevant data Normalizing data formats (e.g., converting date columns to a standard format) Transforming data (e.g., aggregating data by group or calculating summary statistics) Identifying and correcting errors in the data (e.g., removing rows with invalid data)These libraries can be used individually or together, depending on your specific data cleaning needs. Here's an example of how you might use Pandas and NumPy to clean a dataset:
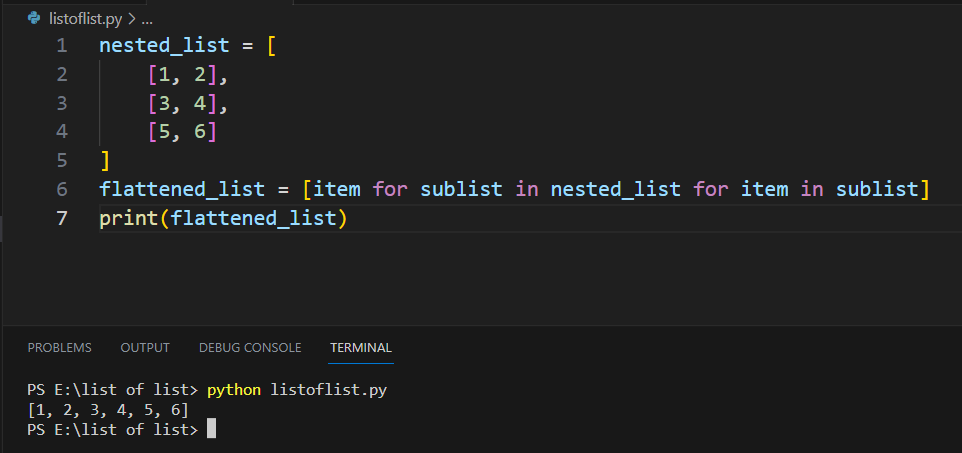
import pandas as pd
import numpy as np
Load the dataset using Pandas
df = pd.read_csv('data.csv')
Remove rows with missing values in certain columns
df.dropna(subset=['column1', 'column2'], inplace=True)
Convert date column to a standard format using NumPy
df['date_column'] = pd.to_datetime(df['date_column']).dt.strftime('%Y-%m-%d')
Group data by category and calculate summary statistics using Pandas
grouped_df = df.groupby('category').agg({'column3': ['min', 'max']})
Save the cleaned dataset to a new CSV file
grouped_df.to_csv('cleaned_data.csv', index=False)
These libraries provide powerful tools for cleaning, transforming, and analyzing data in Python. By combining these libraries with Pandas' data structures and operations, you can efficiently perform complex data cleaning tasks.
Is data cleaning easier in R or Python?

Both R and Python are popular programming languages used extensively for data analysis and data cleaning. The ease of performing data cleaning tasks depends on individual experience, familiarity with the language, and the specific requirements of the task at hand. That being said, here's a general comparison of data cleaning in R and Python:
R:
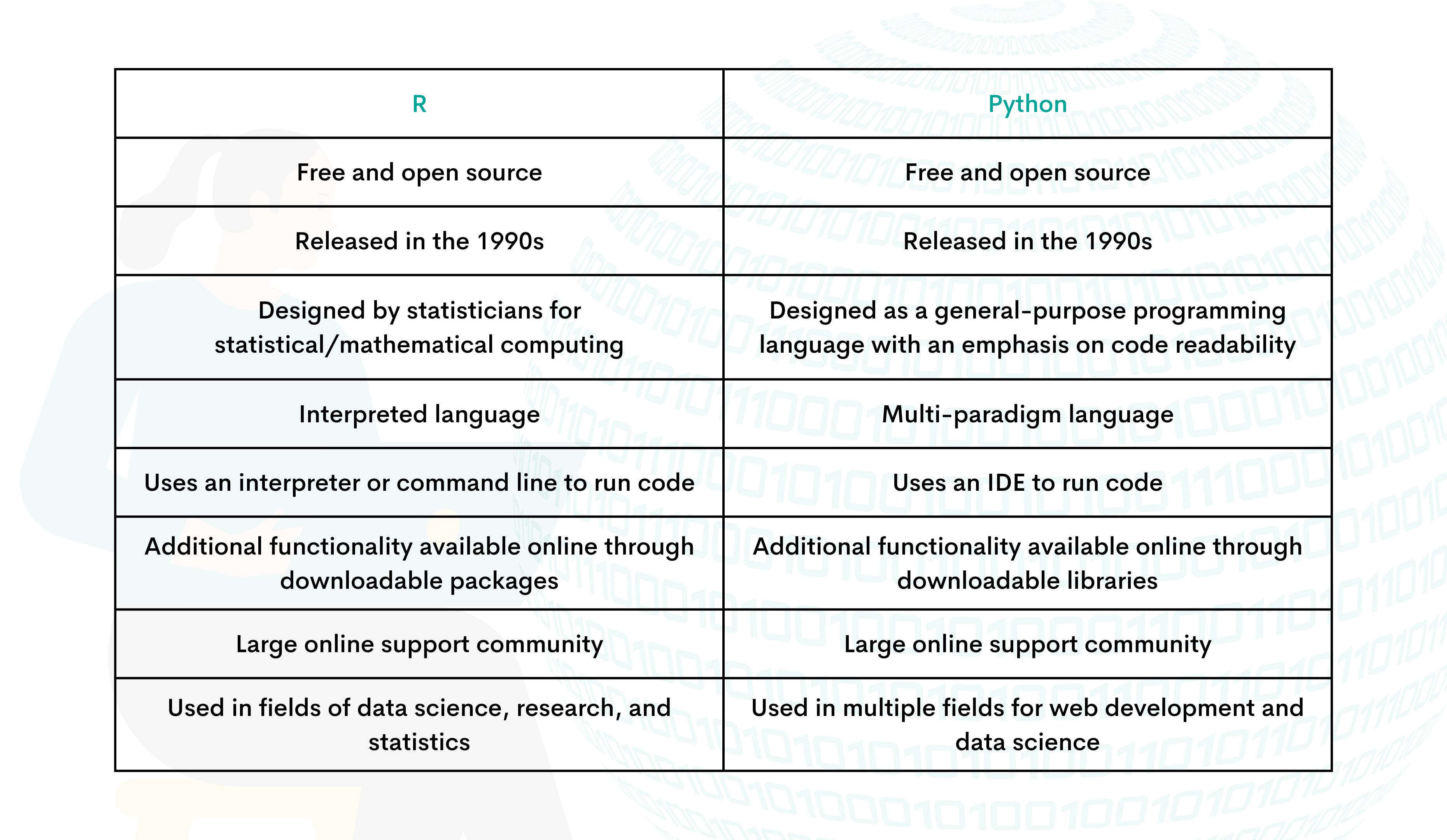
R is a statistical programming language that has built-in functionality for data cleaning. It offers a wide range of packages and libraries, such as readr, dplyr, tidyr, and stringr, which can be used to perform various tasks like data manipulation, transformation, and summarization.
R's syntax for data cleaning is often concise and expressive, making it ideal for tasks that require complex data transformations. For instance, the dplyr package provides a grammar-based framework for data manipulation, allowing you to chain together multiple operations using a pipeline-like syntax. This can be particularly useful when dealing with large datasets or performing repetitive operations.
Additionally, R's readr package offers excellent support for reading and writing various file formats, including CSV, Excel, JSON, and more. The tidyr package is also highly effective in transforming and cleaning data by providing tools like spread() and gather() for reshaping data.
Python:
Python is a general-purpose programming language that has become increasingly popular for data science tasks due to its ease of use, flexibility, and extensive libraries. For data cleaning, Python offers the Pandas library, which provides data structures and functions for efficiently handling structured data (e.g., tabular data).
Pandas offers a wide range of methods for data cleaning, including filtering, sorting, grouping, merging, and reshaping. Its DataFrame structure allows for efficient data manipulation and analysis.
Python also has excellent support for reading and writing various file formats through libraries like Pandas and NumPy. The openpyxl library, for example, can be used to read and write Excel files, while the json and csv modules provide easy-to-use functions for working with JSON and CSV files, respectively.
Comparison:
Both R and Python have their strengths in data cleaning tasks. R's focus on statistical analysis and data visualization makes it an excellent choice when dealing with complex data transformations or advanced statistical techniques.
On the other hand, Python's flexibility and extensive libraries make it a great option for rapid prototyping, data wrangling, and machine learning tasks. Pandas' DataFrame structure provides an efficient way to handle structured data, making it an attractive choice for large-scale data cleaning tasks.
In summary, while both R and Python are capable of performing data cleaning tasks, the ease with which you can accomplish these tasks depends on your familiarity with the language, the specific requirements of your task, and the libraries or packages used. If you're already comfortable with R's syntax and statistical techniques, it might be an excellent choice for complex data transformations. However, if you prefer a more general-purpose programming language with extensive libraries, Python could be a better fit.
Recommendation:
If you're new to both R and Python, I would recommend starting with R due to its strong focus on statistical analysis and data visualization. R provides an excellent foundation for understanding statistical concepts and techniques, which can benefit your overall data science journey.
However, if you're already familiar with programming concepts or have experience with Python, you might find Pandas' DataFrame structure and Python's general-purpose nature more appealing for data cleaning tasks. Ultimately, the choice between R and Python depends on your goals, preferences, and the type of data you work with most often.