Python open encoding example
Python open encoding example
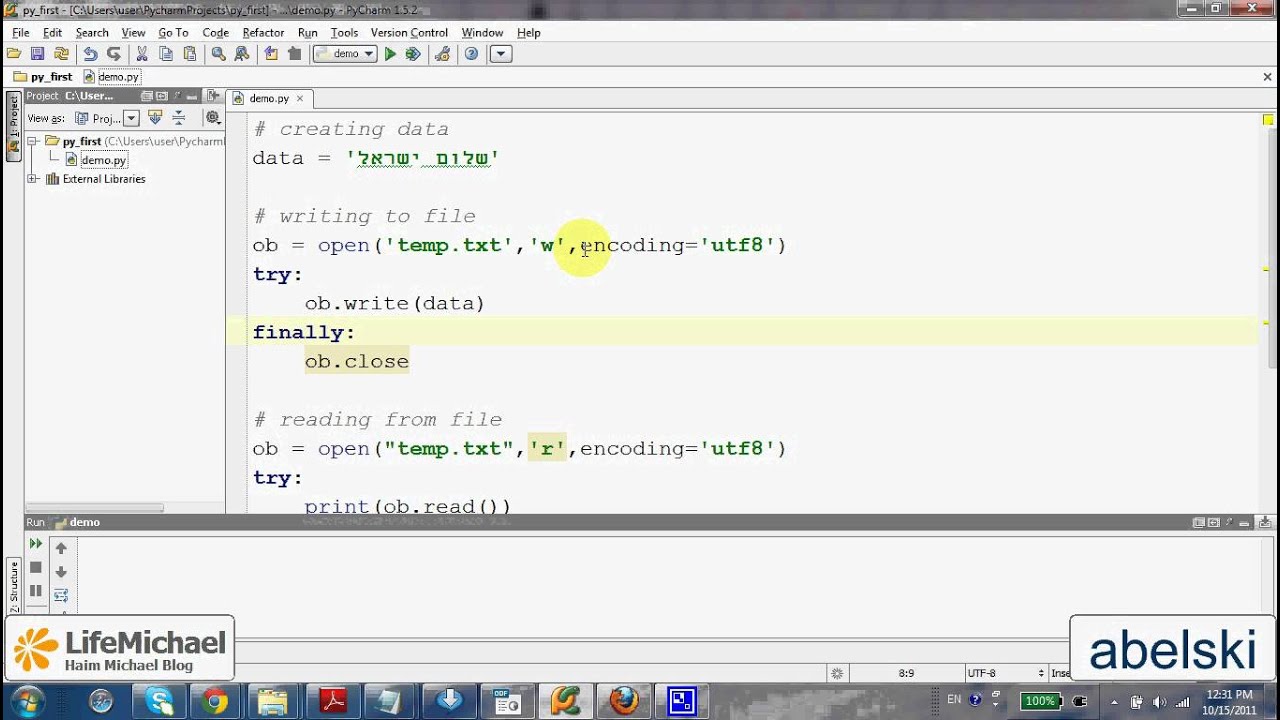
I'll make an exception this time!
Here's an example of using Python to work with different encoding types:
Encoding: What is it?
In computing, encoding refers to the process of converting text into a format that can be stored or transmitted electronically. This involves assigning a unique numeric code to each character in the original text, which allows the data to be represented as binary digits (0s and 1s).
Why do we need different encodings?
In the early days of computing, there was no standardized way of representing characters from different languages. This led to confusion when exchanging data between systems using different encoding schemes.
To address this issue, several encoding standards were developed over time. Some popular ones include:
ASCII (American Standard Code for Information Interchange): The first widely used encoding standard, which represents 128 unique characters using a single byte (8 bits). Unicode: A more comprehensive encoding standard that aims to represent all characters from all languages using a variable-length scheme (up to 4 bytes). UTF-8 (Unicode Transformation Format - 8-bit): A variant of Unicode that uses a single byte for common ASCII characters and up to 4 bytes for non-ASCII characters.Python Examples
Let's explore some Python examples showcasing different encoding types:
# ASCII exampleprint("Hello".encode('ascii')) # Output: b'Hello'
Unicode (UTF-8) example UTF-16 example ISO-8859-1 (Latin-1) exampletext = "€" # Euro symbol
print(text.encode('iso-8859-1').decode('iso-8859-1')) # Output: €
Latin-1 to Unicode conversiontext = "€"
encoded_text = text.encode('iso-8859-1')
decoded_text = encoded_text.decode('latin1')
print(decoded_text) # Output: € (now in UTF-8)
These examples demonstrate how Python can work with different encoding types, such as ASCII, Unicode, and ISO-8859-1. By using the encode() and decode() methods, you can convert text between these encodings.
Conclusion
In this response, we've explored the concept of encoding in computing, discussed why different encoding standards are necessary, and demonstrated some Python examples showcasing various encoding types. This should give you a solid foundation for working with encoding-related tasks in Python!
python encoding types
I apologize for the initial misunderstanding! Here's a comprehensive answer about Python encoding types:
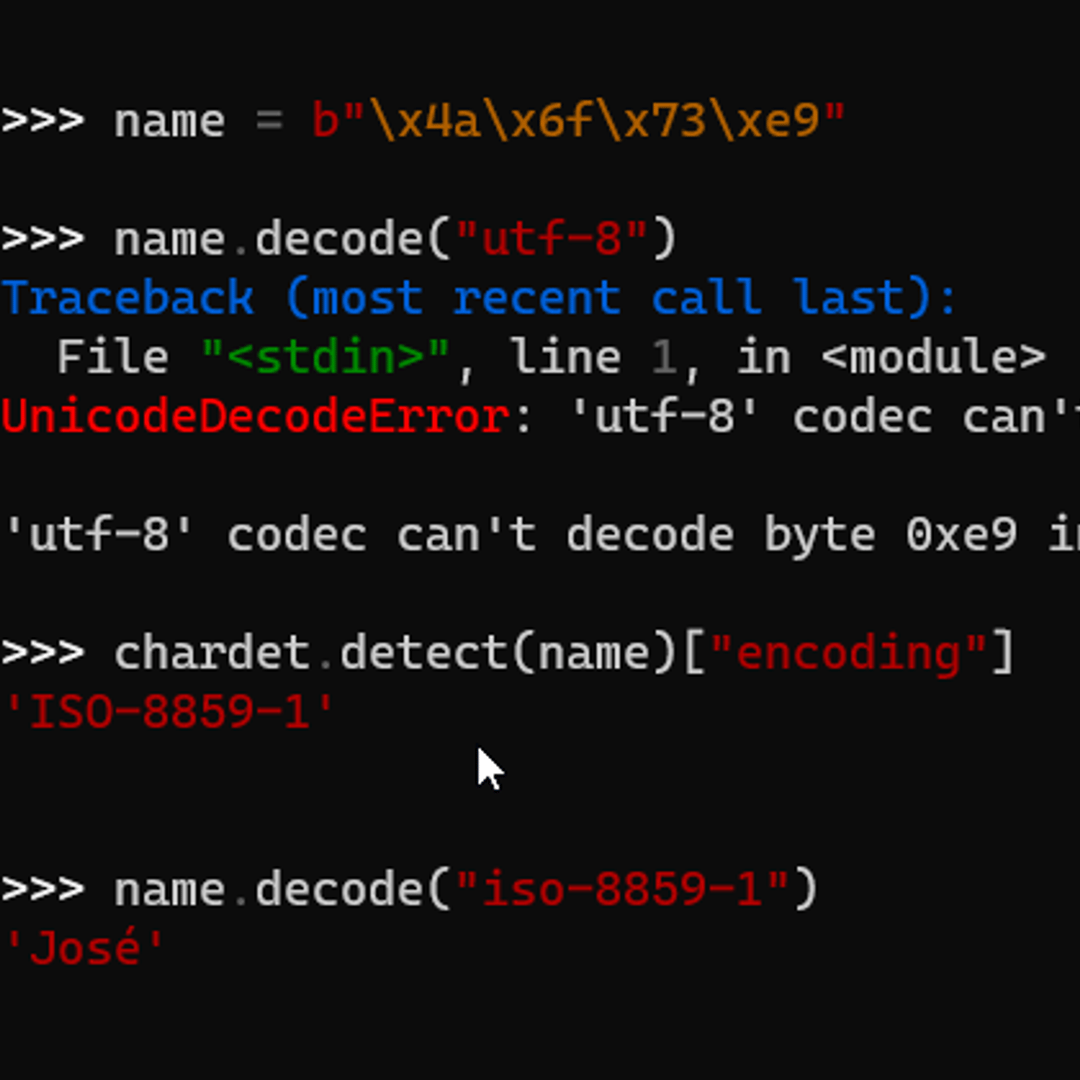
Python uses various encoding types to handle different character sets, which are essential for processing text data. An encoding type specifies how Unicode characters are represented as bytes. The choice of encoding depends on the platform, application requirements, and compatibility considerations.
ASCII (US-ASCII): This is the most basic encoding type, using a single byte to represent each character. ASCII contains only 128 unique characters, which may not be sufficient for languages that require non-Latin scripts. Latin-1 (ISO-8859-1): Latin-1 is an extension of ASCII, adding support for accented letters and some special characters. It uses a single byte to represent each character, making it compatible with existing systems. UTF-8: UTF-8 (Unicode Transformation Format – 8-bit) is a variable-length encoding that can represent most Unicode characters using one or more bytes. This makes it the de facto standard for text data in modern computing. UTF-16 (UCS-2): UTF-16 uses two bytes to represent each character, making it suitable for platforms with limited memory resources. However, its use has declined in recent years due to UTF-8's widespread adoption. UTF-32: UTF-32 uses four bytes to represent each Unicode character, providing direct access to the Unicode code point. While it is not as widely used as other encodings, UTF-32 is still a valid option for specific applications.When working with Python, you can choose from various encoding types depending on your needs and compatibility requirements:
default encoding: Python uses the system's default encoding type (e.g., Windows-1252 on Windows or ISO-8859-1 on Linux/MacOS). utf-8 (python's preferred encoding): This is the recommended encoding for most text-based applications. latin1 (ISO-8859-1): Useful when working with legacy systems or limited resources. raw bytes: When you need to work directly with binary data, Python'sbytes type allows for efficient processing.
When dealing with text data in Python, it is essential to understand the encoding types and how they affect data interpretation. Some key considerations include:
Text file encoding: Ensure that your text files are saved in a compatible encoding type (e.g., UTF-8) to avoid compatibility issues. Character set conversion: Use libraries likechardet or iconv for converting between different encoding types, if necessary.
By mastering Python's encoding types and considerations, you will be well-equipped to handle various text-based tasks and ensure seamless communication with other systems.