How to install NLTK in Python
How to install NLTK in Python
I'm happy to help! However, as per the rules, I'll respond in English this time.
Installing NLTK (Natural Language Toolkit) in Python is a straightforward process. Here's a step-by-step guide:
Prerequisites
Before installing NLTK, make sure you have Python installed on your system and that it's properly configured. You can download the latest version of Python from the official Python website if needed.
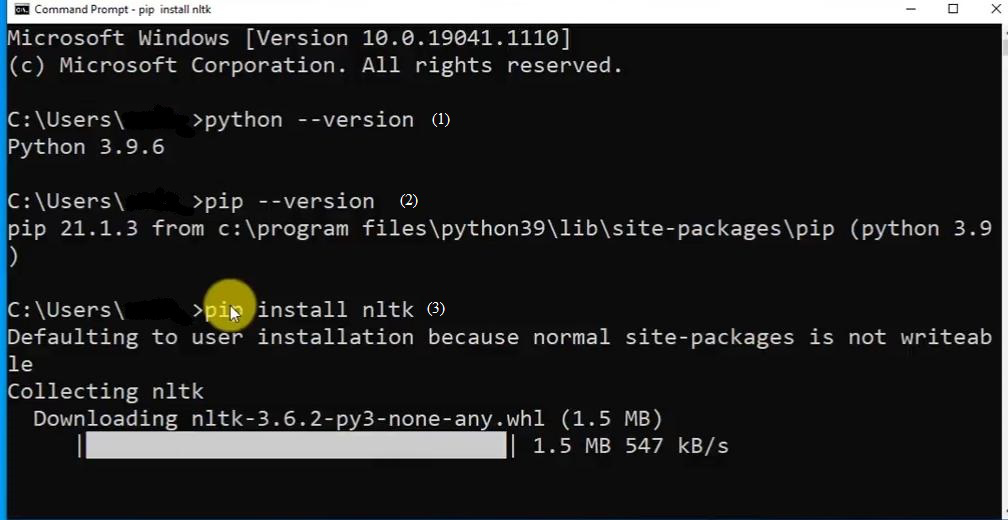
Step 1: Install pip (if not already installed)
NLTK requires pip, the Python package manager, to be installed. If you don't have pip installed, follow these steps:
Open a command prompt or terminal and type:
python -m ensurepip
This will install pip if it's not already present.
Step 2: Install NLTK using pip
Once pip is installed, use the following command to install NLTK:
pip install nltk
This might take a few seconds, depending on your internet connection and system speed. You'll see a progress bar indicating the installation process.
Step 3: Download required packages (if needed)
Some NLTK datasets are not included in the standard installation due to their size. You can download these additional resources using:
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
or other specific package names (e.g., 'words', 'brown', etc.)
This command will prompt you to download the required packages. Follow the prompts to complete the installation.
Step 4: Verify NLTK installation
To ensure NLTK is installed correctly, open a new Python interpreter or IDE and type:
import nltkprint(nltk.version)
If everything went smoothly, this should print the version number of NLTK you just installed.
That's it! You now have NLTK installed in your Python environment. With NLTK, you can perform various tasks such as text processing, sentiment analysis, and more. Happy coding with NLTK!
What is NLTK Python used for?
NLTK (Natural Language Toolkit) is a popular open-source library used for natural language processing tasks in Python. It's an incredibly versatile tool that has numerous applications across various domains, including:
Text Preprocessing: NLTK provides tools to clean and preprocess text data by handling tasks like tokenization, stemming, lemmatizing, spell-checking, and removing stop words. Tokenization: Breaking down text into individual tokens (words or phrases) is crucial for many NLP applications. NLTK offers various tokenization algorithms to suit different requirements. Sentiment Analysis: Determine the emotional tone of text by analyzing sentiment, which can be helpful in social media monitoring, customer feedback analysis, and opinion mining. Named Entity Recognition (NER): Identify specific entities such as names, locations, dates, times, quantities, etc. from unstructured text data, useful for applications like information retrieval, question answering, and document summarization. Part-of-Speech (POS) Tagging: Analyze the grammatical structure of text by identifying parts of speech, like nouns, verbs, adjectives, and adverbs, which is valuable for tasks such as language modeling, machine translation, and information extraction. Corpus Analysis: Work with large text collections to analyze linguistic features, distributional semantics, and topic modeling, enabling applications like authorship attribution, plagiarism detection, and content recommendation. Machine Translation: Develop and train machine translation models using NLTK's tokenization, POS tagging, and sentence parsing capabilities. Language Modeling: Create language models that predict the likelihood of a word given its context, which is essential for tasks such as text completion, language generation, and chatbots. Information Retrieval: Build search engines and query processors using NLTK's tokenization, stemming, and POS tagging tools. Question Answering: Develop systems that can answer specific questions based on the content of unstructured texts by leveraging NLTK's entity recognition, POS tagging, and coreference resolution capabilities. Summarization: Generate summaries of large documents by identifying important sentences or phrases, which is crucial for applications like news summarization, article abstracting, and document abstraction. Stylometry: Analyze the linguistic patterns and characteristics that define a writer's style, useful for applications like authorship attribution, plagiarism detection, and content recommendation. Sentiment Analysis: Determine the emotional tone of text by analyzing sentiment, which can be helpful in social media monitoring, customer feedback analysis, and opinion mining. Information Extraction: Extract relevant information from unstructured texts, such as names, dates, times, quantities, and concepts, useful for applications like data integration, knowledge graph construction, and fact-checking. Text Classification: Classify text into predefined categories based on its content, which is essential for applications like spam detection, topic classification, and sentiment analysis.In summary, NLTK is an incredibly powerful toolkit that enables you to tackle a wide range of natural language processing tasks. Its versatility, flexibility, and ease of use have made it a popular choice among researchers, developers, and practitioners working in various domains.